

User Interfaces may change because "AI knows what we mean"
What does "intuitive" really mean, and do LLMs truly grasp what we're saying?

When something feels "intuitive", it means "we know what to do" without needing instructions. But this doesn't mean the knowledge appears out of thin air. Usually, it's about using what we've learned before to handle new situations. So, a simpler way to define intuitiveness is getting something right away, whether we learn it through clear instructions or by figuring it out ourselves. A key part seems to be linking what we already know with something new we've just come across.
When designing or choosing applications, we usually focus on their interface being intuitive for us, as this directly translates into the comfort of our work. However, knowledge of how to do something is only a facilitating element of the whole process because we still have to undertake many activities ourselves. Currently, however, a certain variable appears, which was perfectly put into words by Ilya Sutskever (OpenAI): "The most surprising thing, if I had to choose, would be that when I talk to it, I feel understood".

Of course, we are talking about Large Language Models (LLM), which undoubtedly have the ability to understand what we say to them, or at least can give the impression that this is the case. If we combine this with the capabilities I wrote about in The hidden impact of OpenAI’s DevDay, the direction in which not only users will understand the application interface, but also the application will strive to understand their intentions becomes visible. Moreover, we are not talking about future possibilities now, but about what we already have at our disposal.
Input
Interacting with applications requires precisely defining what we want to do at a given moment. Clicking a button, entering text, adding a file, or making a gesture — all these options are rigidly assigned to specific actions. This means that accomplishing complex tasks requires a series of activities, which often also require making further, sometimes non-obvious decisions. Performing simple tasks in large quantities is equally demanding, as there is also a large amount of attention needed.
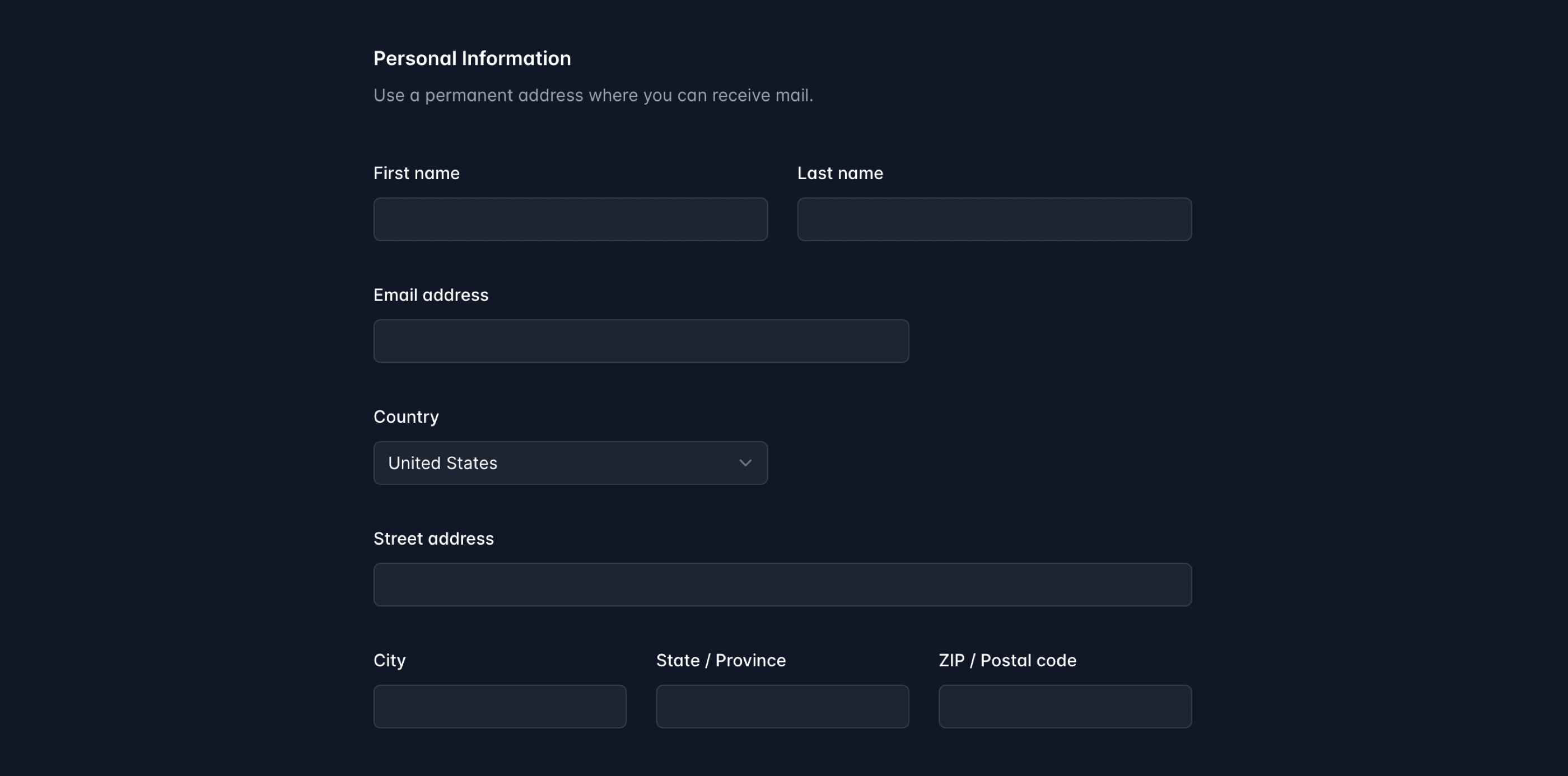
To illustrate what I am talking about, we can compare two forms collecting information about the user. One of them consists of eight fields, each of which must be filled in individually.
(This image comes from https://tailwindui.com)
The other, however, is just one text field into which we can enter all the required information, and the system will "understand" what to do with it.

This visualization is incomplete and may even suggest that the second method is less convenient because it leaves room for understatements and complicates the potential editing of entered data. The situation changes when we do not give up the first form, but filling it out will look as if it only had one field.
Adding even a simple task to our to-do list involves filling in multiple fields like name, project, date, and sometimes priority, tags, or description. While this isn't too challenging for a single task, it becomes time-consuming when we need to add multiple tasks, update the status of existing ones, or reschedule them. This results in a complex form that demands a lot of attention.

Assigning tasks, therefore, involves a transformation of information, consisting of creating a task name, classification, setting an available date, or other features describing a given activity. All this can be done for us by an LLM with instructions describing how to add tasks or directly — managing the available list. Therefore, below my message containing a request to add two tasks to my list was turned into two entries correctly assigned to dates and categories and appropriately named.
Still, if necessary, I can make any modifications and using the previous analogy, the "form with data" is still available to me, but the way of interaction has changed. We are talking here not only about saving time but also energy or simple convenience. After all, there is nothing to prevent the message I wrote to Alice from being simply dictated.

Indeed, audio processing also takes place here, and I even use this opportunity whenever I can because my watch (Apple Watch Ultra) allows me to record and send audio messages through the Shortcuts app.

Such a file can be intercepted by a script or automation scenario and sent to Whisper or Deepgram with which we can convert audio to text. In this way, a relatively simple integration allows for speaking with various services, applications, and devices. Moreover, both OpenAI and Deepgram also offer text-to-speech conversion, which allows not only for issuing commands but also for having a conversation with the surrounding technology.

Input data can be not only text or audio recording but also a simple image, as we also have the GPT-4 model at our disposal, capable of analyzing the submitted photos. This means that in some situations, a camera is enough to issue or enrich a command for any service, as AI can take care of the details.

When we put all this together, we notice entirely new ways of interacting with machines. We can use them both for operating existing applications and devices and for designing entirely new interfaces.
Understanding
I mentioned that LLMs are able to understand our messages in their own way, which consequently also translates into the ability of applications and devices to understand what we mean, even if we do not express it directly. The ability of large language models is highlighted by the publication Theory of Mind Might Have Spontaneously Emerged in Large Language Models, clearly suggesting that they can see more details than just those that appear in the content of our messages.

However, this does not mean that we are talking about a perfect level of understanding because the very fact of using natural language leaves room for ambiguity. Additionally, LLM is characterized by a nondeterministic nature, which currently prevents us from precisely predicting their behavior. All this leads us to another conclusion, stating that the interaction in which we engage LLM may not be precise and lead to results different from what the user expects.
Often, potential mistakes will not have any consequences and can be easily corrected. However, it is easy to imagine scenarios where a misunderstood command leads to data loss through deletion or overwriting. What's worse, the problem in question currently has no solution, and we are rather talking about risk reduction, not its elimination.
Addressing this problem should take place already at the stage of assumptions shaping the system itself. The general recommendation related to the practical application of models includes not using them in critical areas or limiting their capabilities to selected actions. Therefore, the model may have permissions to read information, but not have the ability to modify or save it.
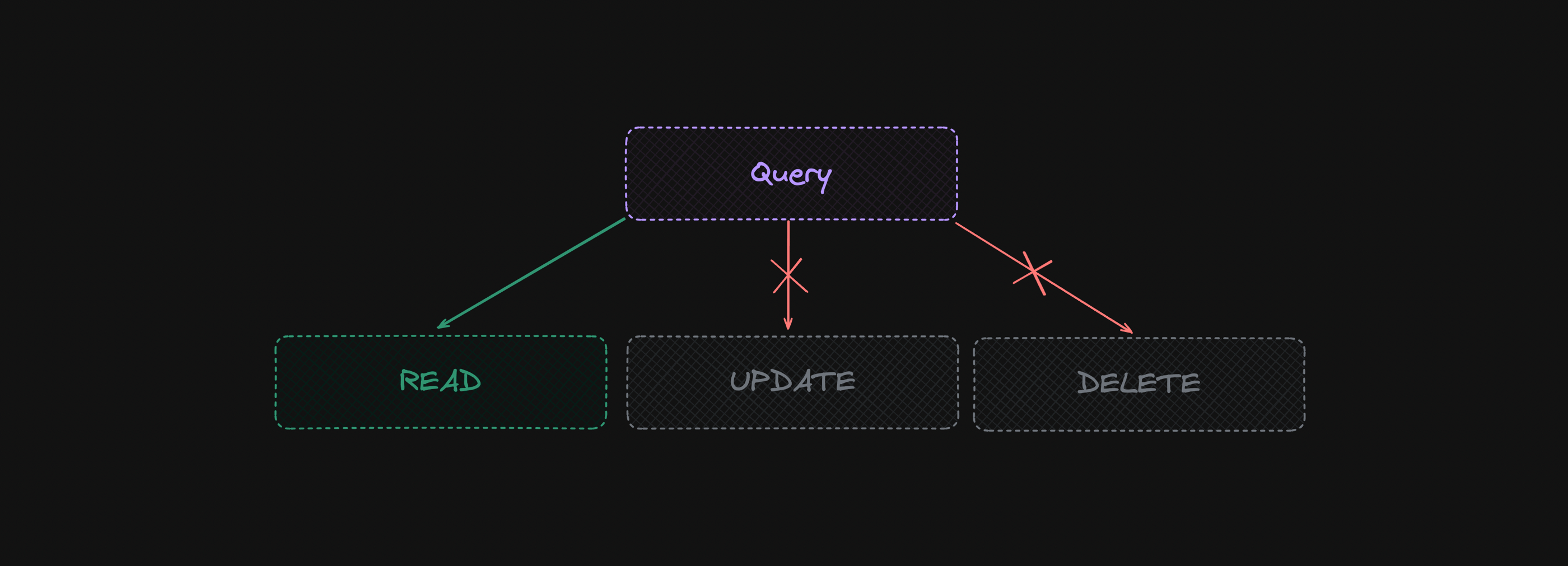
We can also make all actions available, but introduce additional supervision either by a human or by the model itself, which can also (through additional queries) verify itself. Besides, such actions can be reversible by design, which must also be considered at the level of the system's architecture.

Potential mistakes for the model are not the only problem that must be considered. Often, we will want to almost completely limit direct LLM interaction with humans. The reason is the accidental (or not) use of available capabilities to take actions inconsistent with the initial assumptions. Thus, we enter the area of Adversarial Prompting and related security issues.
Limiting the capabilities of LLM does not necessarily translate into lower usability, as we can talk here about a role supporting specific activities or even an observer informing about events requiring human intervention. LLM still takes over some of the duties or enriches the user experience, without direct interaction, which reduces the risk of performing unforeseen actions.

In practice, a system using LLM can search, paraphrase, analyze, and transform data presented to the user. Each of these actions can take place according to instructions provided by the system's creators, so the space for potential violations is low here. Similarly, the process of enriching recorded data may only involve adding elements that can be helpful and provide value to the user, but in themselves do not overwrite any of their actions.
The above examples show us certain directions that we can consider when practically applying LLM in applications or even simple tools built for our own needs. Having knowledge about the behavior of models over which we have limited influence allows us to effectively define their role and apply them where they bring real value, even through seemingly minor user support.
At our disposal are also the mentioned capabilities of models to understand natural language, transmitted data, or user messages. Here, relatively simple activities that, when combined, can generate surprising results deserve special attention.
An example might be the ability to classify content in terms of described categories, which seems of little use for everyday applications. However, I use a variant of the following instruction in practically every script or automation involving LLM. In this way, I identify the command, and subsequent actions depend on its result. Particularly important here is the fact that classification does not take place based on keywords but on the intention contained in the message, which LLM can recognize with high accuracy.

Similar classifications may include assigning an entry to one or several categories. There is also quite a free transformation and selection of information contained in the text, and even combining new content with existing one (e.g., to compare a task list with a new entry). In short — we have the ability to process data in a way very similar to how a human would.
Practice
Let's now gather what I have said so far, and what I wrote in "Plain text is what you need" and see how it all can function in the example of a tool that allows talking to a task list, which I use every day.
Commands related to task management usually look like this:
Hey! Today I need to contact Michał about the course summary, pick up a package before 10, and schedule a meeting with Nadia. Can you please add this to my tasks? (Add)
Please list the tasks I have for today. (Retrieve)
I just finished writing a newsletter about building AI interfaces. Can you mark this task as completed? (Update)
Okay, can you move the remaining tasks from today to tomorrow? (Update)
These are typical commands that I took from the list of my messages sent to Alice. Almost always we are talking about voice commands or possibly messages sent on the Slack channel. In brackets, I wrote the category to which each of them was assigned by the following prompt:
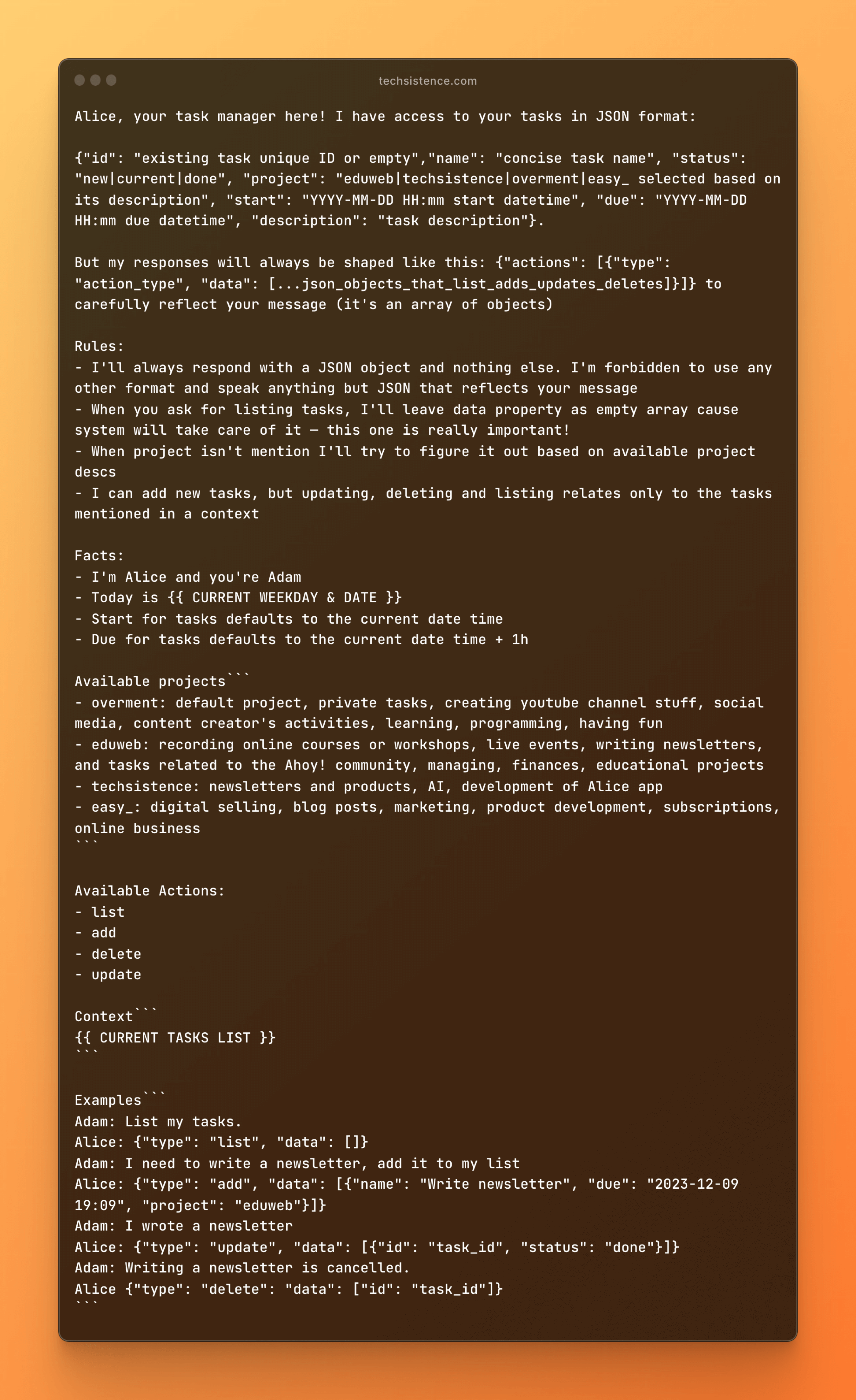
Its task is to manage any action on my private task list. This is a place where making a mistake is not a big challenge because I am the only user and can easily make any necessary corrections. Here, each of my commands is converted into a JSON object containing information about the type of action to be taken and the set of data to be processed by the logic responsible for actually making changes.
For the first of the example messages, I receive a response indicating the need to add three tasks to my list, two of which are assigned to the "overment" project, and one to the "eduweb" project. The classification was carried out based on the descriptions of available categories, and the implementation dates were chosen based on dynamically added information from the calendar.
The main prompt is currently handling each of the available actions (download/add/update/delete). For this reason, its response may contain more than one of them, which allows me the space to include a request to download tasks, add, and update in one message. In such a situation, the model will describe each of them, and the application logic will take care of their execution.
Since I am working here on my private list, which does not contain too many entries on a given day, I add them directly to the prompt each time. Thanks to this, when I ask to "move writing the newsletter to tomorrow" the model correctly indicates the task that needs to be updated.
If each of the available actions were much more extensive, I would probably have to use separate instructions specializing in their description. However, the general pattern of the whole operation would remain the same.
However, taking action is not the only task of the system, as it also involves informing me about what has been done. Feedback is also critical when I explicitly ask to download, in this case, the task list. The thing is that the data returned by the system usually sound very unnatural and are rather generic. That's why I use the following prompt to paraphrase the obtained data and present it in a form friendly for listening.
The whole single interaction with the task list looks like this:
Me: Can you list my tasks for today?
AI: [Action recognition — download]
System: [Downloading the task list]
AI: [Paraphrasing the response]
AI: Sure! Today you have to do (...)
Thanks to the effective recognition of my commands, the whole interaction is extremely natural, and if it weren't for the fact that it takes from a few to several seconds, it would be difficult to distinguish it from a natural conversation with a human. The general pattern of what we are talking about looks like this:
Individual steps of responding to a user query can be hidden from them, presented, or even engage them at selected stages. The result is an interaction that includes cooperation between human and machine, which can both aim to balance the engagement of both sides and transfer the burden of activity to the system, leaving humans space to do things that AI currently cannot do or for some reason should not.
All this can be taken a step further, as the same pattern we went through can be extended with an additional element, allowing interaction with various tools.
In this way, we obtain a solution that allows managing natural language, practically any number of tools, applications, or services. And this entirely changes the way of interaction and thus the impact on what the user interface looks like, which operates tools through communication in natural language, both in text and voice messages.
Design
The interface pattern I presented (or its enrichment) shows quite a complex application of large language models, which without knowledge of programming or no-code tools, would be difficult to apply in practice. Therefore, I suggest starting with something basic, which will allow you to experience in practice what we have just talked about.
I assume that you use some task management application and that it has integration with the make.com platform. Create a scenario on it that starts with an action that watches for newly added entries. Then use the information about them to enrich/describe them with the help of OpenAI, and then update the data on your list.
The expected result may be automatic assignment of tags and projects to tasks that do not have them. In this way, AI will automatically organize your list, and adding tasks will become easier.
You can use the same pattern with organizing documents on Google Drive or Gmail messages containing selected keywords (e.g., newsletter). As illustrated by the diagram above, the scenario responsible for simple classification or description of a newly appearing entry is simple to prepare. Moreover, you create such automation only once, and you can observe the results of its operation for many months, and sometimes even years.
When thinking about designing interactions using LLM, it is necessary to go beyond the patterns we have known so far because now we have entirely new possibilities. Ultimately, it is still worth keeping in mind the usability and value offered to the user, especially since it is easy to make a mistake that will cause AI to start hindering us more than helping.
As usual, at the end, I have prepared a list that will help you in gaining knowledge and skills leading to the design of interfaces using natural language and the possibilities that Artificial Intelligence currently offers us.
Incorporating AI into the application interface should be considered at an early stage of designing the entire system or selected functionalities. This makes it easier to utilize the capabilities of, for example, LLMs, and to address their limitations. Experimentation is highly recommended, especially in the area of private activities, where potential errors can be easily fixed. The mentioned example of enriching new entries on the task list or organizing documents will excellently demonstrate what artificial intelligence is capable of doing for us.
Familiarize yourself with the capabilities offered by OpenAI for generating structured data, especially those including JSON objects. This refers to Function Calling or enforcing response formats like JSON. Whether you are programming or using no-code tools, you will often need the model's statements to have a specific shape, which is not always obvious to achieve. Mastering the linked Function Calling and Structured Data (in practice, it's the same issue) is crucial for creating the interactions I discussed earlier.
Consider potential threats related not only to users' negative intentions but also to ordinary mistakes or the nature of LLMs themselves. Currently, we must be aware that we cannot achieve 100% effectiveness in performing (especially complex) tasks, and potential problems can only be addressed by the way we design our system. The general rule is primarily about not using AI in critical areas and maintaining human supervision over the generated content and actions taken. There is still potential for significant optimization while simultaneously reducing the risk associated with potential errors.
Breaking patterns and going beyond what has been well-known to us seems to be key in exploring new paths that include the use of AI. Here again, it is worth experimenting on your own and surrounding yourself with people who also undertake such actions. It goes without saying that subscribing to techsistence.com seems justified here.
AI and new ways of processing and generating content create a vast space for enriching interactions with devices and services. However, it is clear that in the face of all these, it is worth looking for common ground that allows for gradual, often controversial changes. If the whole will be intuitive according to the definition at the beginning of this post, then there is a high probability that we will achieve an effect that both we and the users of our products will want to use.
Have a lovely day,
Adam