

Content is the King but for how long?
Generative AI can create content faster and sometimes more effectively than humans. So naturally, the question arises — what role does content play if we can now easily generate it?


Creating content is an integral part of my learning process and constitutes a certain part of my professional activities. Therefore, it can be said that I do it with two aspects in mind, one focusing on me and the other on you, aiming to deliver value to us both. My benefit lies in exploring selected topics and getting to know them thoroughly because only in this way can I shape my message to be clear to you and fulfill its assumptions. On the other hand, the benefit for you may be associated with saving time or what you potentially gain from new knowledge.
Static Content
As you read these words, I have already finished the process of shaping them, which indeed allowed me to organize my thoughts, combining them with external sources and my own experience. This text has a static form and will probably never be modified or updated by me again because my attention will be focused on creating new content. Moreover, even if I made some modifications to it, the chance that you will notice them is minimal because we usually only return to previously read posts in rare cases.
The relevance of content starts to become a problem when you come across this post months or even years after it was written. Then its perceived value may be lower than that present right after the premiere. However, if we look at this problem more broadly, we will notice further challenges. Namely, some of the topics discussed by me may appear in subsequent posts or vice versa, which may complicate their individual reception.
Understanding the content may also be difficult, even if my post is completely separated from the rest of my publications. Of course, in such a situation, you can write a comment or reach for external materials. However, undoubtedly, we are talking about a certain kind of barrier or difficulty in interacting with static content.
Ultimately, just reading or even understanding the content is often not enough to derive value from it because we want to apply it in everyday life. Here arise additional requirements related to the need to translate my examples into your context. Even just reminding yourself of what I wrote about and where is not obvious.
The post visible in the image below was written 2 weeks before the publication of the one you are currently reading. Although the concepts presented in it are current, the way I applied them is no longer. If I write another text on the subject of the introduced changes in some time, the person who has read both posts will have a broader perspective and will more easily assimilate new content than the one who has only seen the latest text. This is logical and so natural that it is essentially difficult to do anything about it.

To summarize this:
currently, content is static. Once written, an article or recorded video is unlikely to be updated
the reception of content can be difficult for many reasons, such as the complexity of the topic, references to external sources, or the reader's experience
access to content is also difficult because it is not always possible to easily return to it when we actually need it
even in the case of well-discussed topics, their independent translation into one's own context is not always obvious
All this is also associated with the problem of trying to tailor content to as wide an audience as possible. For this reason, it is necessary to include additional definitions or sources, which reduces the space for deepening the main thread, which may be important for people familiar with the topic.
Context of Large Language Models
Similar to publications available on the Internet, the base knowledge of large language models is relatively static and resembles a "snapshot" from a given point in time. However, this is the default state, which has already been addressed by using knowledge provided in the context of a query to the model. In short, it means that in addition to the message sent to ChatGPT, we can provide additional information that can be used when generating responses by the model. In a sense, this is referred to as "short-term memory," because this data is only available within a specific query.
In practice, it looks like the additional context can remain hidden from the user and be loaded programmatically, which makes the interaction natural. Specifically, the content of the conversation is analyzed, and for each subsequent query, the context is loaded to help generate further responses. Here come into play search engines, such as Algolia or vector databases, e.g., Qdrant, whose task is to find relevant sets of information. It is not difficult to guess, however, that such a task is not the simplest. We will take a closer look at this shortly. Meanwhile, let's look at the example below of external data attached to the context.
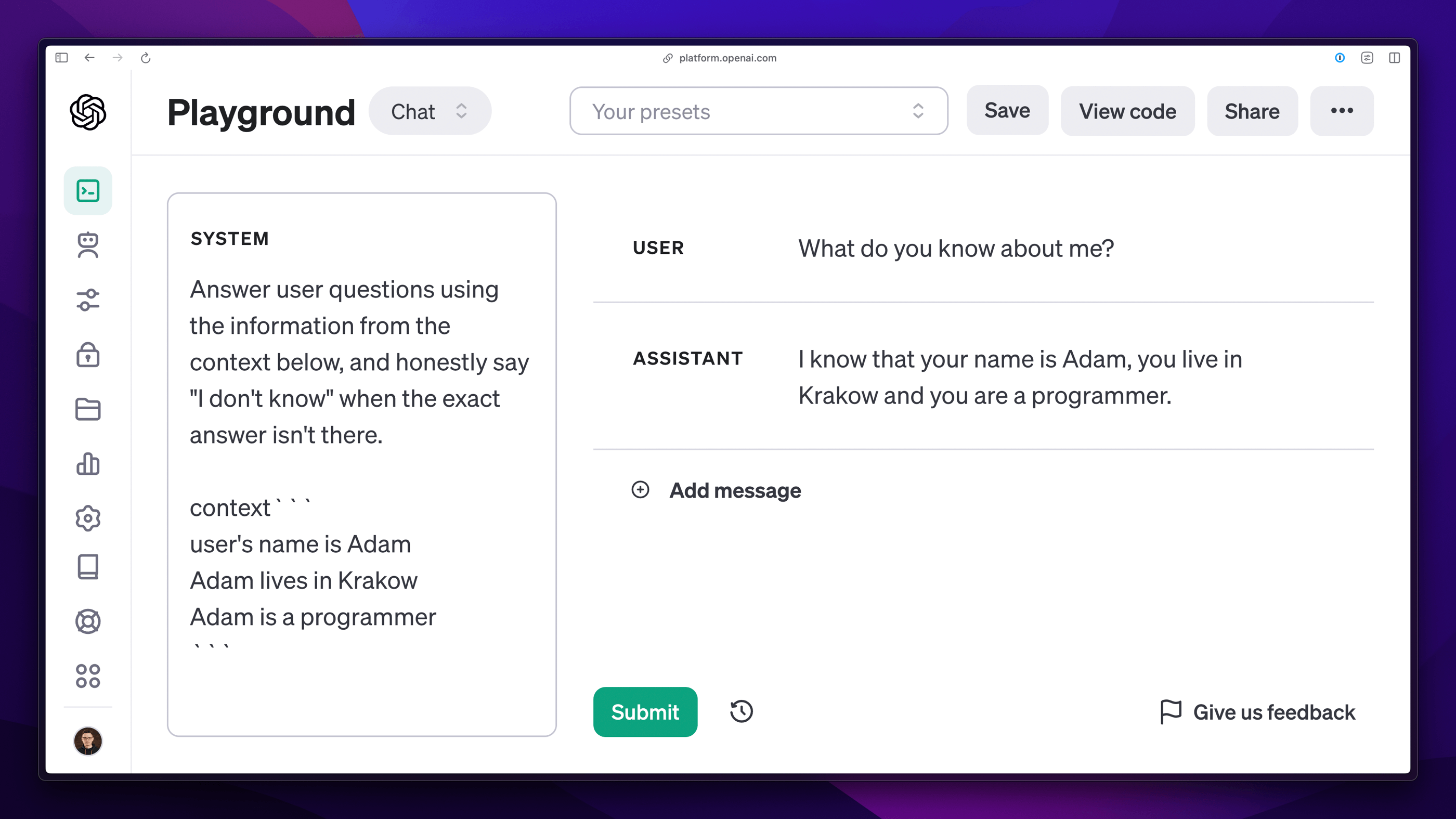
The amount of content that can be passed to the model in this way is limited. Although we observe an increase in the permissible limit, we are still interested in keeping the context as short as possible due to costs and the model's attention, which can be easily distracted, as we can also read in the publication Large Language Models Can Be Easily Distracted by Irrelevant Context
A simple example could be a situation where different fragments of content originally unrelated to each other are loaded into the context. When we join them directly with the remaining fragments, they will give the impression as if they formed a whole. Then, even a human may find it difficult to distinguish which information is actually relevant for the current conversation and which is not. As a result, the answer given to my earlier question, this time, is only partially correct because it contains additional information that is not true.
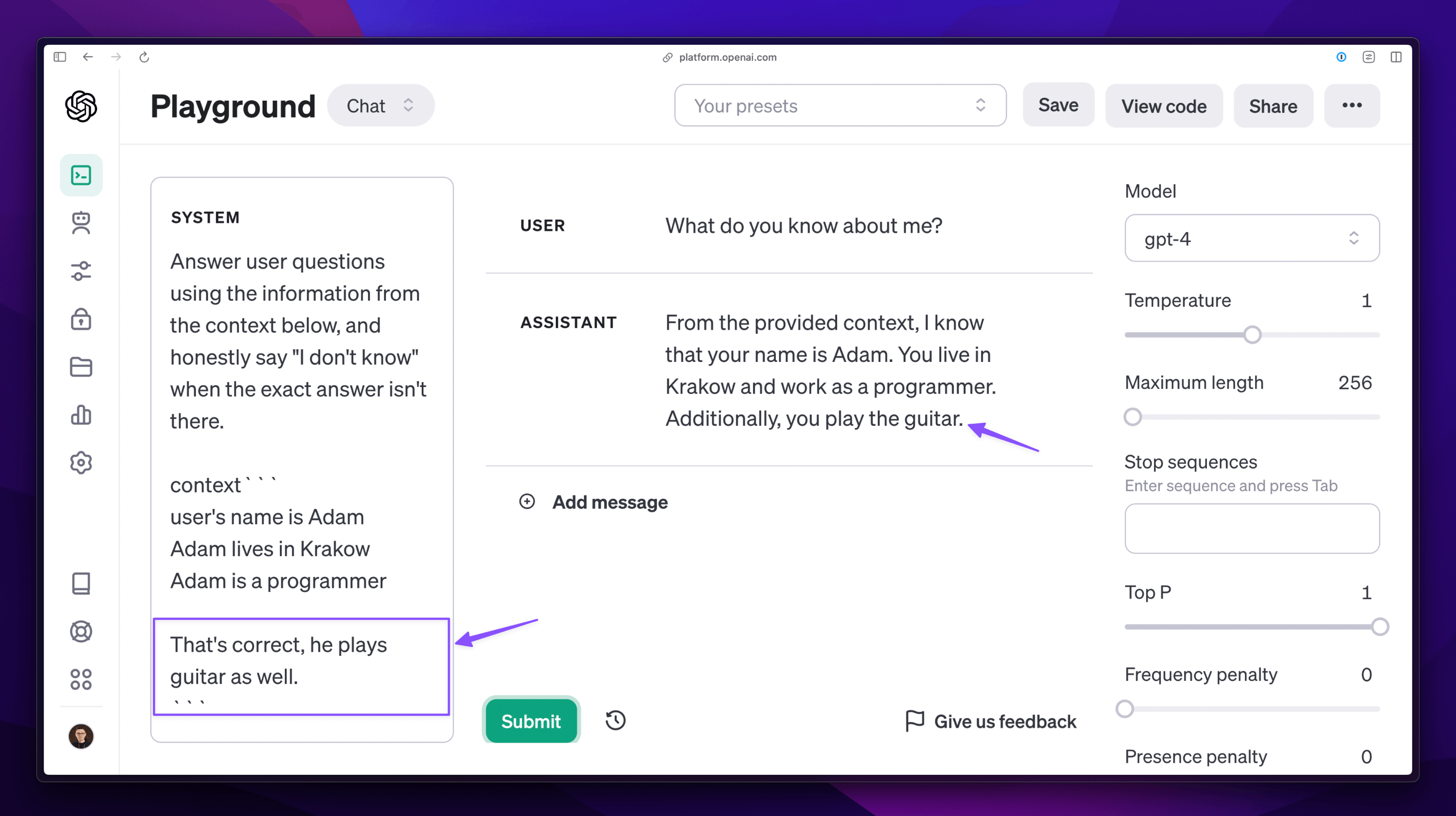
In the case of production use, such a situation is unacceptable and seriously undermines the user's trust, who cannot rely on it and may be easily misled.
However, if we mark the information about the origin of individual memories, the chance increases that the model will correctly use them during the conversation. Such marking of data does not happen fully automatically and is something we need to pay attention to when creating content and later preparing it for the needs of Large Language Models (LLM). The case presented below shows how the behavior of the model changes when the attached fragments are correctly marked, and the instruction is enriched with how to use them.
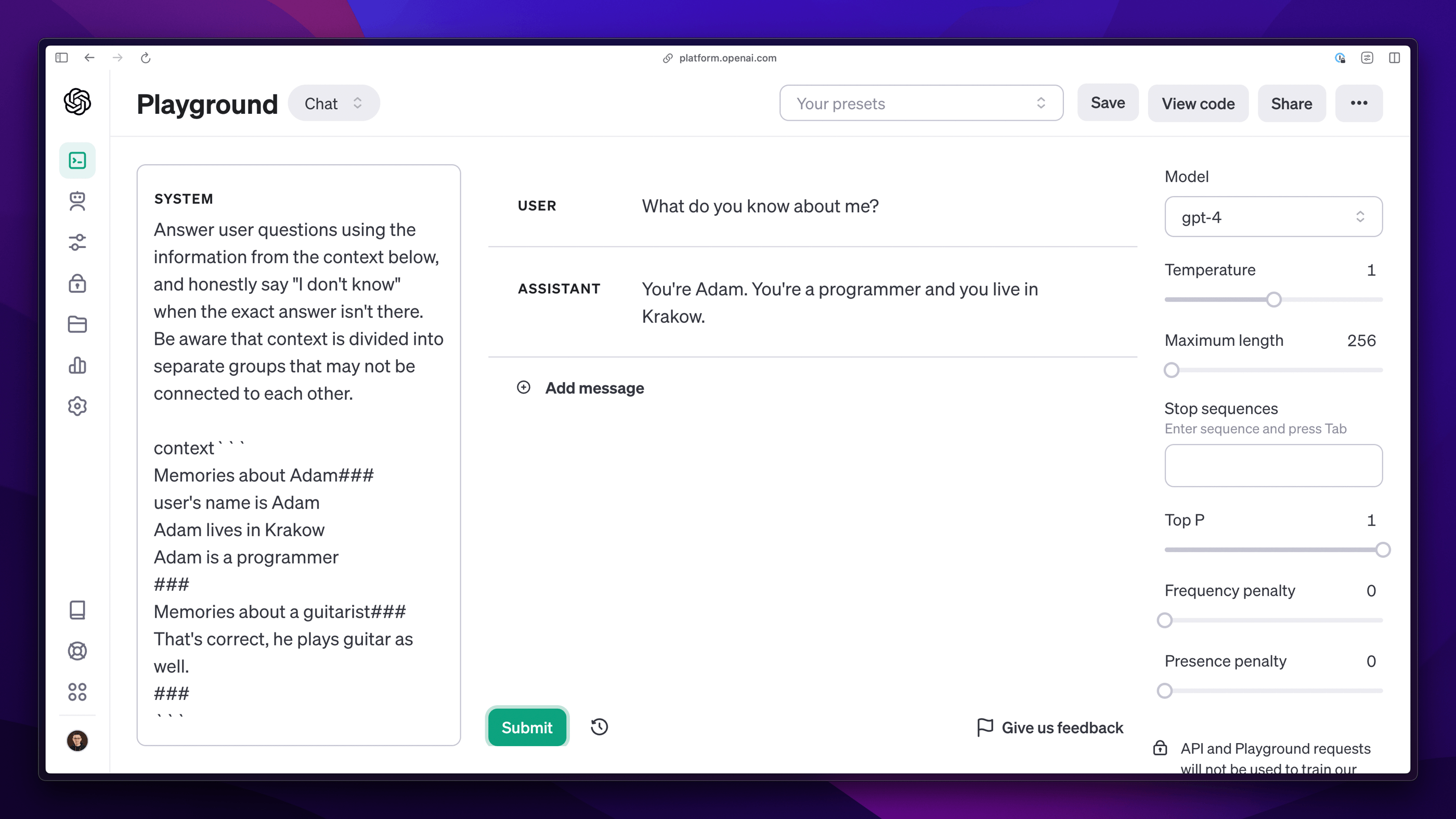
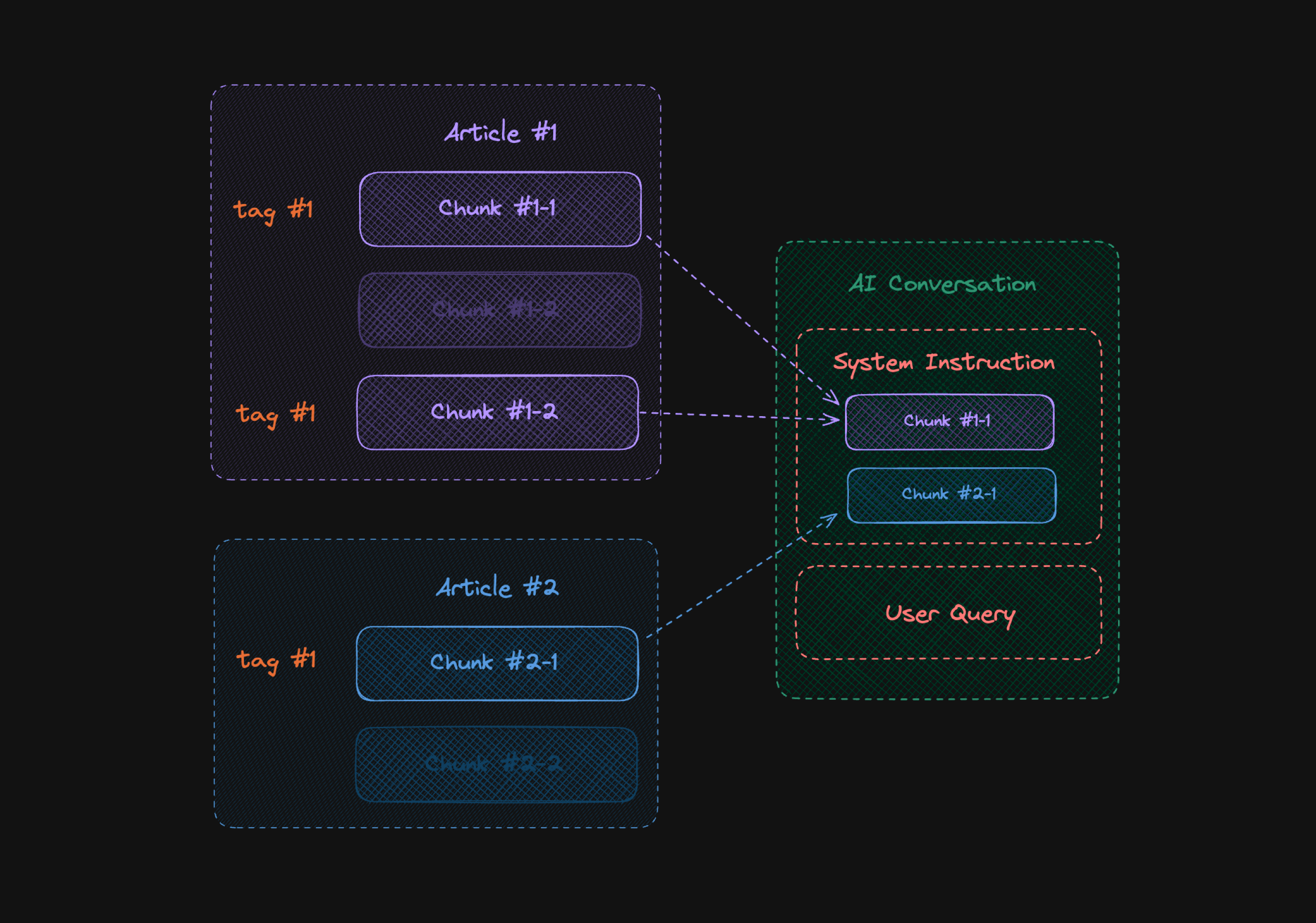
When we transfer this to a diagram, we see how our data sources focus not only on the content itself, but also on so-called metadata describing the origin of each fragment.
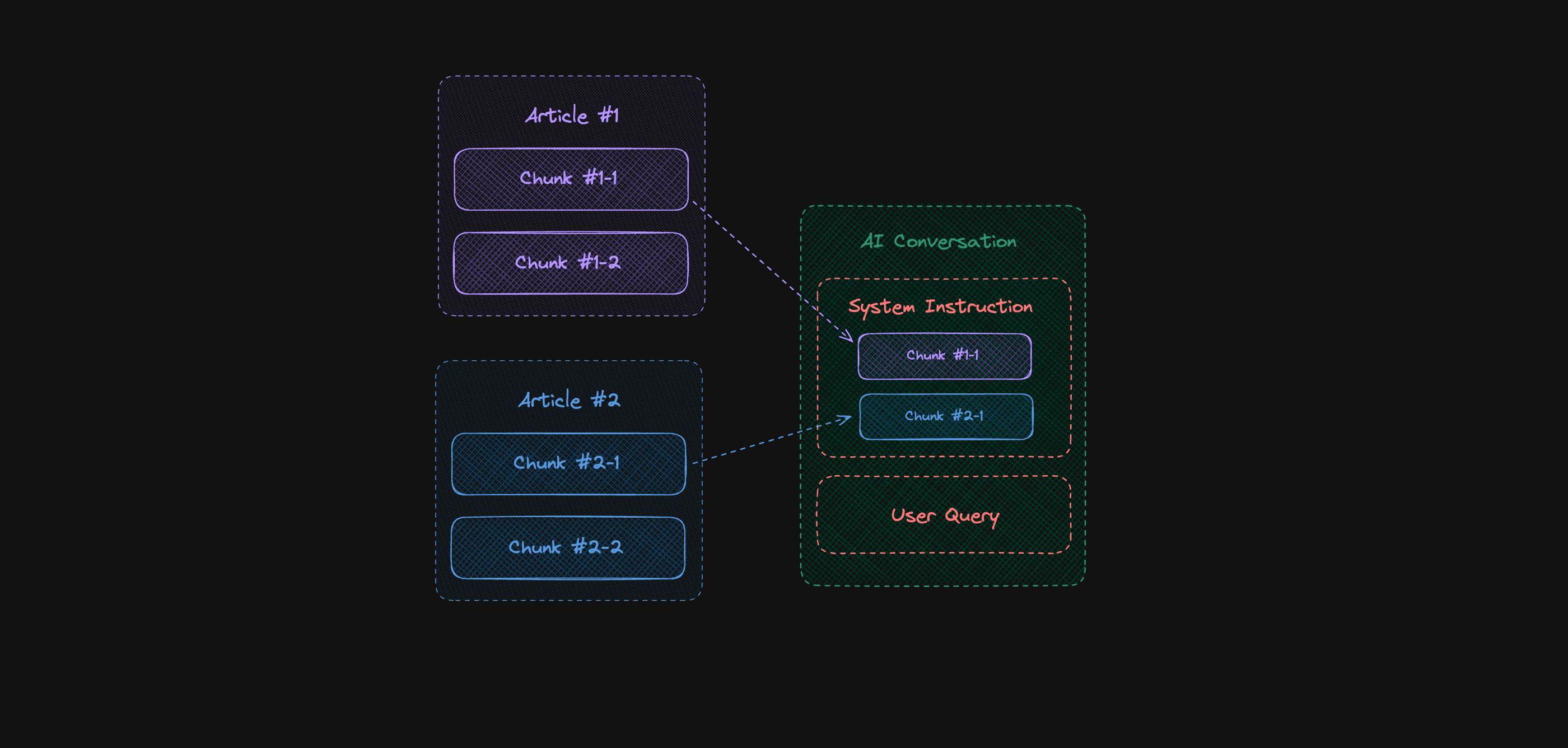
Such description of data sources facilitates not only their embedding in the context of a query, but also in the search process itself. As is known, searching through fragments must consider some kind of association with the search phrase. When we divide a document into smaller pieces, a common case will be when a definition is split, and its content ends up in two different places. Then, based on the content alone or even metadata containing information about the origin of the content, we will not be able to effectively find all the required data. To address this problem, we can use a system of tags, which we can consider when building context.
The diagram below reflects this, where the user's query has been associated with tag #1, and the related fragments have been included in the query context. Again, we have increased the chance of obtaining a correct response from the model. At the same time, we see that the organization of content and its subsequent search are not obvious.
At this stage, it is clear that although LLMs are capable of understanding natural language and generating content, combining them with our data is a demanding task. The question is, why should we do it?
Dynamic, Personalized Content
A few weeks ago, one of the training programs I co-created, AI_devs, came to an end. Its main content was text, which by default was available in a static form and had exactly the features we discussed a moment ago.
At some point, there was a significant change in the form of a simple application that allowed voice interaction with the training content. If the user's question pertains to the training content, the response will be generated in a personalized form. Below you can see how the system indicated specific lessons in which the topic of embedding was discussed.
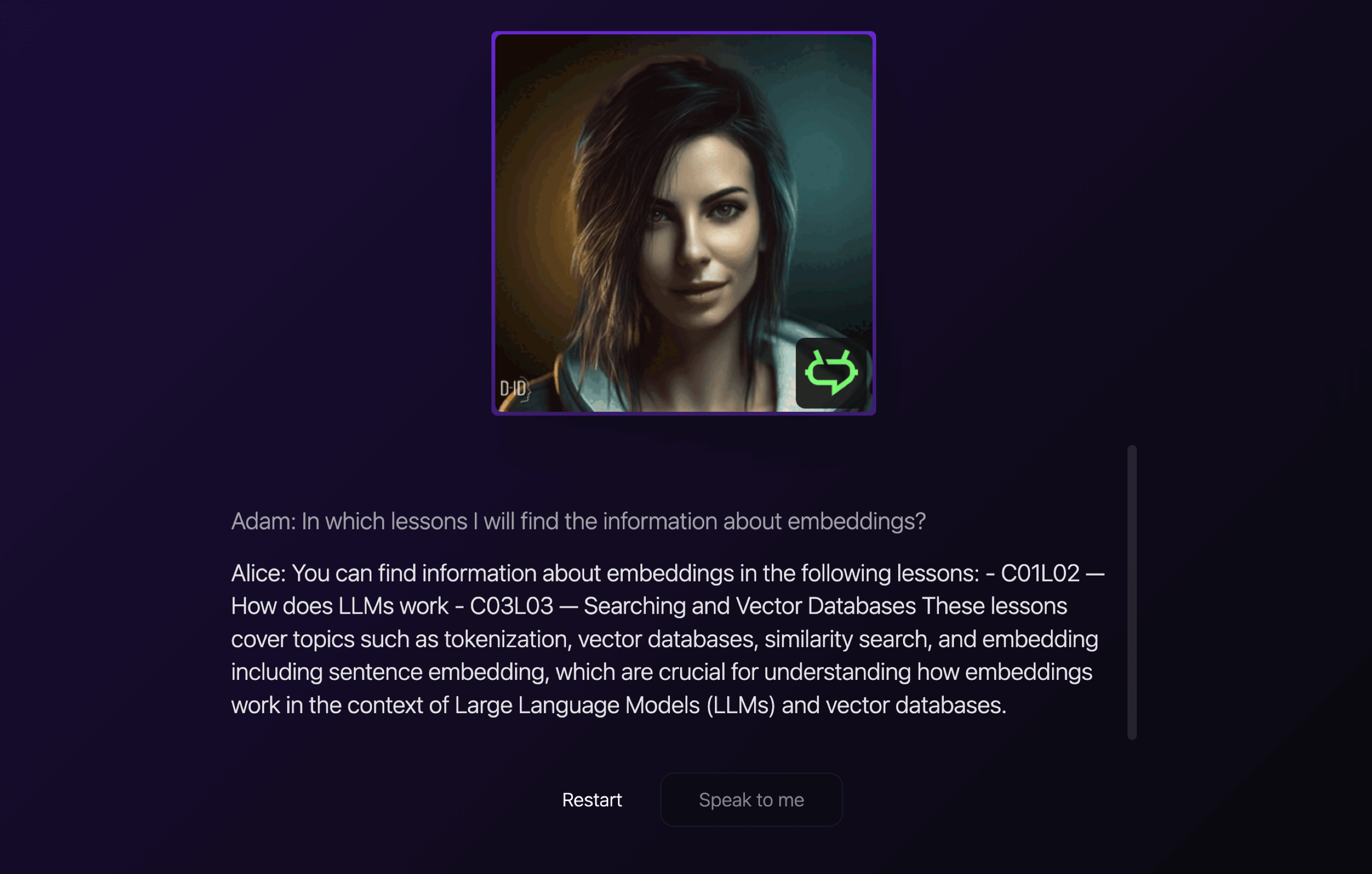
This can go a step further, as the question does not have to be about searching the content but can also resemble a question asked to a teacher.

Questions can also cover entire processes, which may also have been discussed over various training lessons. Considering the volume of the main content, which was ~500,000 characters, the ability to freely interact by simply asking questions becomes incredibly useful. Moreover, the system can be designed in such a way that, in addition to the answer, it also attaches links to the cited fragments, making it easy to reach the source.

Looking at the above examples, it is easy to imagine a situation where the response includes not only the original training content but is also capable of using, for example, the documentation content of the discussed tools.
The whole creates a personalized experience that significantly changes the way of interacting with content, in this case, training. However, if we consider a slightly broader context and consider all the publications of selected creators or even collections covering entire fields (e.g., law), we get a system that can be useful not only at the learning stage but also in daily work.
To complete this picture, we can also include an entirely new approach to designing interfaces, which I wrote about in the post User Interfaces may change because "AI knows what we mean". In this way, we are shaping an image of AI with which we practically have free interaction, talking about the materials that interest us, whose content can be tailored to our needs and current situation.
Preparing Content for LLMs
In the post Plain text is what you need, I presented the advantage of open formats for content that can be used by LLMs. You now know that the easy access to document content mentioned in it is important precisely from the perspective of the operations we have just gone through.
Having been through several larger integrations of large databases with LLMs, I can say that the format of the documents we work with is the foundation for creating content intended for interfaces operating with AI. There are also a number of additional points that I pay attention to.
Keywords: discussing topics should take place in roughly the same area of content. If this is not possible, it is necessary to clearly emphasize the keywords that will help identify a given topic. For example, instead of writing "the third topic discussed," it is better to write specifically "the third topic, which is (...)," because the presence of the title will allow correctly associating different fragments with each other.
Audio/Video: when using images and video, it is important to include their descriptions and/or transcriptions, which can also provide context for a query. The descriptions themselves and the way of speaking in the videos should also be developed so that an LLM without free access to the image can "understand" the general message.
Hierarchy of Headings: most of the metadata allowing for the organization and later searching of content can be generated automatically based on headings. For this reason, it is worth ensuring not only their presence but also their content, which should directly relate to the associated fragment.
Additional Materials: applications such as Notion allow you to attach additional materials or images through simple drag & drop. Unfortunately, such added materials are stored on Notion's servers, and access to them is only possible for logged-in users. For this reason, it is worth remembering to use applications like Dropshare, which facilitate uploading files to your own server and then easily embedding links in the text.
Organization: the way of organizing content according to categories or more complex structures can also be used to connect it with LLM. Then the system can classify queries (and the context of the conversation) and move through the structure we have developed to precisely find information.
It is not difficult to notice that the above points concern textual content. This is natural because large language models handle it best. Therefore, if we care about connecting LLMs with other formats, such as audio or video, we currently need to take care of creating (or generating) their textual versions. Then the user interface can still navigate, for example, through video material, but the LLM itself will use text. We can also use AI for such a transformation, for example, Whisper models or GPT-4 vision.
Quality Content is Important
Throughout this post, I have mentioned a "system" responsible for integrating content with LLM. Currently, tools that enable such a process to be carried out in a relatively simple way are just beginning to emerge on the market. At the same time, we have available solutions that allow for "conversations with a document" or larger databases. They usually rely on general assumptions and content reading techniques that will only work in selected cases. When we care about increasing the precision of statements or creating our own interface that allows interaction with the content database, the only solution currently is to build it practically from scratch.
It is easy to see that all this currently poses a great challenge. There are still no answers related to the details of systems capable of effectively combining content with LLM and building useful interfaces for them. On the other hand, we see that creating a solution that enables conversation with training content or even a larger knowledge base is possible now.
Generative AI has the potential to revolutionize our engagement with content, including works from our favorite creators and industry insights. Recognizing this, I'm shaping my present and upcoming content to eventually integrate with the advanced features of large language models.
"Content is The King" remains relevant, and its role is growing even more, even in the era of generative artificial intelligence. It is hard to say how long this will last, but little suggests that quality content will lose its significance. At the same time, it is difficult to deny that AI can already change the way we interact with information.
Have fun,
Adam
Hi Adam, great article!
Which storage do you use for Dropshare to upload files?