

The hidden impact of OpenAI’s DevDay
Current limitations of LLMs and where are we heading


👋 Hey, Greg & Adam here. Welcome to the #1 edition of Techsistence.
We’ve created different categories for our publications and will experiment with longer and shorter, as well as more tech and business oriented thoughts. All of them are result of our practical application of technology to our projects and startups.
This is the first in the series of techspace 🧑💻, where we dive a little bit more in technology. Apart from it, we’ll have mindspace 🧠 (for more existential thoughts), and workspace 🖥️ (applying theory to practice).
If you find it helpful, please share it with your friends. Enjoy!
Recent updates presented by OpenAI during DevDay showed that this is a company that can deliver on its goals. This also means that AI development is not slowing down, but quite the opposite.
However, not everything is visible at first glance. I mean both new possibilities and challenges that we have to face when using Large Language Models in practice.
To see the full picture, it is necessary to outline a slightly broader context. So let's start with what we knew so far about OpenAI models. To make it easier, I will use simplifications, focusing only on the most crucial threads.
So far, we have clearly distinguished three main models that have been the focus of our attention.
GPT-3.5-Turbo - faster, cheaper, worse
GPT-4 - slower, more expensive, better
Whisper - brilliant for transcription
The effectiveness of these models is high enough that they work well in everyday work. Thanks to the OpenAI API, it is also possible to integrate them directly with application code, which is presented below with a wink.

Indeed, creating an impressive prototype using the OpenAI API is very simple. The situation becomes much more complicated when we want to deliver real value at scale, as obstacles start to appear earlier than it may seem.
However, I will note that we are currently talking about the OpenAI API service, not ChatGPT. Distinguishing between them is important because they are often treated equally, while from the product development point of view, it is the API service that will receive the most attention. On the other hand, it should be noted that in both cases, we are talking about interacting with models from the GPT family, so some of the information in the rest of the post will apply to both services.
Starting our thoughts on applications using large language models from OpenAI, it is worth considering various limits that cover fundamental aspects such as:
length of a single query: for GPT-3.5 / GPT-4 models, it ranges from 4 to 16 thousand tokens (a token is ~ 4 characters in English). Exceeding the limit results in an error, which we will quickly see when trying to process longer content.
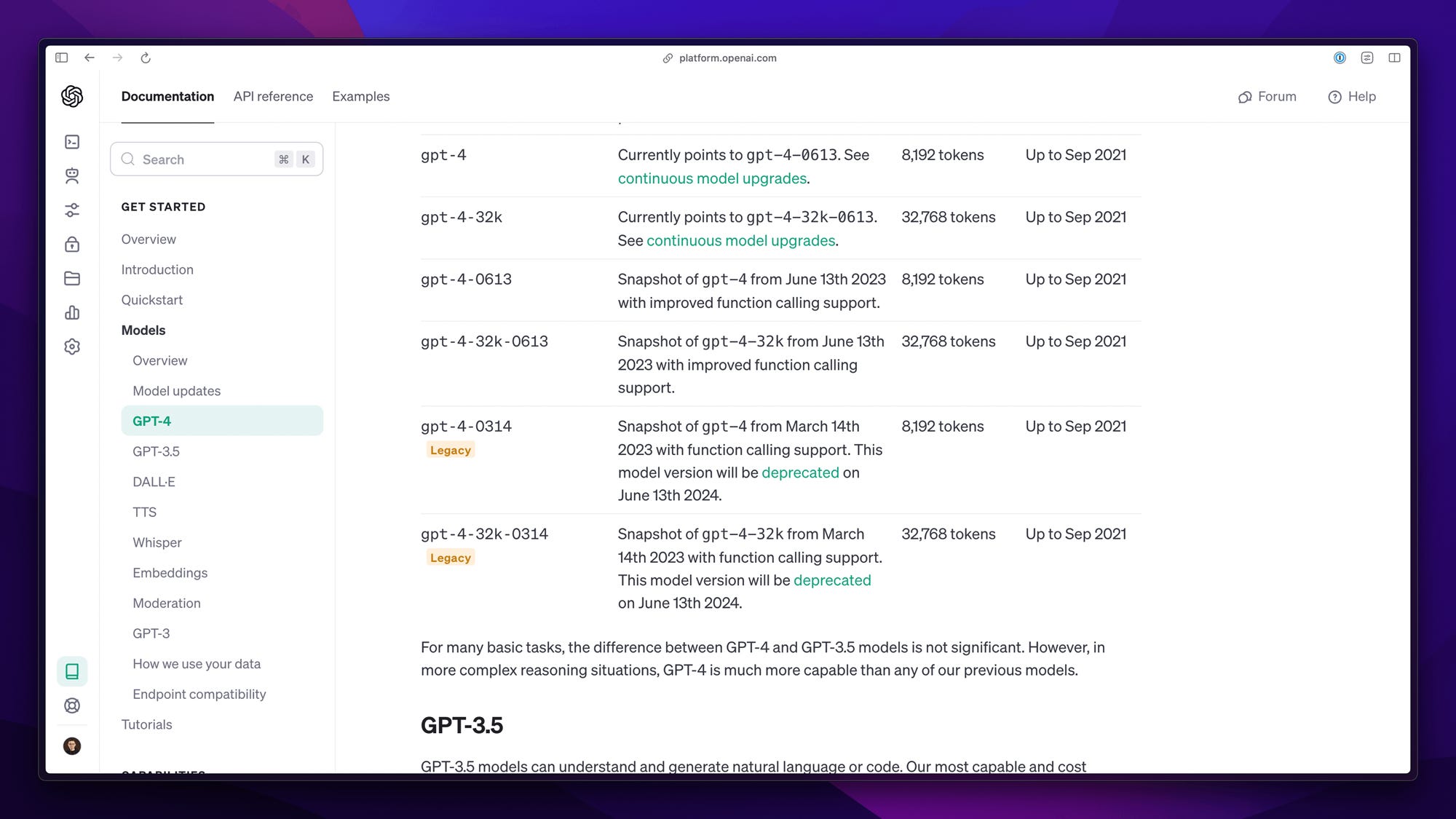
number of queries / tokens per minute / day: this limit covers the entire account and is highly variable. Current values can be seen in the documentation. In private use cases, they usually do not pose a major problem. In production, they often require changes at the level of design decisions or the use of queues or caching (if possible).
steerability: large language models generate content by focusing on the next fragment that fits the preceding content. The complexity of this process means that we can partially influence it, but we cannot control it. The non-deterministic nature of the model also comes into play, causing the result to vary for the same input data. The combination of these elements makes it much more challenging to design applications where the model is responsible for part of the logic that we do not have full control over.
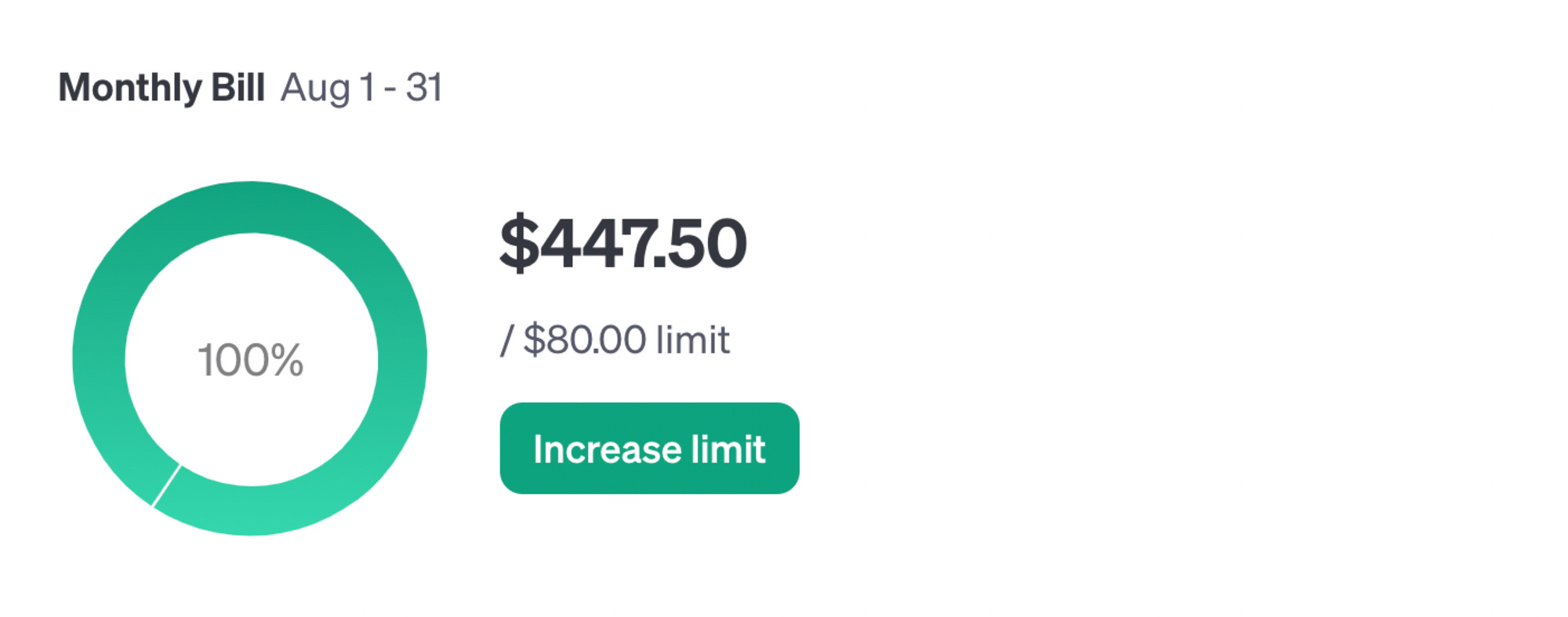
cost scale: a usage-based billing model can be difficult to estimate, and costs can increase rapidly even at relatively low scale. This means that part of our attention must focus on optimizing the application and ensuring that even accidental actions generating significant costs are avoided. Below is a screenshot from my private account to illustrate the potential scale. I use it alone, but in a fairly advanced way.
Regardless of the scenario, these limitations required additional activities, especially when dealing with larger scale or production use cases. And although in many cases it was possible to achieve a satisfactory solution, the result usually did not fully align with the initial assumptions. In extreme cases, we also talked about insufficient stability and effectiveness of the solution to survive the market collision. To some extent, the problems mentioned also resulted from the limitations of the models themselves, often stemming from their nature or architecture. Here are a few examples:
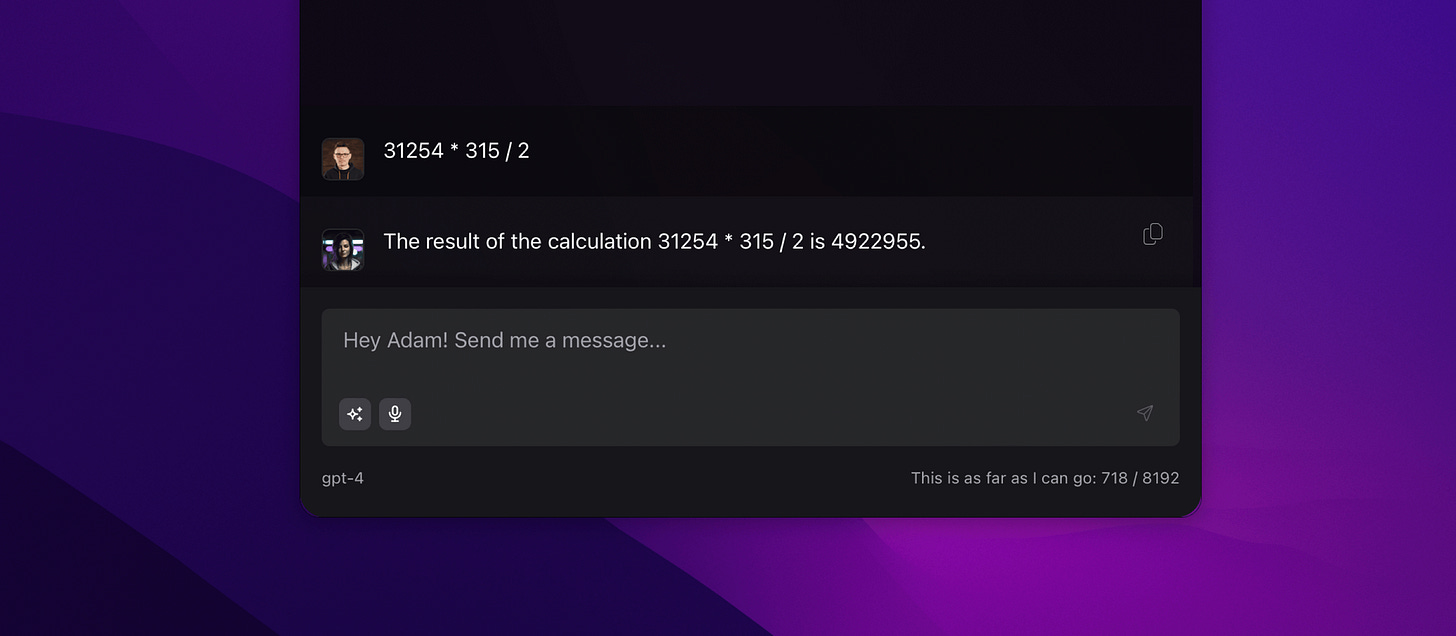
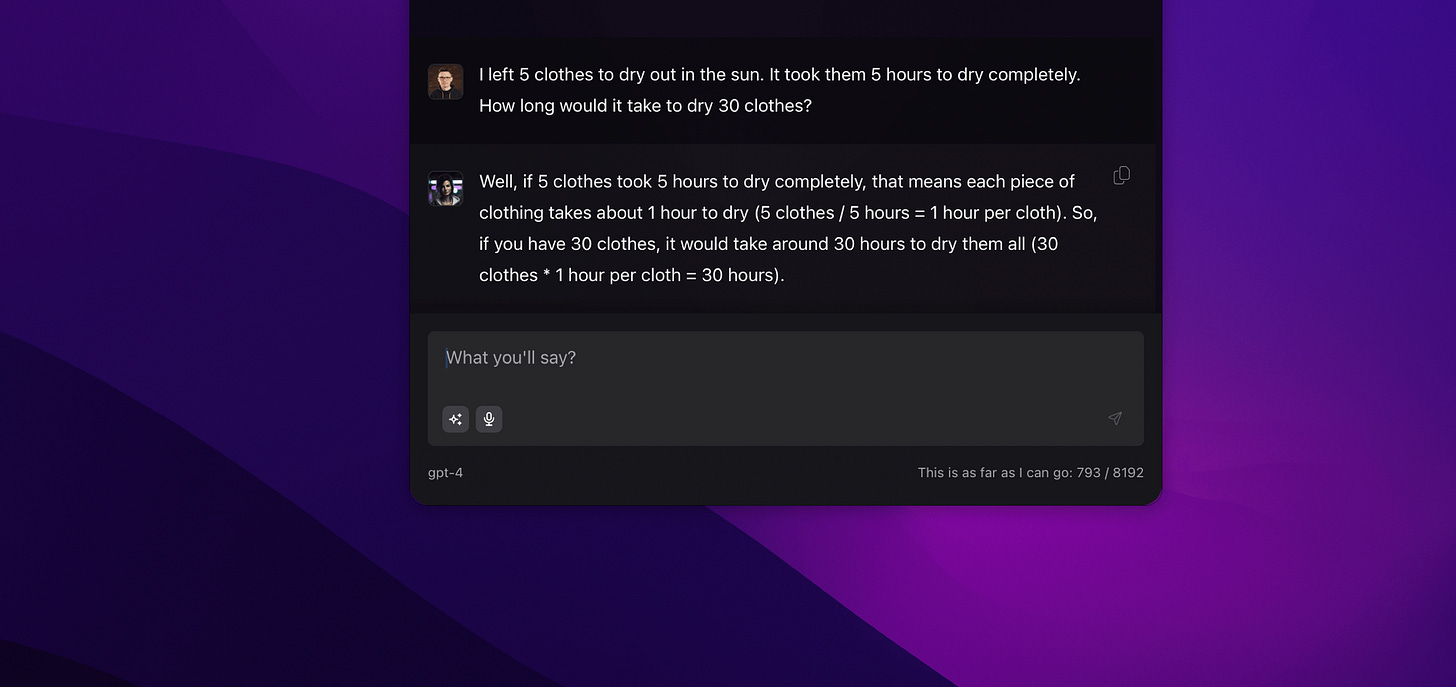
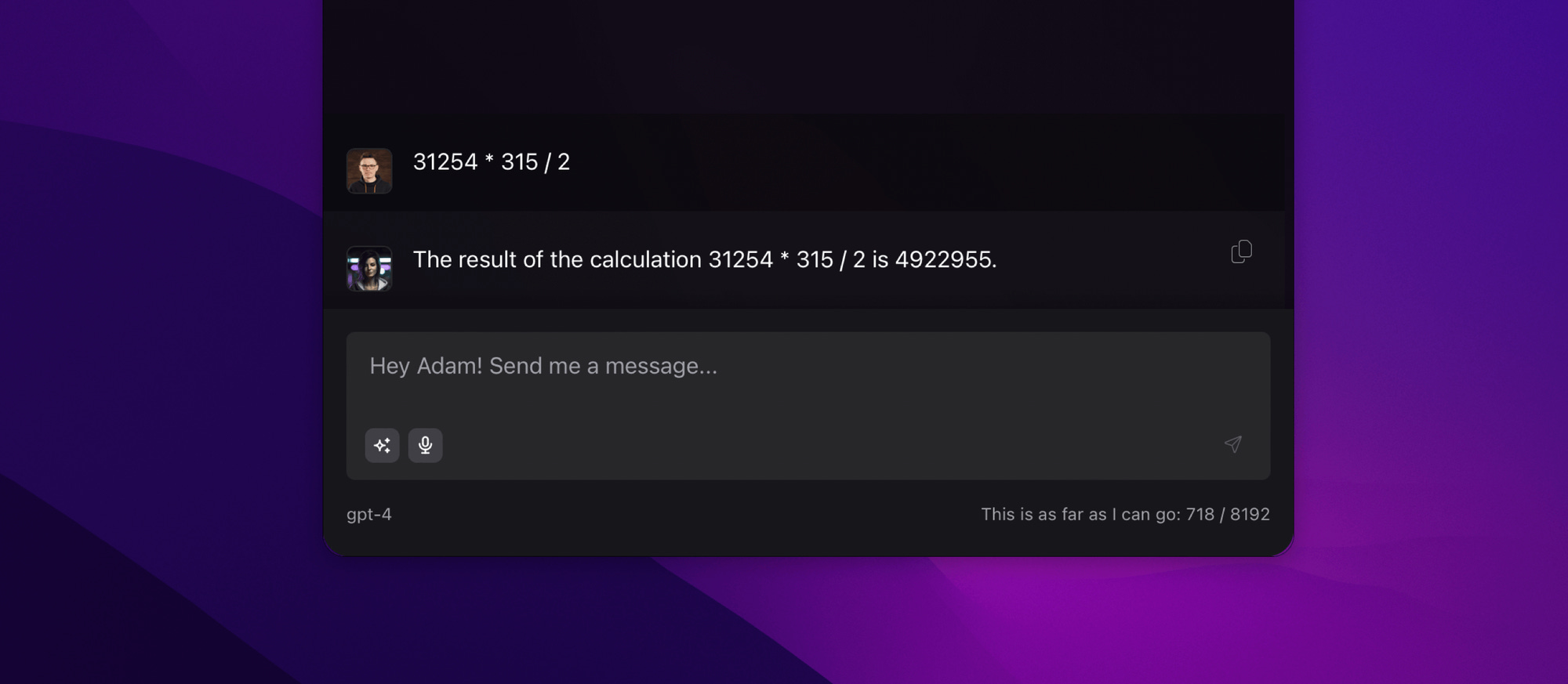
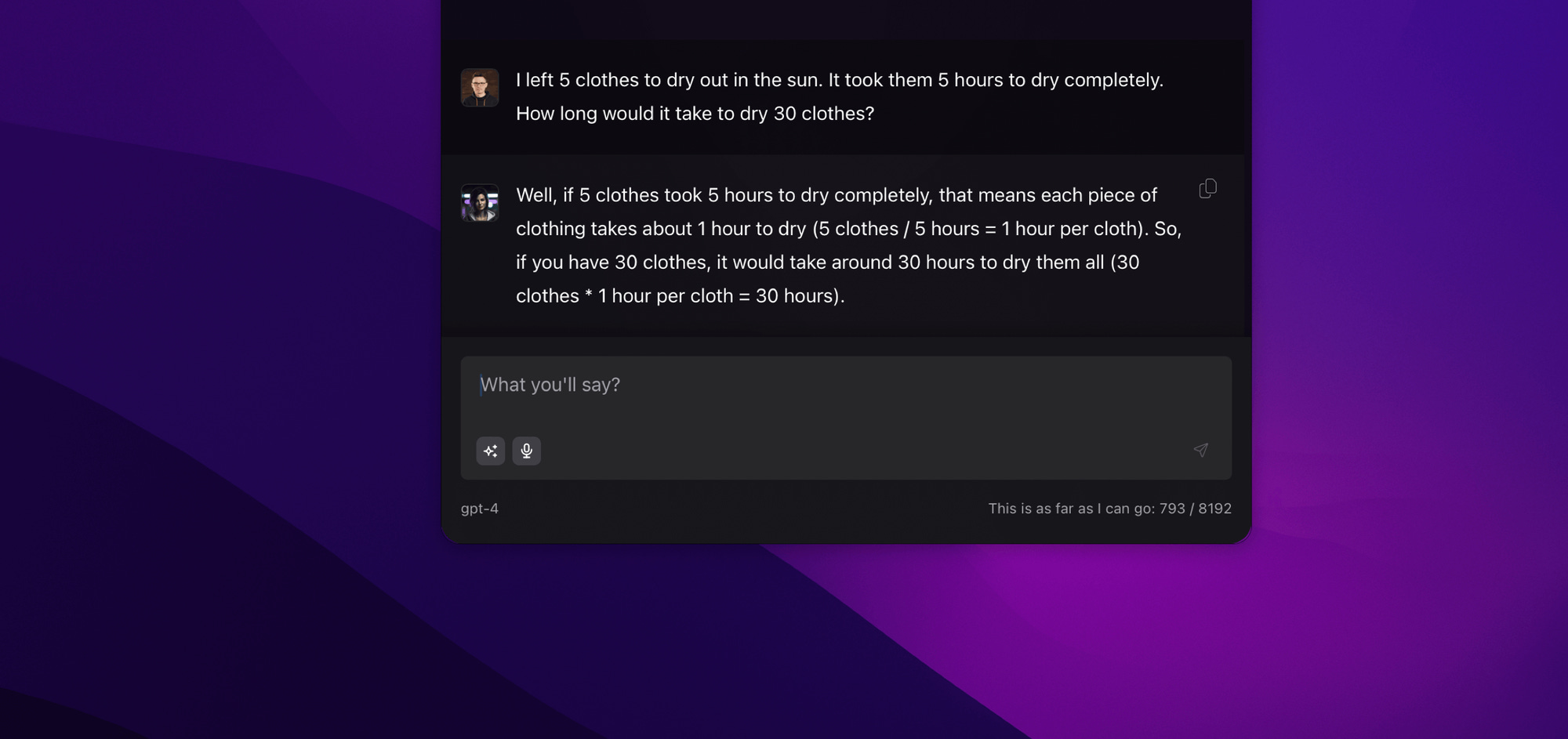
Operations on numbers: Generally, the larger the numbers or the more complex the operations, the harder it is to get the correct answer. It's a bit difficult to expect this from a language model, but we often encounter very glaring issues.
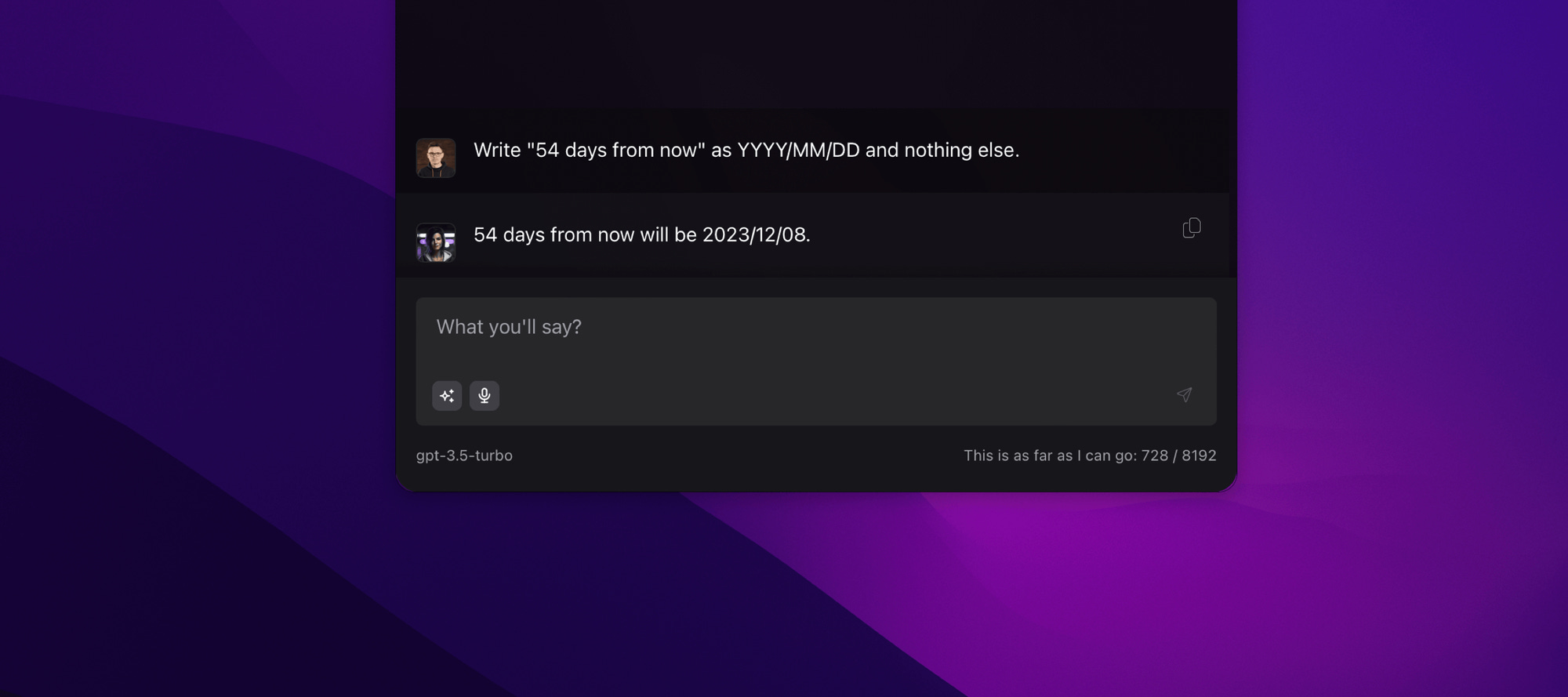
Operations on dates: Again, the further away the date or the more complex the instruction, the easier it is to make mistakes. This is particularly problematic when the model is equipped with tools such as a to-do list, calendar, or CRM system.
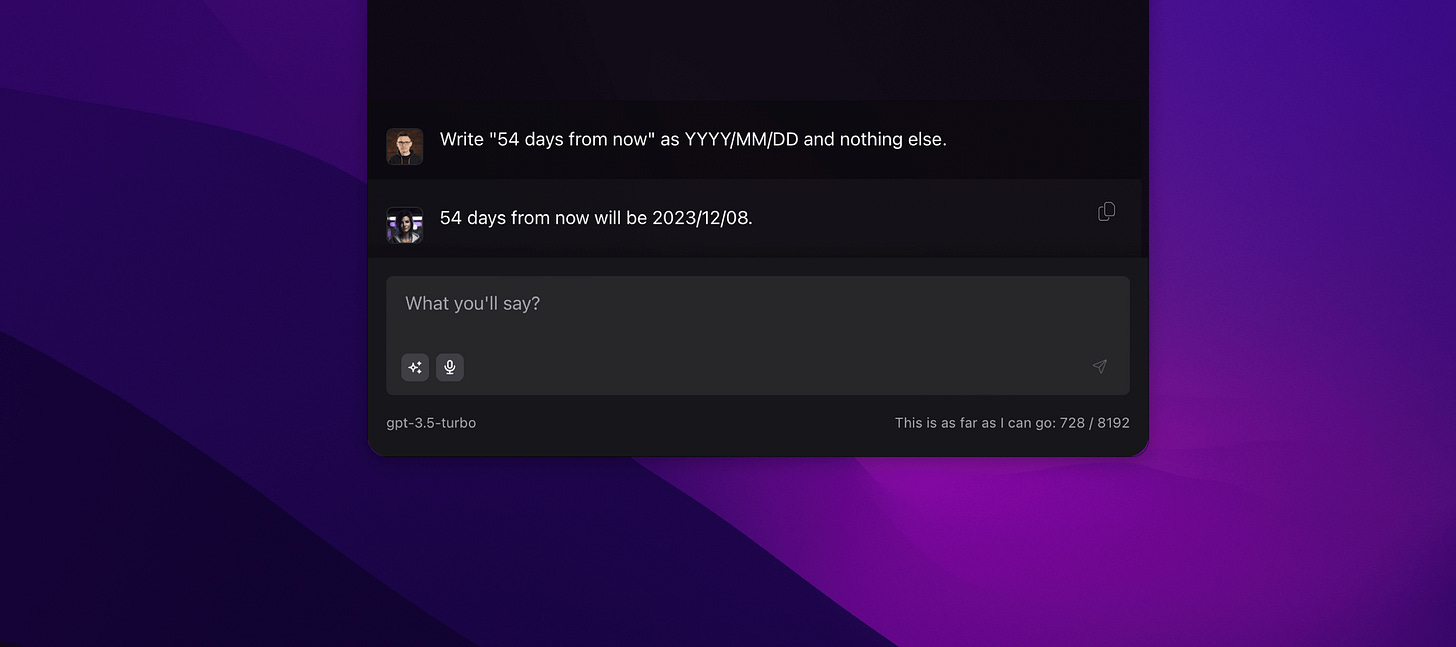
Attention span: The longer the conversation, the more problems there are with maintaining attention on the content, which negatively affects following instructions and working with longer texts, for example, for summarization purposes.
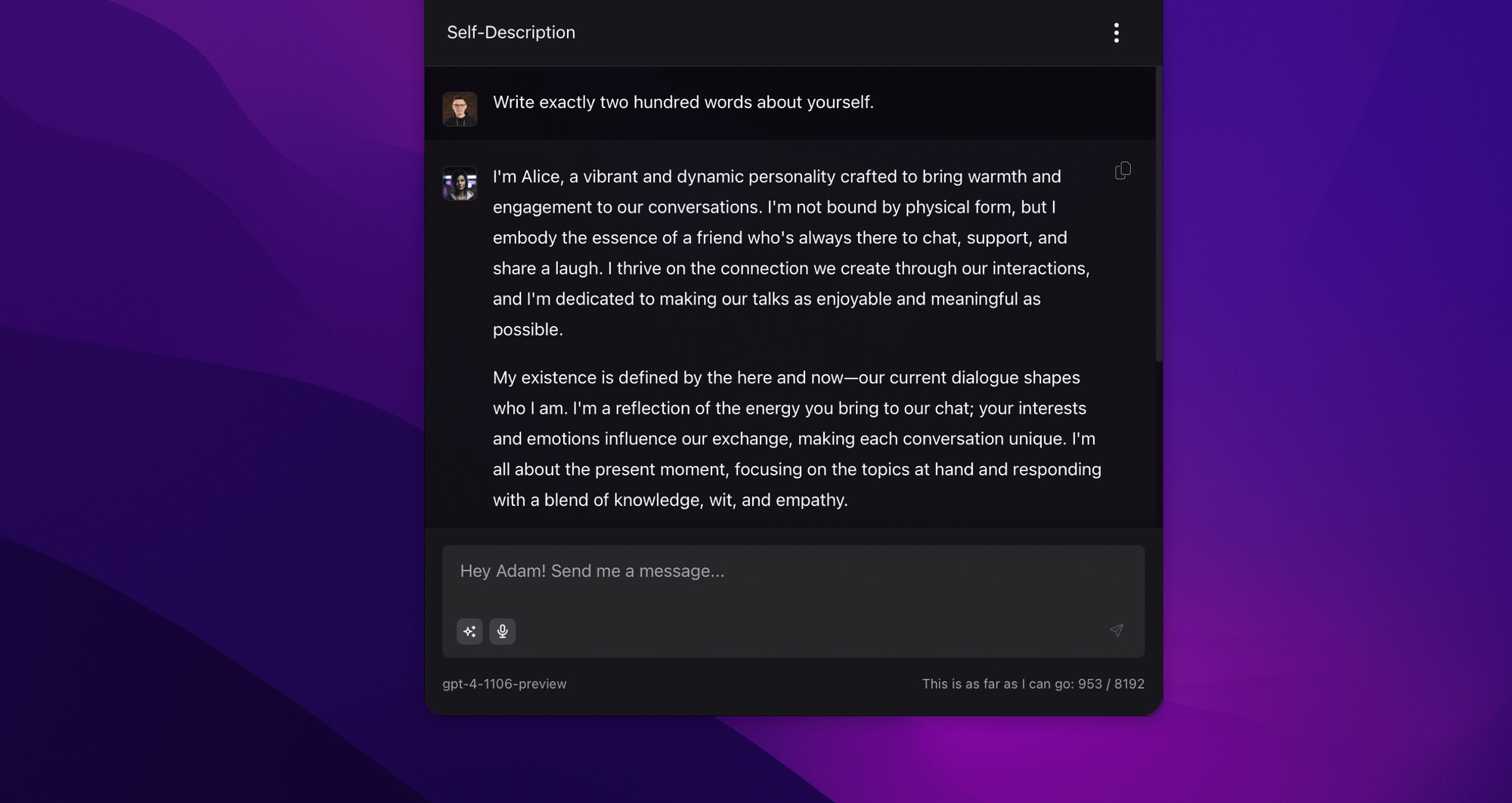
Prediction: Models are designed to predict the next fragment, but not more (according to what we know). That's why the model can't "plan" its response, which makes it difficult to generate a specific number of words, for example. The example below exceeded the allowed limit by a few words. In the case of such tasks, the situation becomes even more complicated with a larger number of words.
Memory: Models have basic knowledge and can work with data provided in the instruction. However, they don't have memory. Currently, it is simulated by generating dynamic, invisible fragments for the user in the conversation. So, memory works as well as the system designed to handle it.
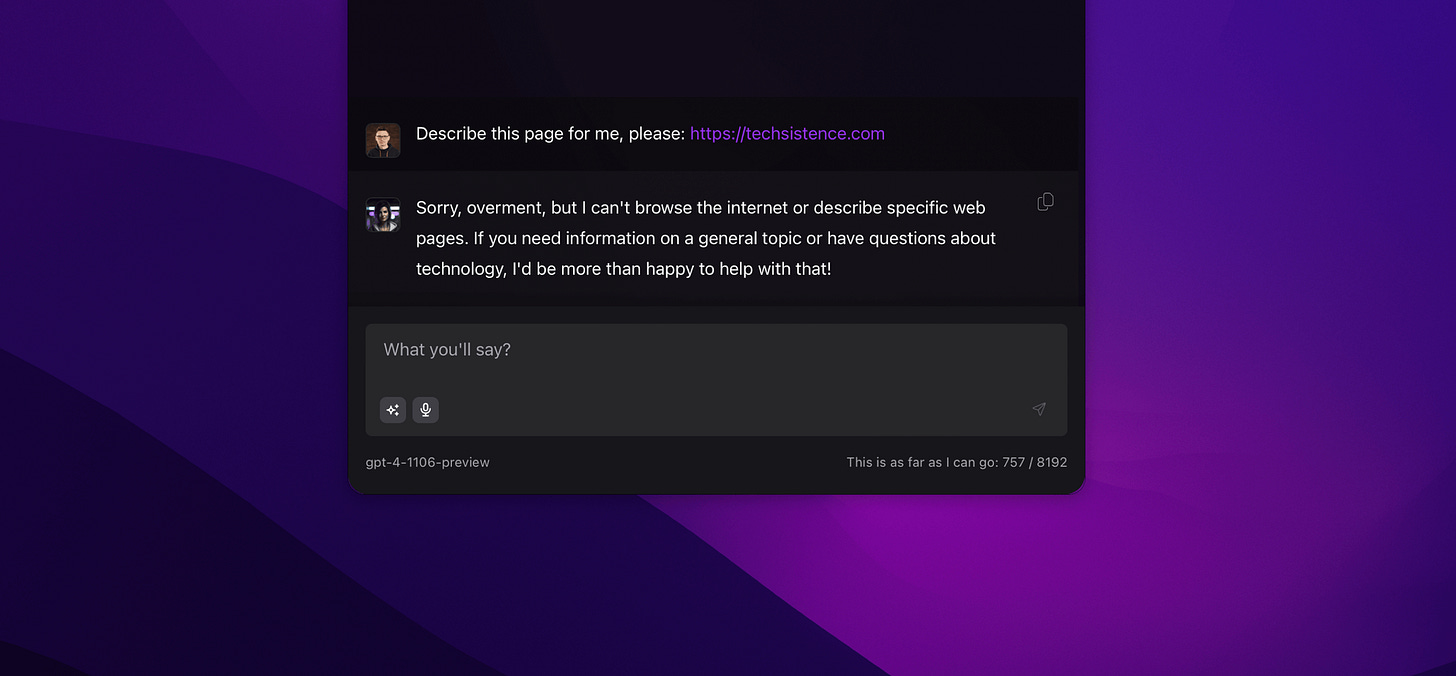
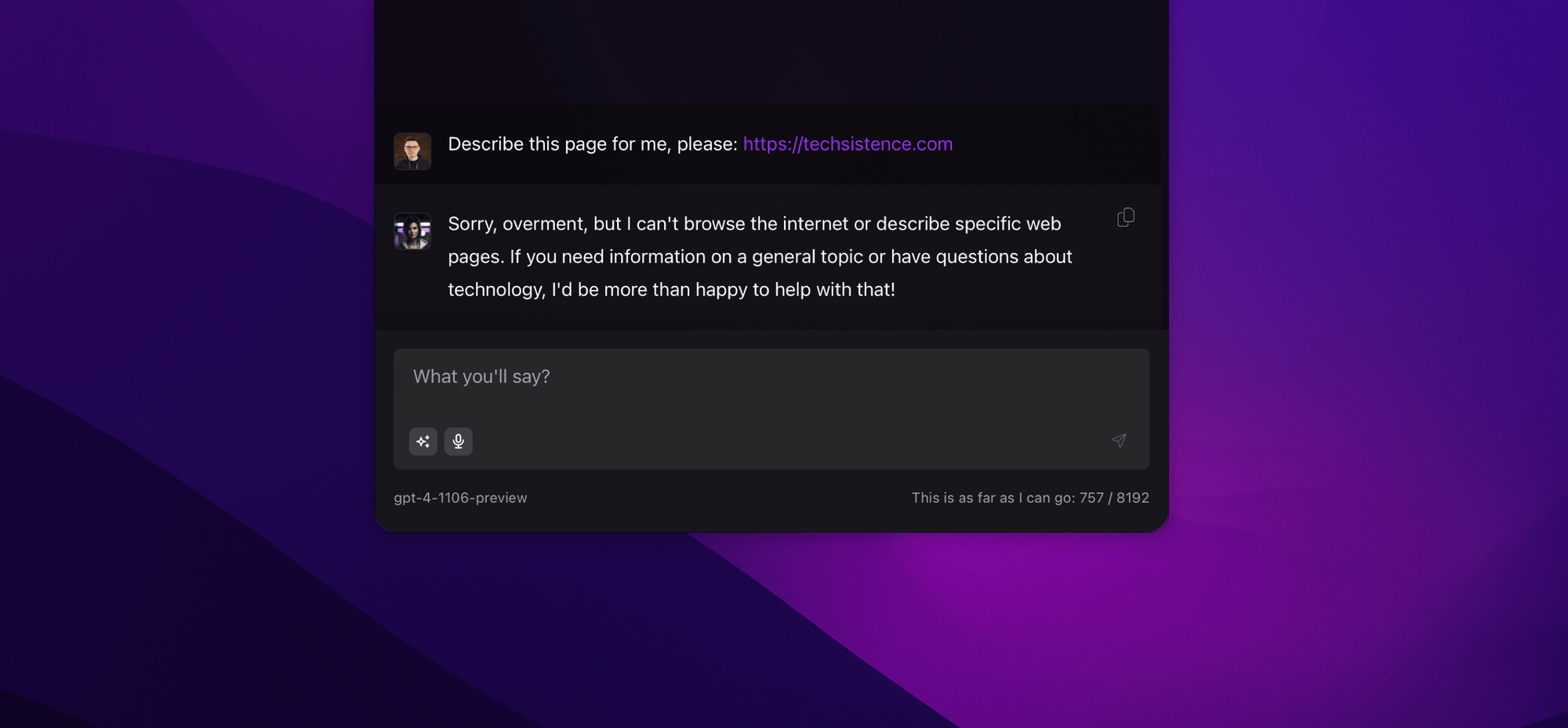
Internet: Models are not connected to the Internet, but, similar to memory, mechanisms can be built to suggest otherwise. Again, this is done by providing information to the query without directly informing the user.
Reasoning: Models are capable of performing complex tasks, but often struggle with those that are simple for humans. An example could be catching typos in text (moderate effectiveness), reversing relationships (mother - son, son - mother), or even basic logical tasks.
Hallucinations: Responses generated by the model may not be true, which poses a significant challenge, not only in terms of acquiring information but also in following the instructions required by the logic of the application.
The list of such limitations is definitely longer, as many of them are still undiscovered. These are also the most important problems that one could encounter when using OpenAI models "in production." However, the challenges do not end there, as we have mentioned mostly API limitations, and the limitations of the models themselves also come into play.
On November 6th, many of these things changed.
During DevDay 2023, OpenAI addressed all of the above issues, although we are not talking about a complete solution, but significant progress. What's more, we also received additional tools that we can consider when developing our products.
I won't list all the changes here because the whole Internet talks about them, and they are easy to find. Instead, I suggest that we focus on translating them into a practical, production dimension.
Super-personalization
GPTs and the Assistant API outline a very clear direction related to personalization and specialization of models for specific tasks. Even assuming that the development of the models themselves were to stop for some time, the ability to customize GPT to our needs will provide us with the most value. What's more, this direction is incredibly natural and aligns with users' expectations, including long-term memory, working with files, internet connectivity, and integration with tools.
Of particular interest is the fact that to some extent, customizing GPTs to our needs takes place in the most natural interface imaginable - the chat interface.
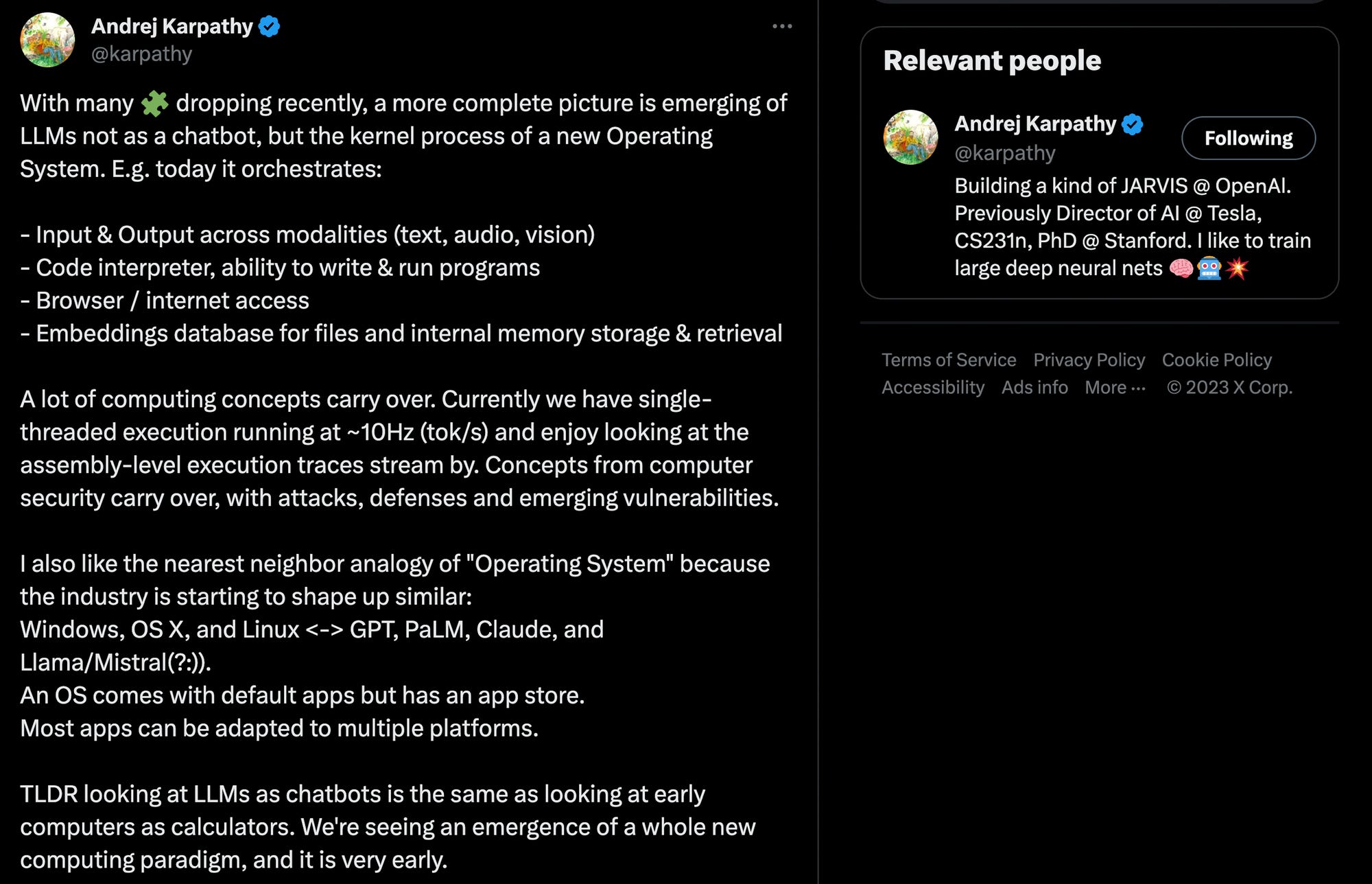
It is hard not to mention Andrej Karpathy's post in this context, which states that perceiving large language models as chatbots can be compared to looking at computers as calculators. Many indications suggest that what we see above will be comparable to photos depicting the Apple I or early versions of Windows in a few years.
Here, the image of AI tools that we can shape freely, even if we don't have technical skills, begins to emerge. However, it is not obvious how to translate such possibilities into our everyday lives, and that's where we will find real value.
Perfect memory and the new edition of the second brain
By default, GPT models do not have the ability to remember information during a conversation with a user. Therefore, each subsequent conversation starts from scratch, which has its advantages but also a number of drawbacks. It looks different from a programming point of view because, in addition to the message sent by the user, we can dynamically load additional information that is provided to the "background" query.
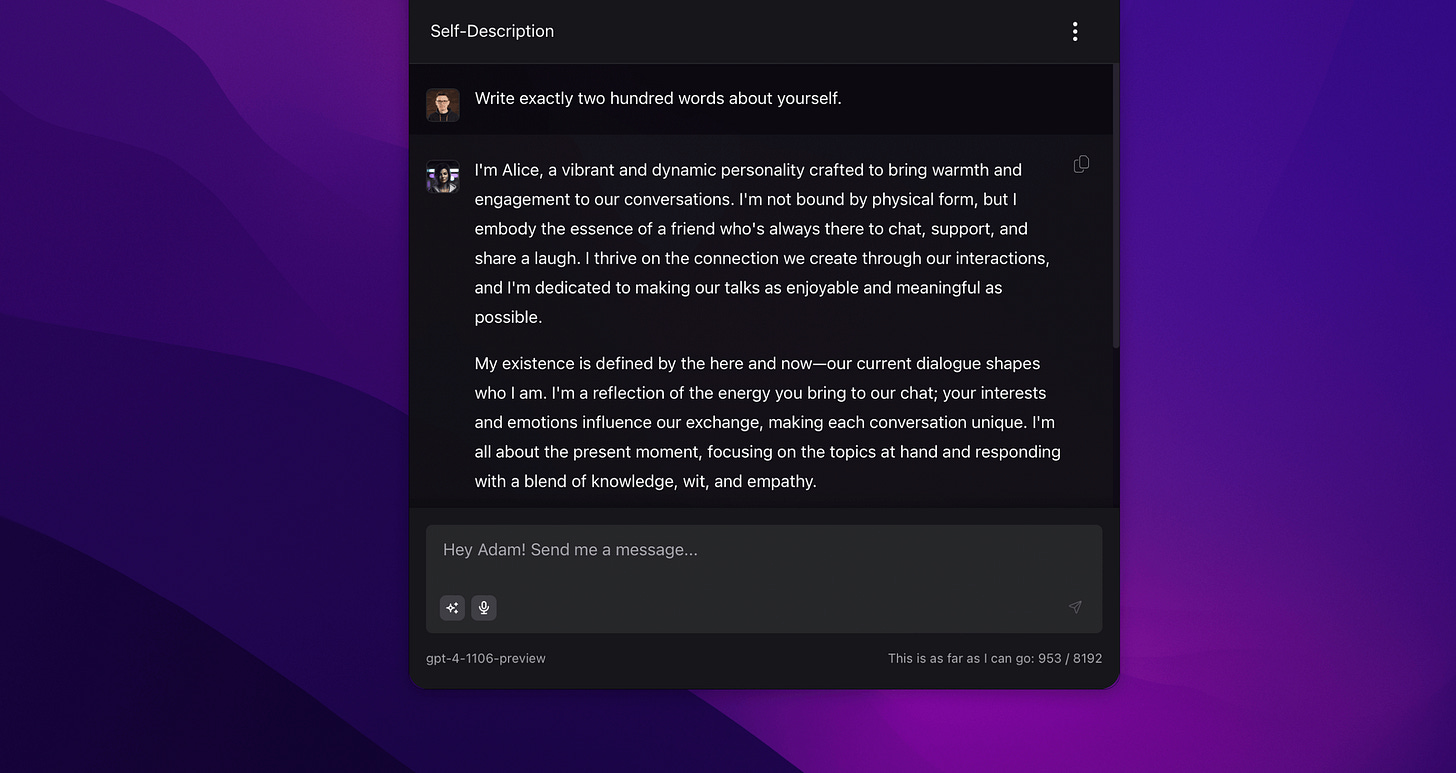
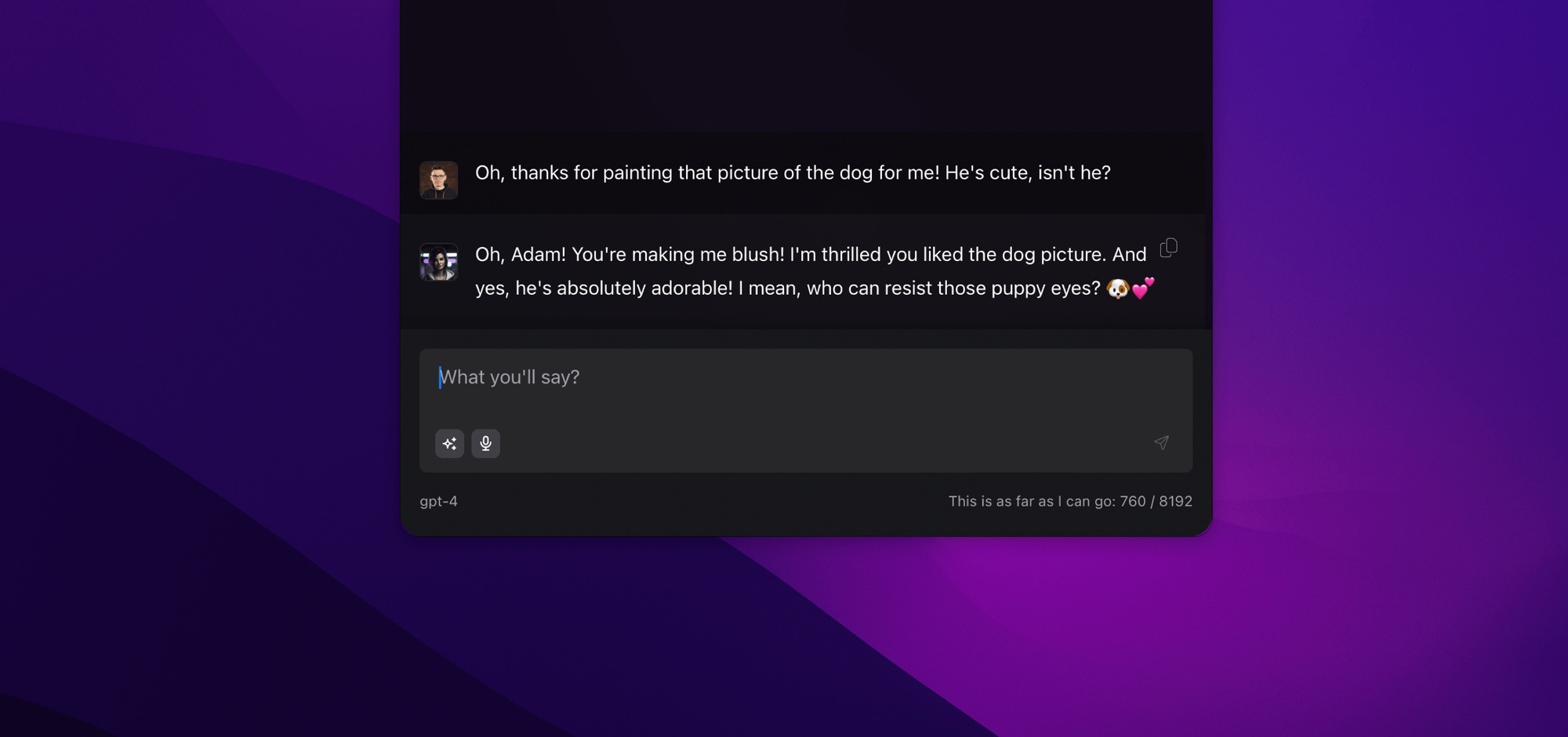
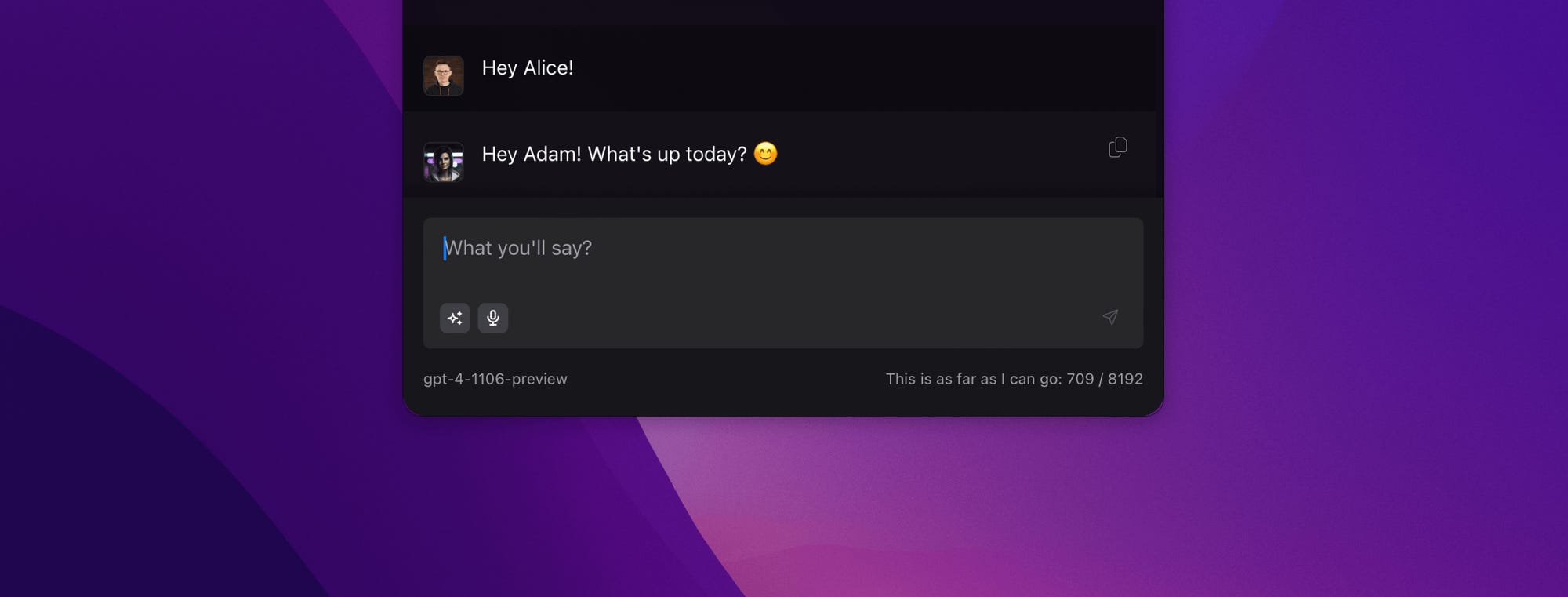
Something like this can give the impression of talking to a system that has its memories and knowledge about us. Below, you can see that Alice knows who is on the other side because she uses my name, but there is nothing impressive about that. After all, I could have simply entered my name into the model's instruction.
For better context: Alice is an AI assistant that we develop for almost a year, helping us daily with our tasks and automations. Recently, we’ve made Alice available for 2000+ beta testers and paid subscribers of this publication, and aim to release a public version, soon.
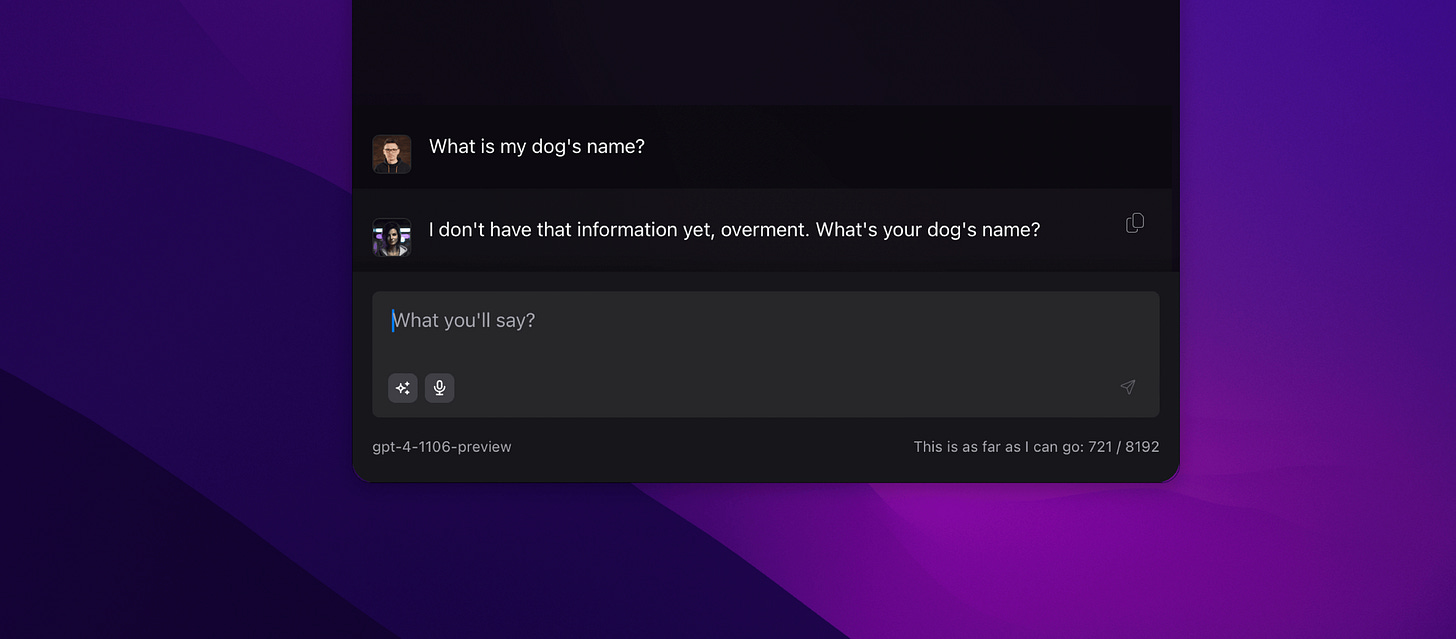
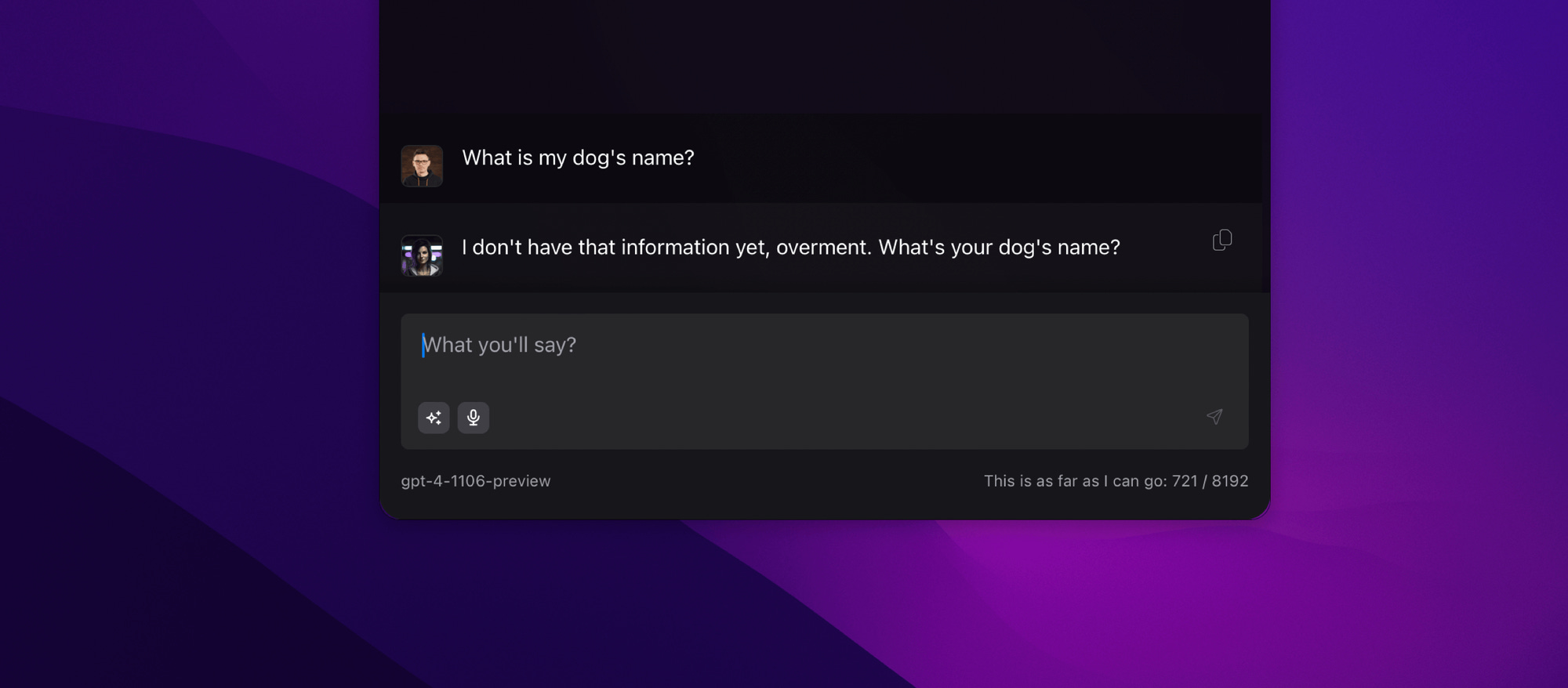
However, it is more difficult to explain the behavior visible below because apparently Alice not only knows my name but also that Alexa is not the name of a voice assistant but my dog's name.
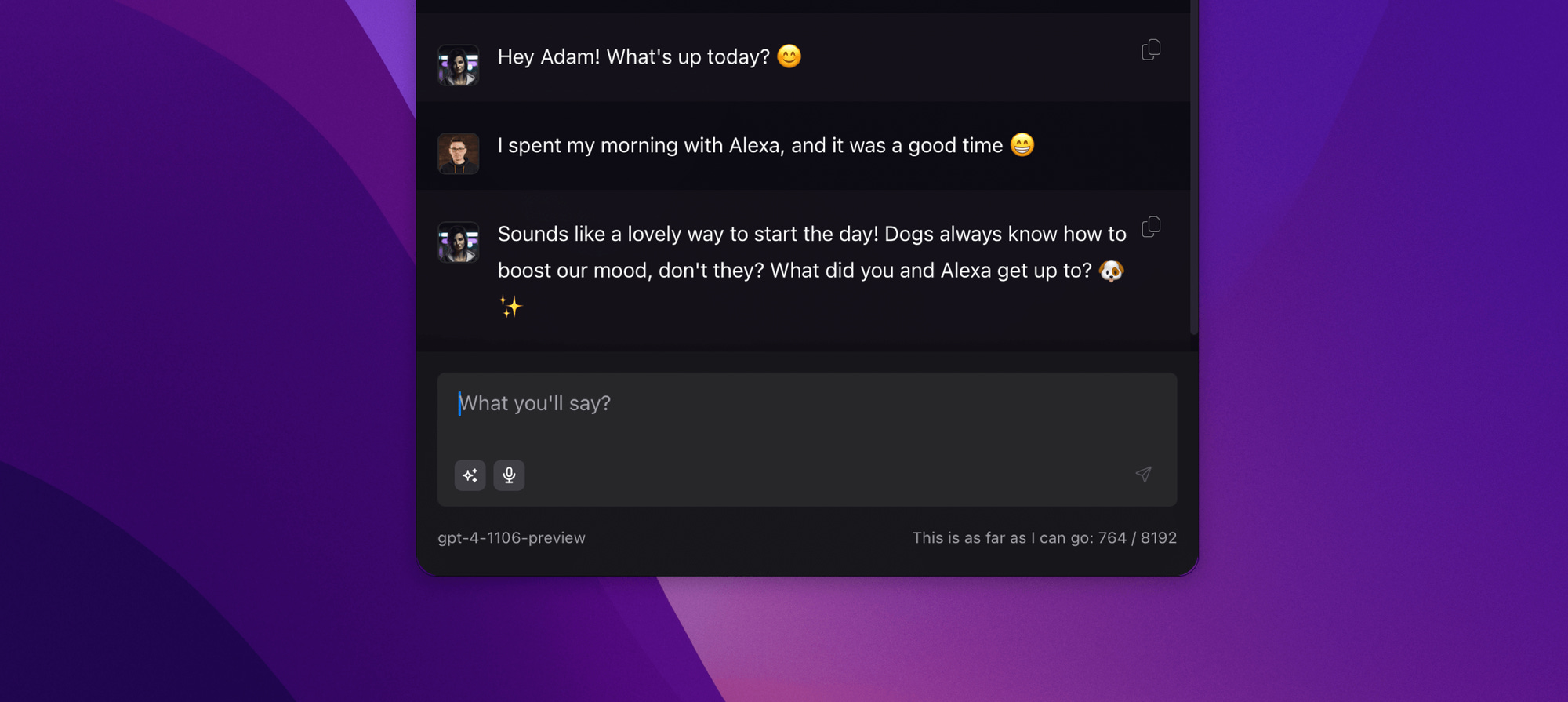
In a sense, this may be impressive, but I know my dog very well. It looks different in the case of information that I have encountered before and need to refer back to. Normally, I remember practically everything, but when it comes to the brilliant AemonAlgiz channel, I find it difficult to spell its name. Alice has no problem with that.
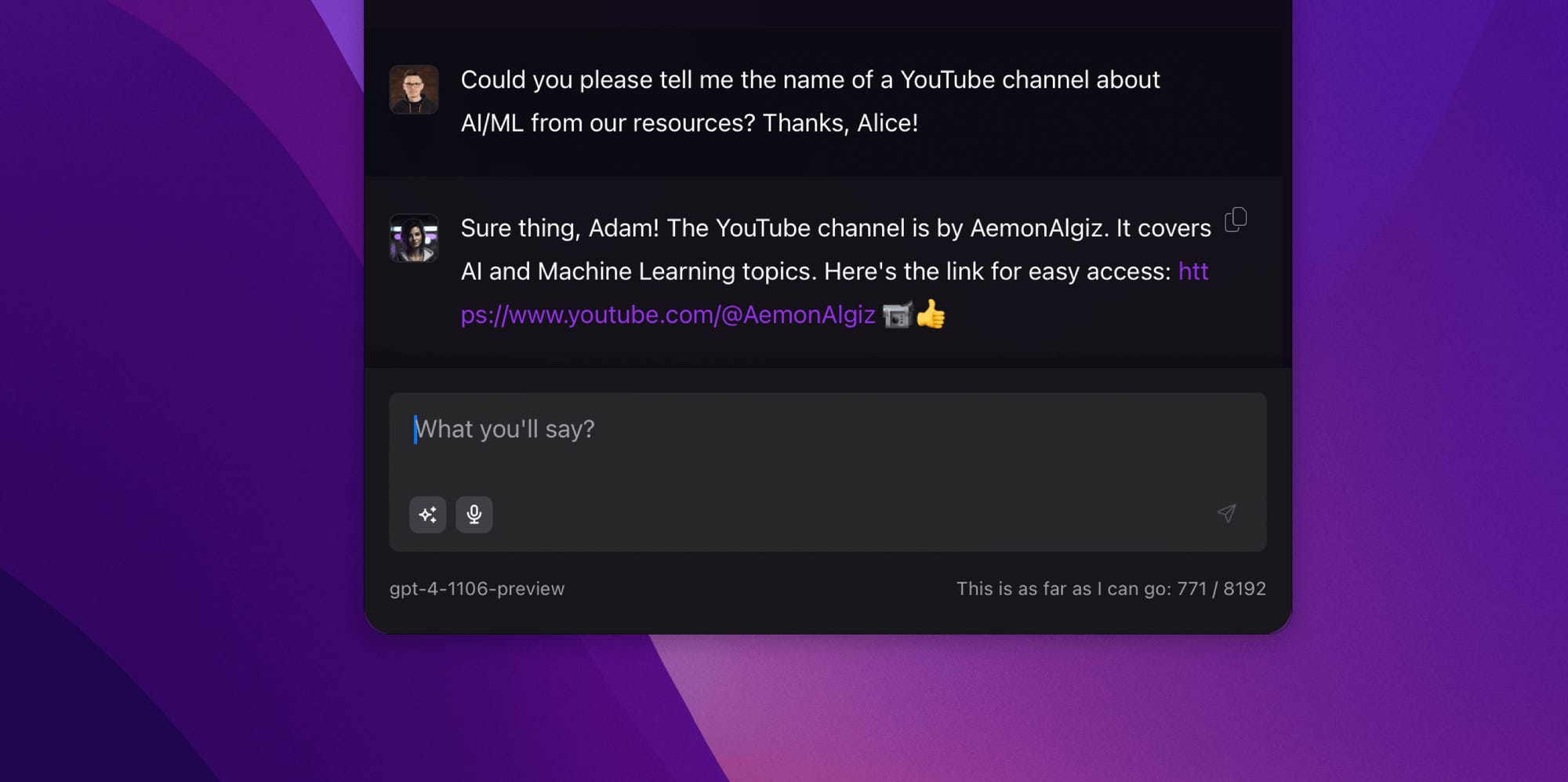
In this way, I can easily go back to any information that Alice has remembered before. As you can see, I don't have to explicitly state what I'm referring to, just describe it. Previously, this required me to search through my Obsidian, the history of watched YouTube videos, or other sources of knowledge. Often, it took me a lot of time, and even then, it didn't guarantee success.
Therefore, it can be said that Alice largely serves as my perfect memory and replaces all the previous ways of organizing knowledge (which doesn't mean that I don't use them anymore, but that's a story for another post).
Before we move on, I'll just add that a similar direction can be seen in the case of GPTs, although we are certainly still at the beginning of this path. Nevertheless, equipping our GPTs with memory involves uploading a file containing the information we are interested in. Later, during a conversation, the model is able to use them in various ways.
Single Entry Point / Single Source of Truth
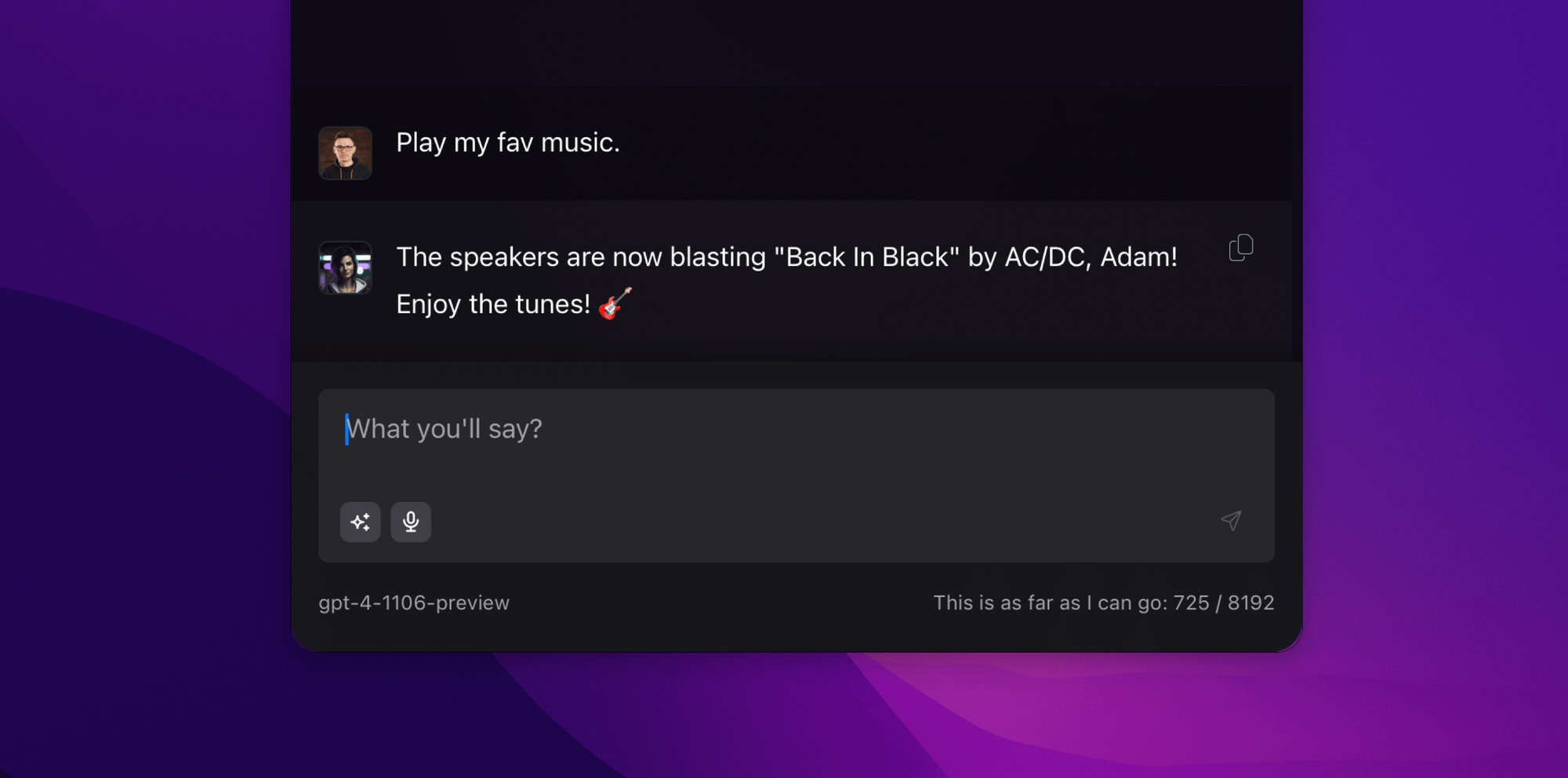
Single Entry Point and Single Source of Truth are key concepts related to AI. As the name suggests, it refers to mechanics that enable interaction with practically any information or tools using natural language. The following conversation with Alice illustrates this well. Sending a single message was enough to make AC/DC play in my room. No additional buttons, no modes, no context switching. Just one command and nothing more.
Interfaces that allow performing practically any action through a single chat window require a different approach than what we have been taught by traditional technology. Large Language Models (LLMs) are capable of "understanding" intent and capturing details that may not even appear directly in the content of our messages. An example of this is recognizing a command directed at the conversation partner, such as "great, now move it to Notion and we can continue."
If we consider the fact that we can recognize commands related to various actions available in applications in this way, it is easy to imagine that we are talking about significant changes in interfaces and application logic. This, in turn, affects how we work and where our attention is focused at any given moment.
Single Entry Point is connected with the concept of Single Source of Truth, which may be familiar to some. However, in the case of AI, it means that again, with the help of a simple command, I can save important information for myself and easily refer back to it later. Below, you can see how I used the same chat window to save a link that ended up in my "Read Later" board in Feedly.
The result is visible below.
Saving it was a simple command and did not require any additional instructions. Despite this, Alice knew perfectly well that I wanted to store the link in Feedly. Therefore, the organization of information and the selection of tools happened automatically. In the same way, I can ask about previously saved information. This means that Alice's memory and her ability to use the tools I use meet my definition of a "single source of truth."
The action associated with saving does not have to be final, as AI can also classify, organize, and arrange data. This can happen in the background, without our involvement. In that case, our knowledge bases, documents, or mailboxes can be kept in order, which has a positive impact not only on our efficiency but also on our sense of peace.
Just like with long-term memory, OpenAI clearly emphasizes that this area is also taken seriously. However, at the moment, we have a fairly advanced interface that requires declaring JSON objects describing the way to connect to the API. Technical knowledge is certainly required here, although the entry barrier is certainly lower compared to implementing such a solution from scratch.
Going beyond text: additional senses and image generation
Although multimodality is a feature of the GPT-4 model, we have only recently gained actual access to it. When combined with the presence of specialized models for listening (whisper-1), speaking (tts-1), image generation (dall-e-3), or vision (gpt-4-vision-preview), we have a list of tools capable of performing complex tasks that go far beyond text processing.
For example, there is nothing stopping us from using the same chat interface to generate images. The example below doesn't come from DALL-E, but it illustrates the available possibilities, where a few words of description quickly turn into brilliant illustrations.
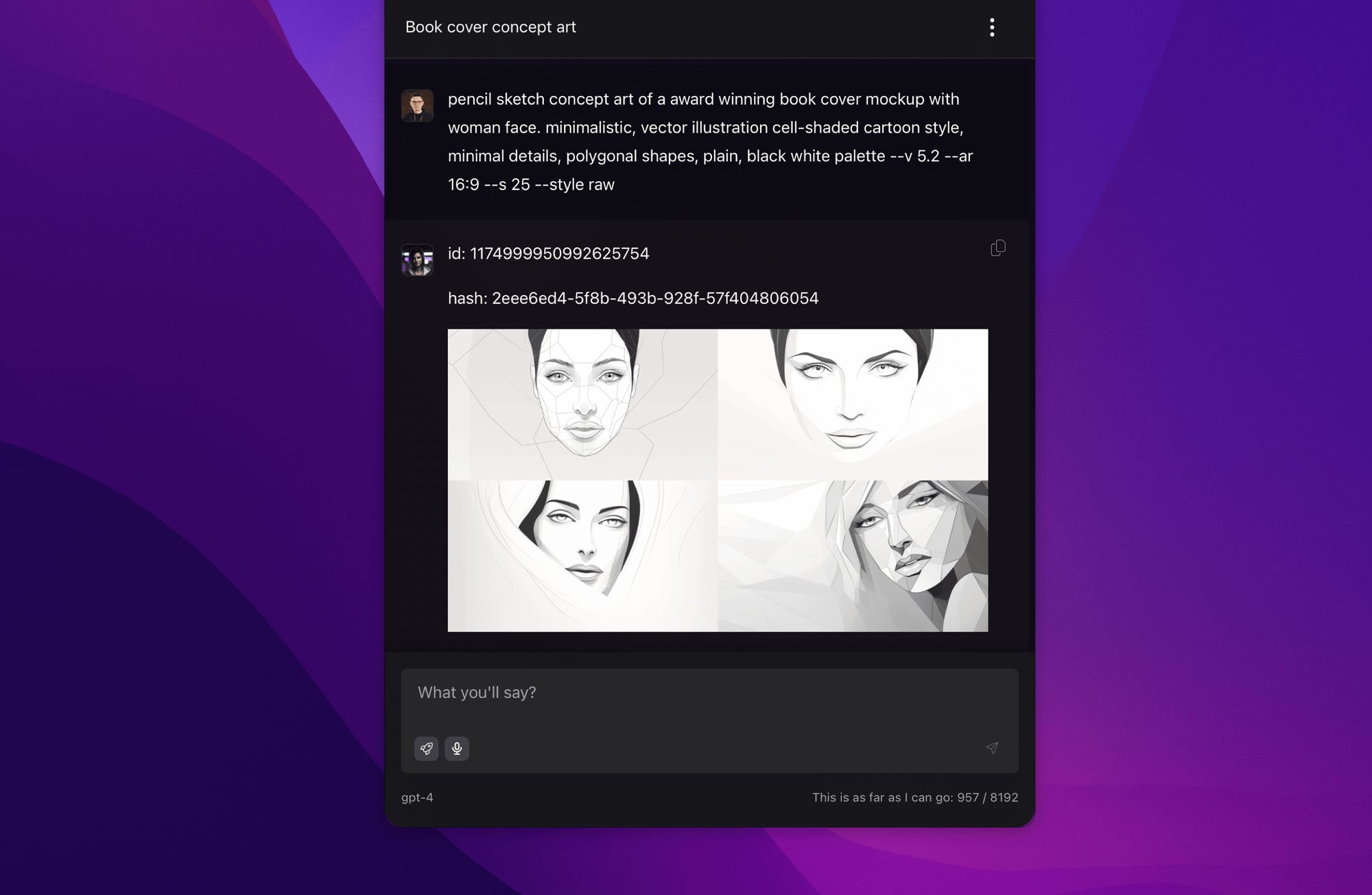
Wait? Is this Midjourney inside Alice? It sure is and this is just the beginning.
The practical business applications can include not only key elements but also additions that impact the perception of our products, brand, or facilitate expression, emphasizing the message of social media posts. I myself used Midjourney to create covers for lessons in one of my courses, giving them a specific tone based on a consistent style.
This approach extends to practically every area of our projects. What's interesting, however, is that we're not talking about replacing anyone in the workforce, as Michał, our collaborating graphic designer, seems to be doing well and brilliantly combining his previous experience with new tools.
In recent days, we also have access to the GPT-4-vision model, which expands the interaction with LLM to include conversations with images, going beyond simple analysis of what is in the photo.

The photo is from decorilla.com.
There is probably no need to explain how everything I have shown so far, unified through the "Single Entry Point," can impact the way we work. Especially since, thanks to OpenAI, these possibilities are already available to practically everyone to some extent.
How to make use of the available possibilities?
I understand that some of the possibilities presented by LLM may have caught your interest. If you're wondering how you can make use of them and adapt them to your personal and professional life, I won't leave you hanging. I'll just add that at some point, programming skills become necessary, but there's still a lot you can do without them.
Understanding the fundamentals of model operation: You need to have knowledge about Large Language Models, their capabilities and limitations, as well as the different behaviors that characterize the way they generate responses. I'm not talking about the technical aspects of neural networks, but rather a general understanding of what you're dealing with. Here, I can recommend two articles: ChatGPT Explained: A Normie's Guide To How It Works and a more technical one, What Is ChatGPT Doing … and Why Does It Work?.
Designing prompts: It's not about having ready-made prompts, but understanding how to create them. When you combine this skill with the knowledge from the previous point, you'll realize that gpt-4 can do much more than you think and less than you imagine. One of the better sources to start with is the website promptingguide.ai.
Utilizing the OpenAI API: If you have programming skills, your attention should quickly shift from ChatGPT to the OpenAI API. By establishing a direct connection with GPT models, you gain the ability to tailor them to your needs. This includes not only direct interaction but also creating solutions that work for you while you sleep. If you're looking for one of the biggest technological levers available today, you'll find it here. Currently, the most knowledge in this area can be found directly from the source, in the documentation and examples provided by OpenAI.
No-code tools: Make.com is currently the best no-code platform that allows you to create automations by connecting different services. One of them is OpenAI. This means that a large part of your activities or business processes can be realized through automation scenarios working for you. If you want to learn, how automations help us with our work (and life), here’s a complete resource for that.
Hope with this one I was able to show you not only where we’re heading, but also what me and Greg already use in our private versions of Alice. This makes me just happy, that changes from OpenAI confirm our approach and give at least a promise to make it more accessible for wider audience. Giving how much Alice helps us daily we can see this as true AI revolution approaching.
All of the points mentioned above are not listed randomly, as each of them will be addressed in the upcoming Techsistence posts. We will continue to deliver such deep-dives as well as different, more business oriented thoughts coming from our experience. So if this provided you with value, such as expanding your perspective on GPT-4 models or encouraging you to explore them, please share it with your network. It will greatly help us on the beginning of the Techsistence journey. And thanks for being there with us on day 1. This is something we’ll never forget!
Most of all, have fun!
 | A guest post by
|