

Personal AGI — Pushing GPT-4-turbo beyond all limits
What possibilities do AI agents offer today, and how can you build a system with long-term memory for complex autonomous tasks?

Agent AI is typically an autonomous system capable of performing complex tasks using long-term memory mechanisms, external data sources, tools, and even other agents or simply humans.
The logic of these systems combines application code with the capabilities of large language models (LLM). This solution allows for flexible adaptation to current conditions, development of an action plan, and its implementation using both internal and external information.

Let's see if such systems can become part of our everyday life, based on the example of the agent I work with.
Technology has limitations on what it can accomplish. You do not. ~ Lou Gerstner, Former CEO of IBM
Scope of the "Personal AGI" system
"Personal AGI", or personal general artificial intelligence, is a fairly good term for a system whose goal is to accompany us in virtually every situation. Of course, this should be taken with a grain of salt, as it is not a system that meets the definition of AGI, but the main idea here is to adjust our way of thinking in such a way as to go beyond the patterns defining how we use LLM.

Agent AI usually consists of several components, such as memory, tools, logic, and interface. Each is an element of a whole that cooperates according to established rules, which can be defined more or less precisely.
Memory: Short-term memory includes information stored for the current conversation or its part. In contrast, long-term memory can be used over many conversations. Agent AI should have the ability to freely access memory (both for writing and reading). An additional element of memory can also be something I call "context" (or simply "document") which is usually a larger set of information with which the agent can work or refer to. For example, after loading the content of a website, it is not directly entered into the prompt, but has the form of an identifier to which the agent can refer if necessary.
Logic: The operation of the agent takes place through a combination of programming logic (e.g., HTTP queries, functions, or file system handling) and a series of advanced prompts covering self-reflection, intent recognition, internal speech, planning, or elaborate contemplation through content generation. Here, the use of various models and processing information from different sources comes into play.
Tools: LLM can precisely select tools for problems, generate structured data needed to use them, and interpret the results returned by them. In the digital world, tools take the form of functions that can be run locally in the application code or through an API. The API can include both external services and the assistant itself, allowing even to ask questions to oneself or refer to one's own memory or skills.
Interface: Contact with the agent can take the form of text chat or voice messages (e.g., through integration on a Slack channel). The use of API also comes into play, allowing for automatic sending of messages to the agent, either according to a schedule or as a result of an event. Consequently, the agent should also have the ability to proactively send messages directly to us.
Naturally, the structure of the agent and the available modules may vary depending on the purpose.
Environmental Information
The agent can access current data using tools, but sometimes technical limitations of devices and services prevent this. Additionally, certain information should be available by default, without needing any tools.
Examples of such information include:
Current date and time
Our location
Current weather
Device status
Active applications
DND mode
Distance from home

Data can also encompass areas like sales statistics or recent events. Updates might happen through automated scenarios or scripts triggered by specific events. This leads to a situation where the agent adjusts its behavior not only during conversations with us, but also when performing tasks independently!
Short-term memory, long-term memory, and document handling
LLMs have token limits that they can receive (input tokens) and generate (output tokens). Besides, we are also interested in relatively low costs and an acceptable response time (which can be significantly reduced thanks to Groq).
Short-term memory: Includes the content of the current conversation, as well as additional information that was read during their generation. For example, if the name "Alexa" appeared during the conversation, my agent will read information about my dog, but in the next message, this information will no longer be available. For this reason, at least a summary that allows the conversation to continue should reach the conversation context.
Long-term memory: This is a topic for a separate post, and I partially addressed it talking about No-code Agent. Nevertheless, we will stop here for a moment.
The agent's memory is a database searched during conversations to load necessary context for responses. While this task seems simple, it's actually a complex challenge without a current solution. We are focusing more on improving these mechanisms' effectiveness rather than perfecting them.
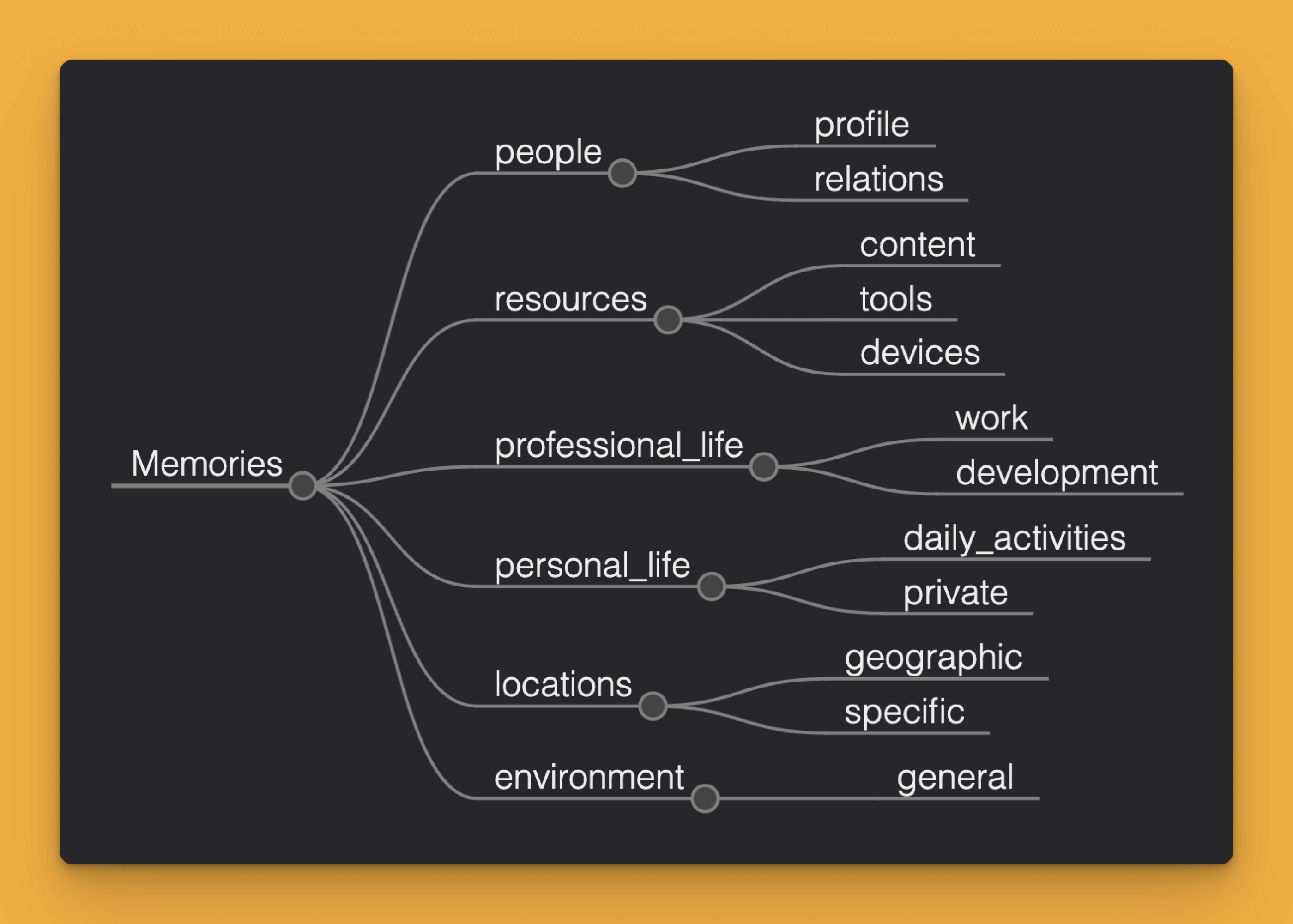
A very basic memory structure can be divided into different areas concerning known people, remembered resources, or locations. It may also contain more specific areas, including knowledge about professional and private life. Such a division quickly proves insufficient, and it is necessary to include additional categories or a tagging system.
The whole must work both for the needs of storing information and organizing it, as well as for later updating, forgetting, or searching for the purpose of conversation. On the one hand, almost the entire process can be handled by LLM. On the other, as I mentioned, it is currently an unsolved problem if we want to talk about 100% effectiveness.
Context / Documents: In working with the agent, situations may arise where it will be necessary to process longer content. An example might be correcting a long blog article (such as this one). Even if we manage to fit it entirely in the context window (input token), the model will not be able to generate a response containing a full translation at once. Therefore, we must divide the document into smaller fragments and then process each of them. However, even in such a situation, the LLM will not be able to deliver it directly to us. Instead, the tool responsible for translating the document can only pass an identifier, which will be used in the model's statement and then programmatically replaced with the proper content.
An example of such behavior can be seen below. My message contained a link to a file containing the content of the post that was to be corrected and translated. Despite its volume, the programming part of the agent's logic processed its fragments, then combined them into a whole and saved them in a file. The LLM only received the URL, which it included in the email it sent me.

Although context limits are constantly increasing, the mechanics responsible for processing content in parts may prove very useful. An example might be the substantive verification of a post, in which individual parts of the article are transformed and juxtaposed with information from the Internet or the agent's long-term memory.
Tool organization and handling
The agent may have access to virtually any number of tools as long as we ensure that it can effectively use them. Tools can serve various functions but should ideally have a uniform input/output interface. Of course, it is possible to use models for direct interaction with API services, but almost always we will want to add our own logic, which requires the presence of an intermediate layer.
The tool list might look like this:
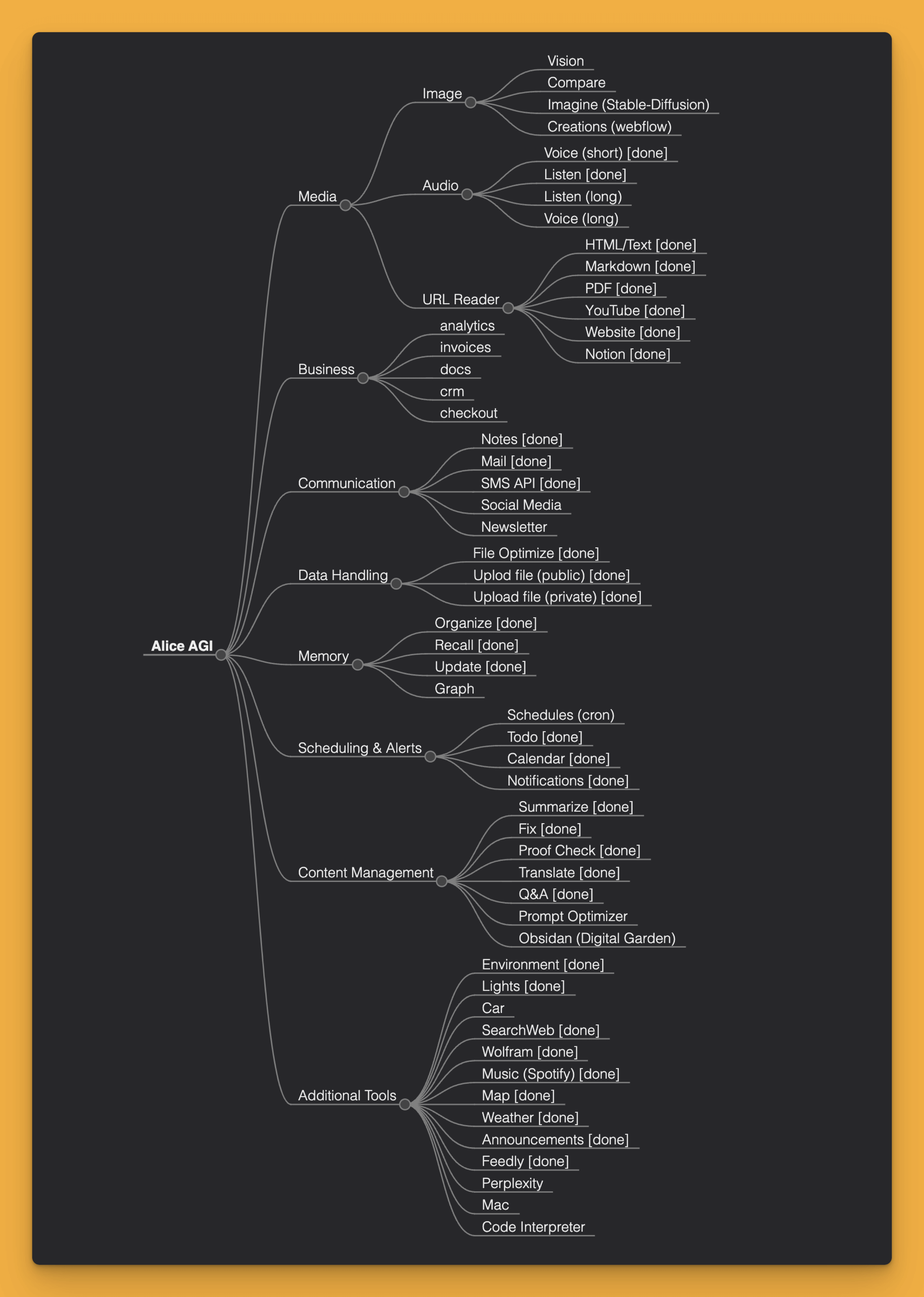
As you can see, we have access not only to the API but also to various functions that extend the capabilities of the LLM or add options that it does not inherently possess.
In designing tools, it is worth paying attention to:
The aforementioned consistent interface
An additional intermediate layer containing protections against model hallucinations and limiting access to selected actions
The ability to perform many different actions within a single query (e.g., adding and updating several tasks to Todoist simultaneously)
The way data is transferred between tools (e.g., the aforementioned passing of identifiers or links to files)
Providing additional data needed to complete a given task
Proper error handling, attempts to fix them, and appropriate reporting
Thus, for example, the "Add task" action expects a JSON object containing a list of entries to be updated, another containing those to be added, and another with those to be removed. Additionally, there is also the possibility to retrieve tasks from a designated period (e.g., the next two weeks). Besides, there is also the possibility to download tasks from a designated period of time (e.g., the next week). In response, we receive a JSON object containing all the information necessary to provide a response by the LLM or to take further actions.
In my case, the list of tools is divided into categories:
Media: tools enabling image and audio file processing, including their description and generation
Business: includes tools directly related to running a business, especially formalities and statistics
Communication: tools through which the Agent contacts the outside world or directly with me. Of course, all messages sent outside go to a queue, which I personally must confirm
Data handling: includes operations on files, including the ability to upload them to the cloud for further sharing
Memory: includes full memory management
Action planning and alerts: a set of tools that allow for background operation, monitoring, and reporting
Content management: contains all tools related to advanced text processing, including the processing of images contained in it (the default processed format is markdown. More about this in "Content is the King but for how long?")
Additional tools: all tools that do not fit into the previous categories. They mainly include individual interactions with services and devices I use daily.
Currently, implemented tools allow me to issue commands such as:
Remember that...
Gather everything I know on this topic
Send an SMS, email, or Slack message
Review these photos
Play my favorite music
Watch these movies and tell me what they are about
Read these articles
Proofread this post
Issue an invoice
Prepare a report
Add these tasks to the list
Check how long it will take to get to this place
Remind me about something important
Perform this task every Monday
Record a podcast
Compare these files
Check this document for substantive content
Prepare the car for a trip
Publish these posts on social media
Send a newsletter
Prepare advertising creatives
Save this in my notes
Generate images matching the description
Turn on the lights
Turn off the computer
Interestingly, issuing more complex commands also comes into play, such as:
Watch these movies, list the mentioned sources from them, search the Internet, describe them including links, and send me an email
From now on, check the following sites every morning and if they contain new posts, record a private podcast for me and send the link on Slack
Check if these documents contain any information on topics related to the projects I told you about
Help me prepare a title and post promoting my latest blog entry and generate covers for it.
Correct my article for typos and syntax, then check it for substantive content and prepare a version in two languages. Send me the finished files and let me know when you are done.
Convert these messages into tasks or events in the calendar based on their content
Listen to this voicemail and write a note based on it and send it to me. Save a draft in my notebook
Compare these graphics and the messages on them with the tone of the brand of the project I told you about. Apply the techniques we discussed and suggest changes
And of course, all these commands can be sent by me either vocally or textually, or be sent automatically with the help of scenarios connected to the agent's API. Despite the fact that the current logic is not particularly complex, it turns out to be sufficient for performing tasks with very high efficiency. Unfortunately, this comes at the cost of speed of operation and a high bill at OpenAI, reaching several hundred dollars a month. However, considering the value I receive from this, the costs are justified.
Agent Logic
The components we just went through are just as important as the logic responsible for connecting them together. Here, just like in the case of memory organization methods, work techniques, and tools are still at a very early stage of development, and we are largely reliant on our own creativity and what we know about model behavior.
Let's start with the fact that currently, the most demanding tasks are best handled by models GPT-4-turbo and Claude 3 Opus. For less demanding tasks, we can successfully use models Claude 3 Haiku, and Llama 3. I base almost all the logic on the GPT-4-turbo model, as optimization against weaker models will come a bit later. I also count on the fact that a new version of OpenAI models will soon appear, which will further facilitate the development of agent logic.
A simplified scheme of my agent's logic for the message "Hey there Alice! What's up? Alexa says hi btw 🙃" consists of the following steps:
Gathering context: Retrieving environmental data, summarizing the ongoing conversation, list of skills, and memory areas
Self-reflection: This initial stage is where the agent considers what to do with the received message. It compares it with available memory areas, the ongoing conversation, environmental data, and its list of skills. The result of this stage is a few sentences of reflection, resembling internal speech or ordinary thoughts. The generated content is very valuable from the perspective of the next steps, as it significantly increases their precision.

Action plan: Based on self-reflection, early action planning and memory areas to be included in the memory recall process are determined. The generated content is a JSON object containing two properties queries and actions, where the first contains a list of questions to its own memory, and the second contains a list of actions to be taken.

Recalling: Using the action plan and self-reflection, the agent generates a list of questions to different memory areas. This way, it increases the likelihood of finding information that was not directly mentioned by the user but may be useful in providing a response. For example, to a simple message "hey, how are you?" the agent not only retrieves information about itself but also reads the profile of its interlocutor, current weather, or location to use it during the conversation.

Internet search: If required, the agent may support itself with an internet search engine, also generating a series of queries to help it better understand the mentioned topics
Taking actions: If some tools were mentioned in the action plan, at this stage the agent starts using them while also considering how to use each of them. Moreover, actions are initiated in such a way that the result of one can be used in another.





I will add that the above scheme will soon change to increase the speed of operation and overall optimization of the entire logic. However, even at this stage, it can efficiently use the available tools, even if the queries are complex and require reaching for several of them. So, if I ask to check the list of tasks and events left for me for the day, the agent's logic will include:
Retrieving information about the current date
Indicating the tools "google calendar" and "linear"
Running these tools to retrieve entries for the current day
Providing an answer to my question
The same principle applies to every other command or message. Thanks to autonomous logic, it is possible to accomplish even quite complex tasks without human involvement. At the same time, everything moves within a very strictly defined context, and it is impossible to issue absolutely any command. However, the system is sufficient to provide me with real support in daily tasks.
Conclusions, Observations, and the Great Opportunity
Autonomous agents are currently one of the hottest topics in the industry. Despite their huge popularity, there are clearly a number of unanswered questions or outright barriers that are very difficult to cross. On the other hand, when I compare the capabilities of the gpt-4-turbo model with what was possible just a few months ago, I see how much progress we have made. Seemingly these are small changes, yet improvements in reasoning (e.g., calculating dates or maintaining attention) are huge.
Looking now from the side at my previous experiences, I turn my attention to issues such as:
Organizing memory in a graph structure or finding another way to link records located in different memory areas
Designing mechanics capable of dynamically building memory structure or at least moving within universal categories with mechanics enabling scaling
Modifying the agent's logic in such a way that each action has access to different memory areas or search results on the Internet
Breaking down larger prompts into smaller steps and performing them in parallel wherever possible.
Including advanced techniques for combining prompts with particular emphasis on self-consistency - Incorporating advanced techniques for combining prompts with a special focus on self-consistency
Modifying the action logic in such a way that some of them can be executed in parallel, while others are interconnected. Currently, only a simple queue is in play, which is insufficient from the perspective of autonomy
Including better error handling and overall performance optimization, including cache memory mechanics
Adding full monitoring of application logic for easier debugging and making changes
Adding the capability for autonomous analysis of logs and executed prompts for their later optimization
The above points also do not consider limitations that should also be considered:
Even with the GPT-4-turbo model, there are clear problems with maintaining attention on the available context
Logic consisting of multiple prompts requires dividing them into modules, which in turn greatly complicates their evaluation
The speed of model operation is very low, especially when many prompts are involved or there is a need to process longer documents.
The costs of operating models also remain very high in situations where each of our responses consists of a series of prompts
Subsequent versions of models, although seemingly offering minor improvements, gain significance in the case of autonomous agent logic. Each additional percentage chance of getting the correct answer quickly starts to add up, affecting the overall picture
The ability to create and verify prompts still plays a critical role and currently, little indicates that this will change in the near future
In summary, about "Personal AGI", creating an application capable of addressing even a few activities from our daily lives has become within the reach of practically every programmer. It is relatively easy to create a system capable of remembering information or performing more or less complex actions tailored to us.
At the same time, undoubtedly creating such a system that will be universal enough to be widely available to users remains beyond our reach, mainly due to technological limitations. Therefore, it's the perfect time to develop our skills and create tools that support us in daily life.
That's all for now,
Adam