

Non-Obvious Prompt Engineering Guide
There are many prompt writing tutorials available. In this one, I share unique insights not found elsewhere.


Autoregression is a beast
LLMs are autoregressive, which means they generate content by predicting the next word fragment (called a token) based on previous text. This process is similar to speaking in syllables:
This
This is
This is an
This is an ex
This is an exam
This is an example.
The problem with such content generation is that if you choose a token incorrectly, you can't remove it. What's worse, its presence affects how subsequent tokens are selected. Here's proof:
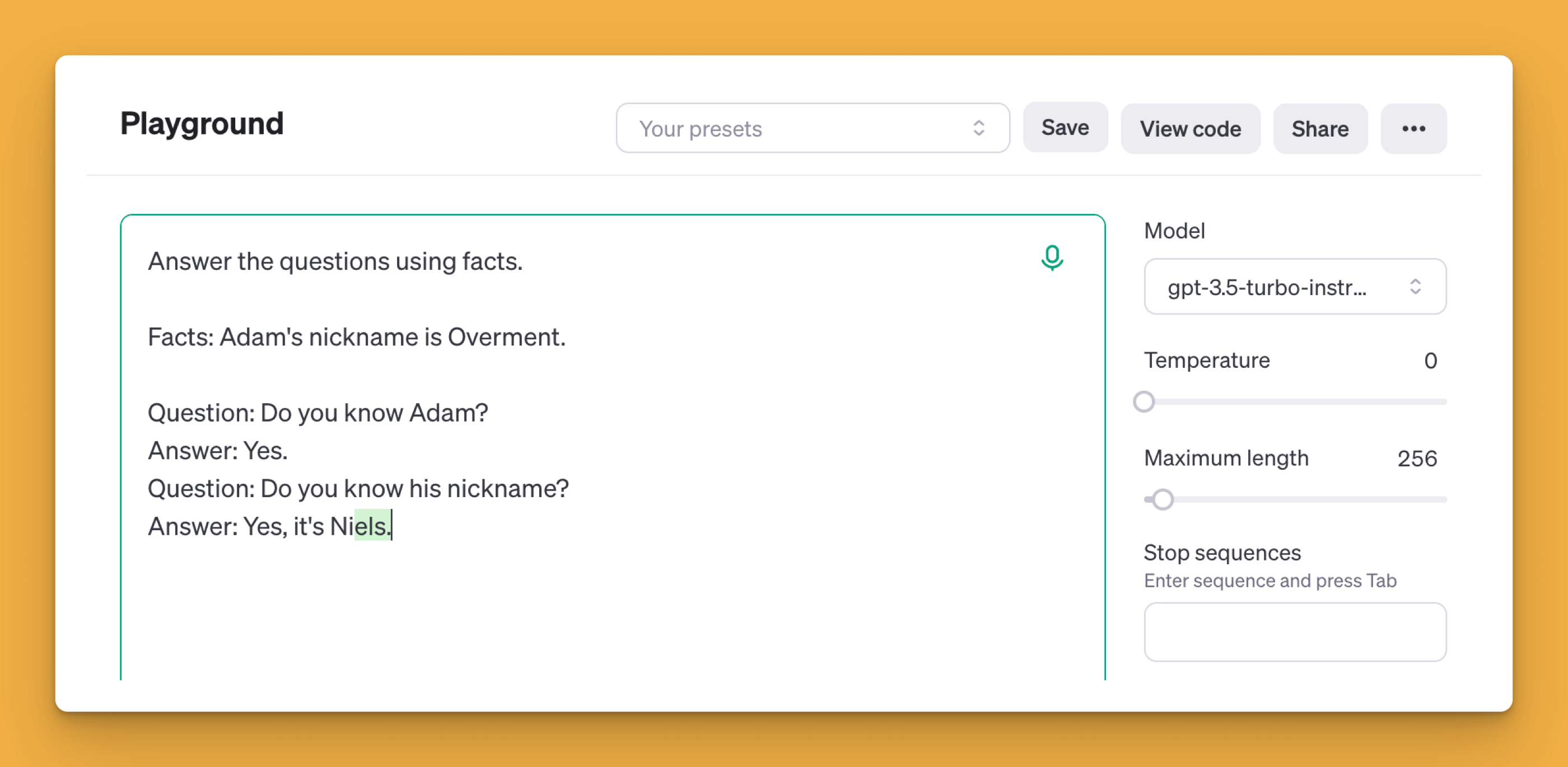
I showed you this using Completion mode and the GPT-3.5-turbo-instruct model. But models like GPT-4 or Claude 3.5 Sonnet also have this issue. It's just hidden behind the ChatML layer, which divides the conversation into "User" and "Assistant" roles.
Of course, if I hadn't manipulated the content, the answer to the asked question would be correct.
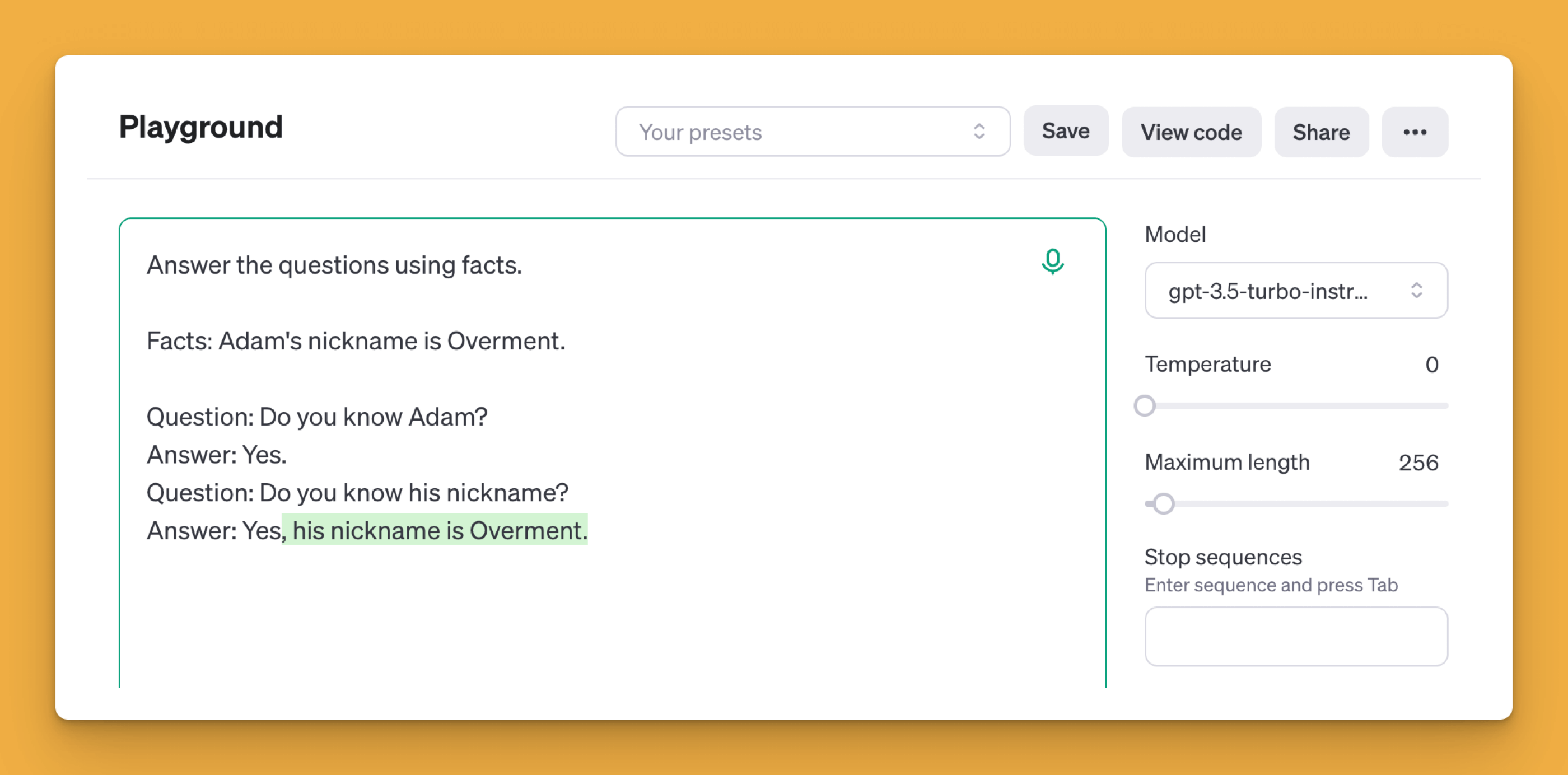
It is clear, therefore, that the existing content influences the generation of subsequent tokens. In the case of ChatGPT or Claude.ai, we're talking about the entire conversation so far (or its compressed version due to the input-token limits).
Conclusion:
The generation of subsequent tokens is influenced by the entire content of the interaction so far. This includes the system prompt, user messages, and assistant responses.
An incorrectly generated token has a negative impact on the model's further responses and cannot be removed by the LLM itself.
The content (tokens) provided by us in the system message and in the user message thus enable us to steer the behavior of the model
Prompt Engineering is therefore about increasing the probability of obtaining a correct answer by steering the model's behavior.
More balance
We don't know exactly how LLM selects the next tokens. That's why I don't talk about "controlling" the model's behavior, but rather "steering" it. But how?
If your interaction with LLM looks like this:
USER: [your content]
Assistant: [a concise response addressing your query, with brief explanations and relevant examples]
The language model has far more influence on the interaction than you do, as it produces more tokens, which affect the way subsequent ones are selected. Your goal (usually) will be to strive for a situation where the number of tokens delivered by you will be similar to those generated by the model.
When you think about it, it will become clear to you what the very popular prompting technique called Chain of Thought and Zero-shot CoT are all about.
Conclusion:
You have the most control over the tokens you provide yourself. Their presence affects the tokens generated by the model. This is how you steer their behavior in the desired direction.
Tokens can come from the model's responses to specific questions or instructions before the main task. For example, you could ask for definitions of key issues needed to achieve your goal.
Latent Space
Speaking about prompt engineering techniques, I should mention David Shappiro's post on "Latent Space Activation". I'm referring here to this file.
Note: While I can't verify his thesis, it has profoundly influenced my approach to working with LLMs. It effectively generalizes most prompt design techniques available today.
A few weeks ago, Anthropic Research published a post titled "Mapping the Mind of a Large Language Model". This post appears to discuss the same topic as David's work. Particularly helpful is this visualization:
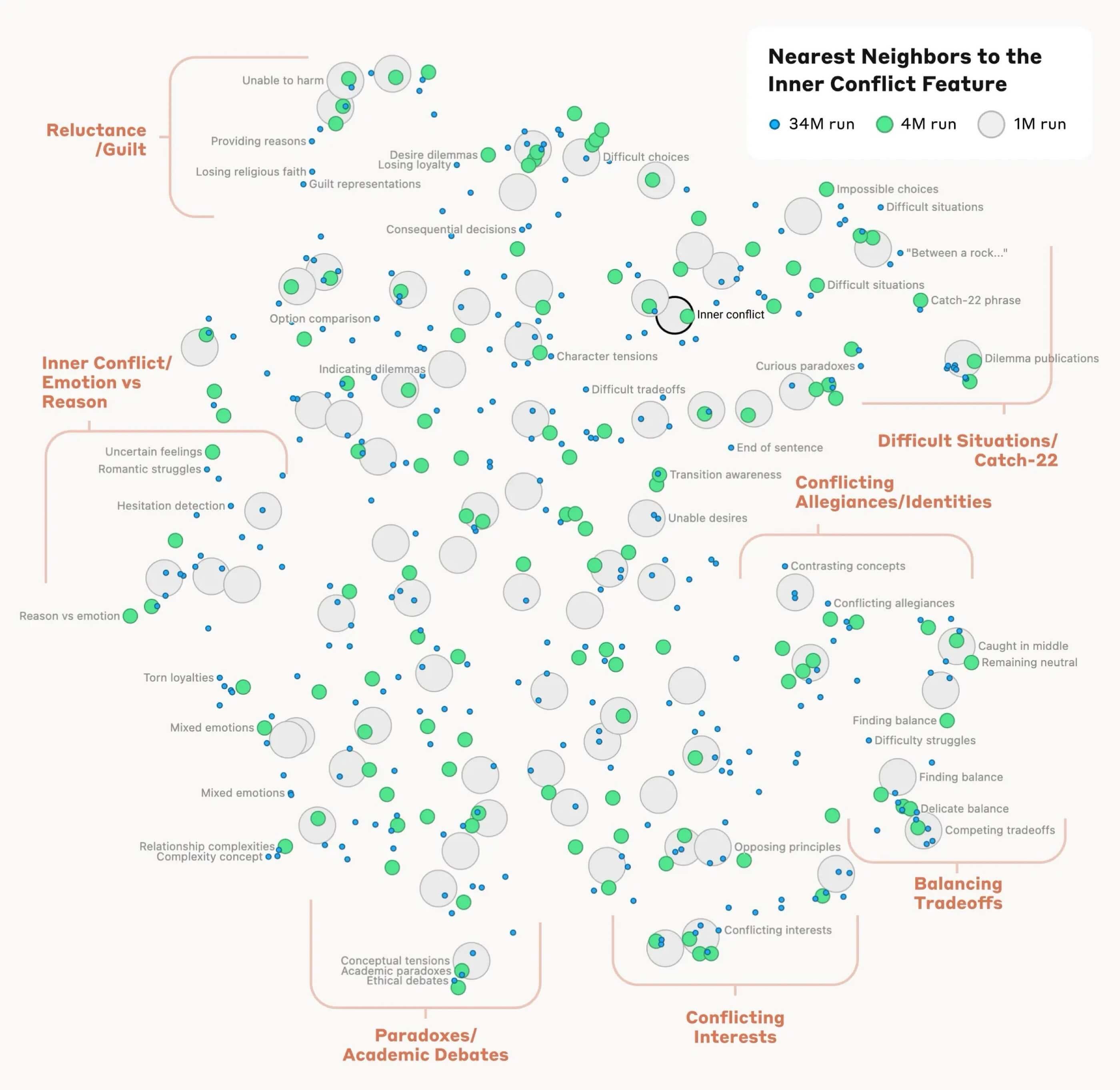
Based on the above information, we can observe that invoking specific concepts, characters, and definitions during interaction with the model activates areas associated with them. A practical example could be the instruction I use to improve the readability of texts I write:

I use terms such as "Gunning Fog Index, SMOG, and Flesch-Kincaid" which are directly related to the issue of readability and text comprehension level. According to my understanding, these terms make the LLM "direct its attention" to areas that help it better evaluate the text and its transformation.
Beyond striving to activate selected network areas, it's also worth remembering that currently GPT-4+ class models (according to available knowledge) are based on the Mixture of Experts architecture. This means they are built from smaller models that are connected together, and during inference, only a part of them is active. Unfortunately, we don't have any information about the specific architecture and method of model selection, but it's worth keeping this fact in mind.
Conclusion:
During interactions with the model, you should be interested in directing its attention to specific areas related to the topic and techniques useful in a given situation
Broken Complexity
The need to break down complex problems into smaller steps is probably already familiar to you, because it's useful for humans too. In the case of LLMs, we talk about "Let's think step by step" or "Let's verify this step by step". We could read about the first one in "Large Language Models are zero-shot reasoners"
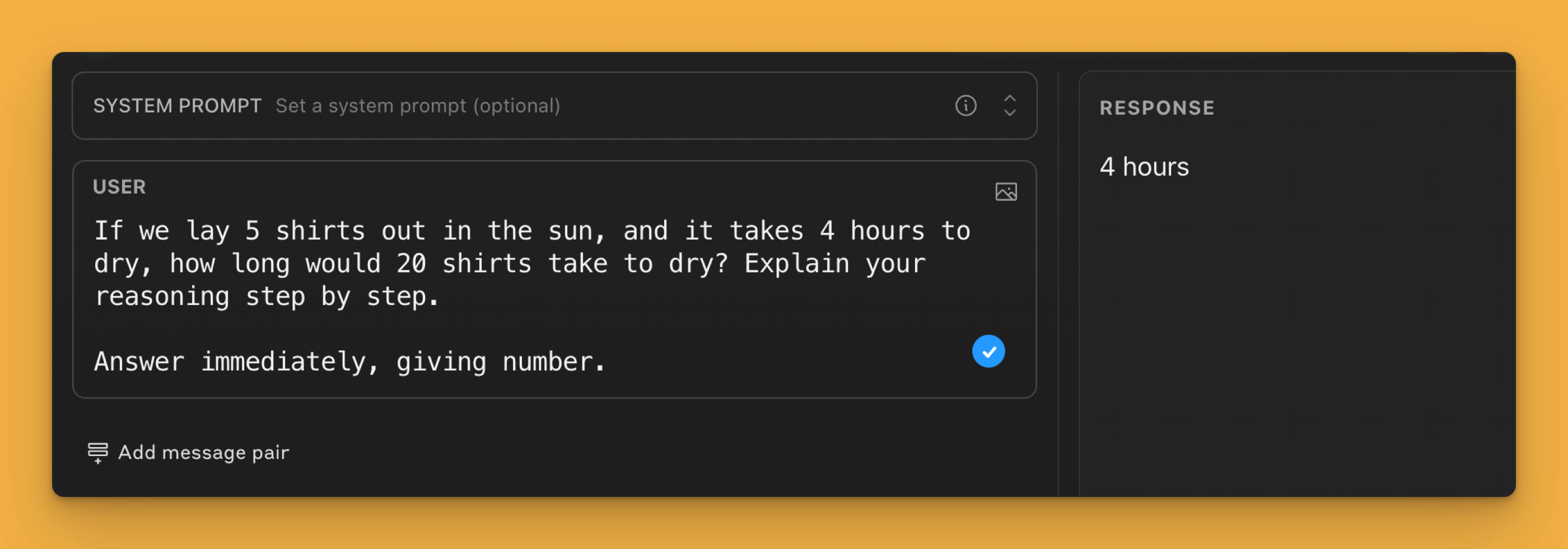
A fairly common problem is the puzzle about drying shirts in the sun. Models such as GPT-4 incorrectly assume that the number of shirts affects the time needed to complete the task. The correct answer is "4" or "the same", whereas according to GPT-4 the time increases to 16 hours.
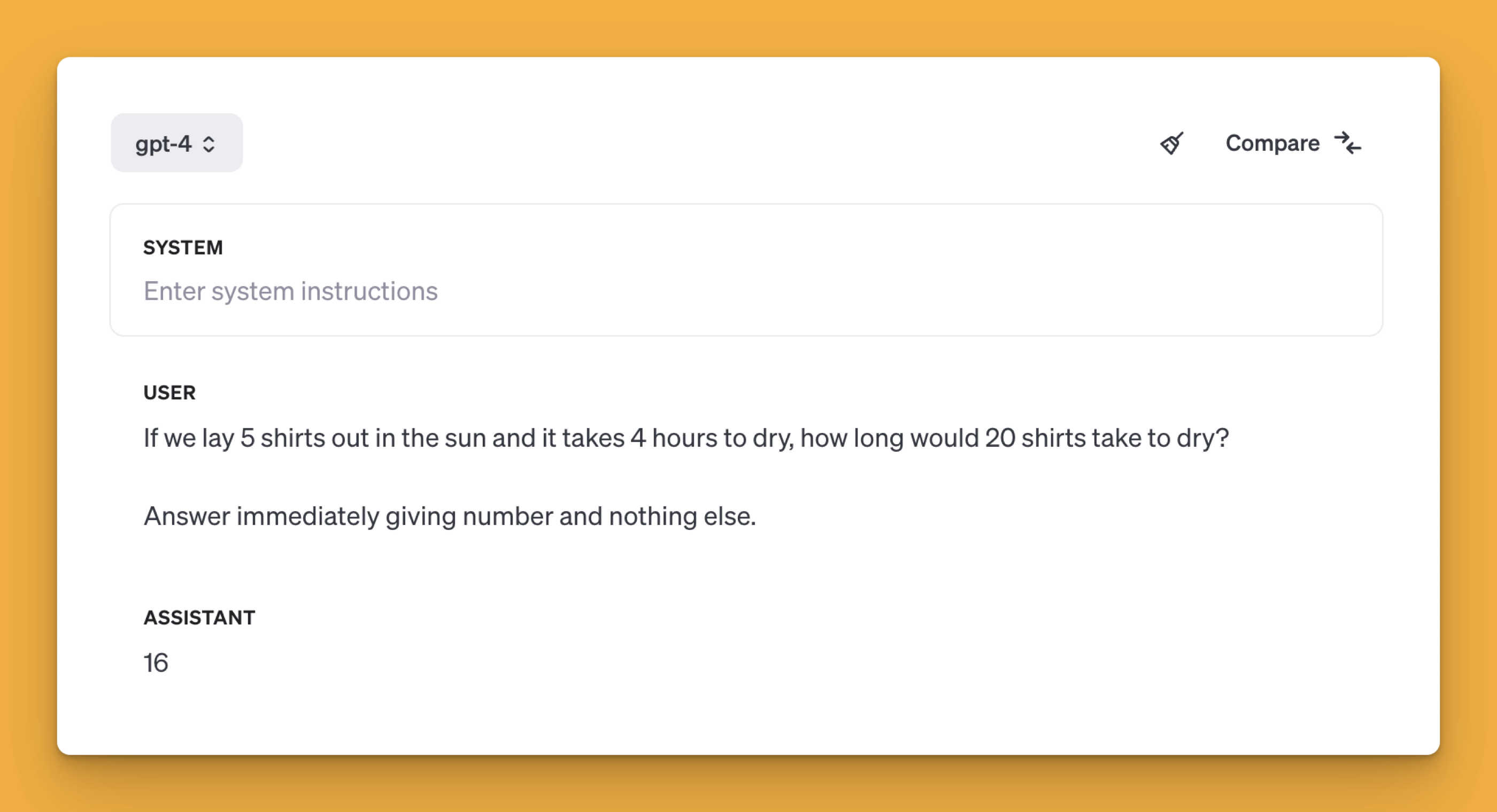
If we break this problem down into smaller steps and provide feedback on each of them in between, the GPT-4 model will be able to handle this task.

It is interesting, however, that the latest models, such as GPT-4 or Claude 3.5 Sonnet, can solve this problem without hesitation. Despite this, the principle of breaking problems down into smaller steps still applies, it's just necessary in the case of more complex reasoning.
Conclusion:
LLMs reason "out loud" by generating tokens
It is in your interest, then, to make the LLM generate longer responses for more difficult tasks...
...you must, however, ensure that this reasoning is correct and either specialize the system in solving a specific type of problem, or include a human in this process
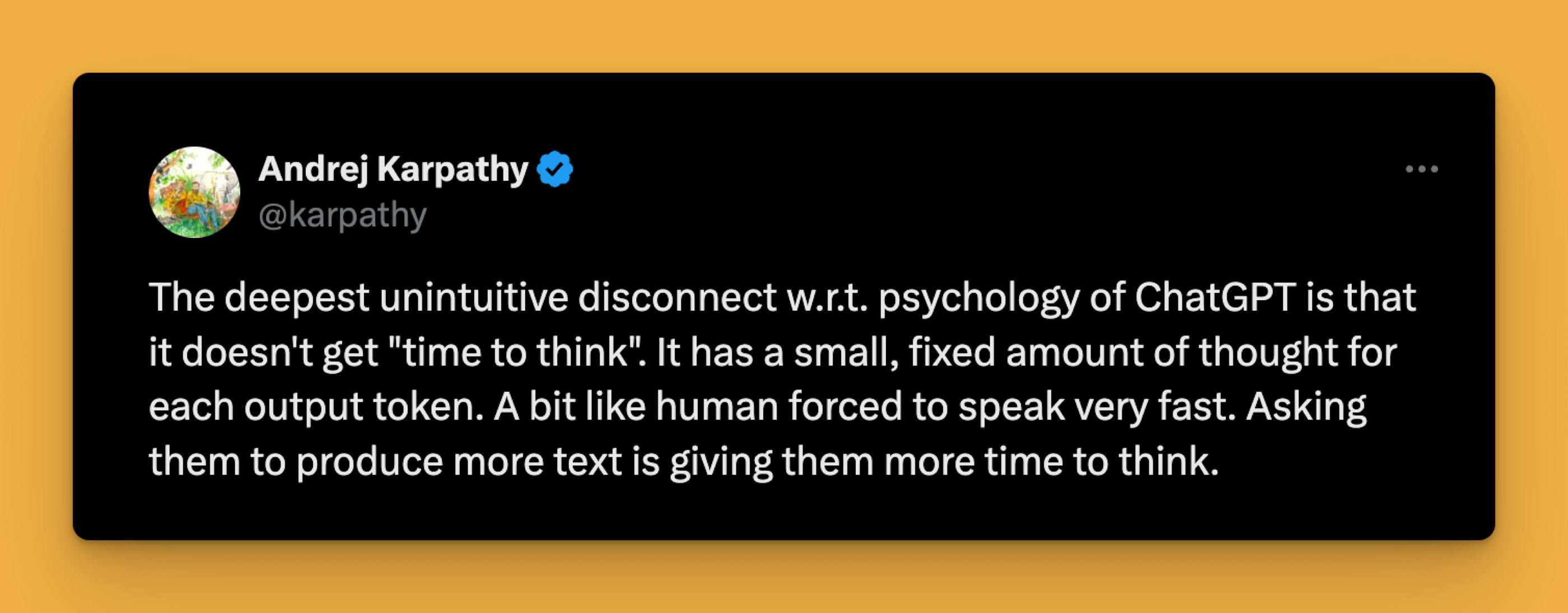
Too little time to think
"Let step" is therefore not just about breaking down the problem into smaller steps, but also about extending the time for "thinking" by generating additional tokens.
Reasoning does not have to take place within a single interaction with the model, but can be broken down into multiple stages. For example:
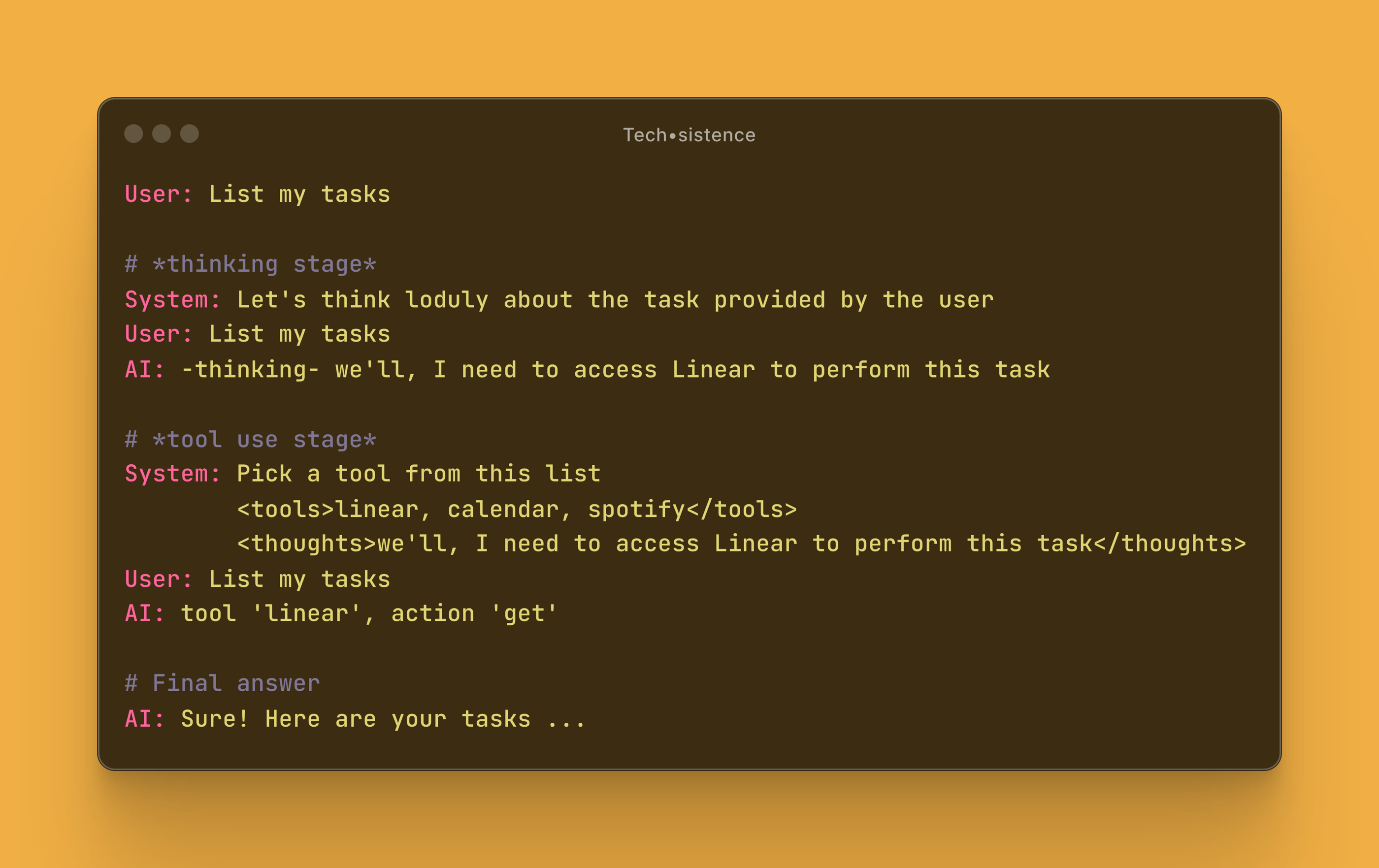
In this example, the interaction with LLM has been enriched with additional steps. Before selecting the tool needed to provide an answer, we added a step generating "thoughts" about the action necessary to take. The result of this step was passed to the next one as context. In practice, this way, we increased the probability of selecting the right tool by providing tokens that increase the chance of indicating the name "Linear".
Conclusion:
The model's reasoning can take place in many separate steps
Additional steps may include verifying current progress
Generated responses may serve as context for subsequent steps
Similarly to the way tokens are selected, the quality of results in subsequent steps depends on the previous ones
Order matters
Combining LLM with application logic or automation almost always requires generating a structured response in YML or JSON format. The model's task is then usually to transform the data into the required properties. In the example, "name" and "category" are key attributes. The classification is straightforward.

In practice, classification can be more complex and depend on extensive category descriptions or even relationships between them. Then, to increase the likelihood of appropriately describing the data, we can arrange them in a suitable order.

Here, in contrast to the previous case, the task name precedes the category name. This means that its content influences the selection of subsequent tokens, reducing the risk of error.
Conclusion:
Write prompts that guide the model to generate responses in an order that helps select suitable tokens
Dead ends
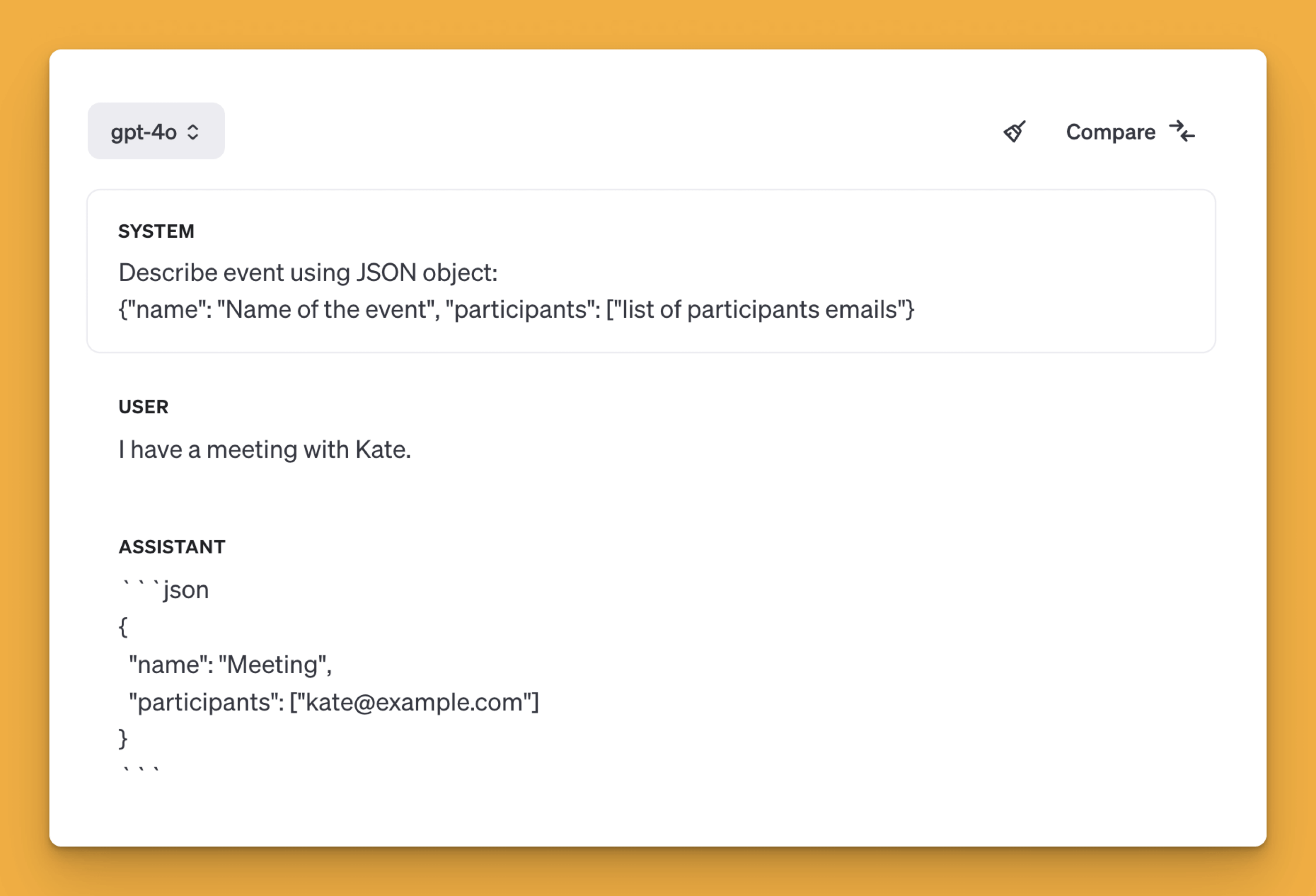
In the example concerning task classification, I deliberately included one more category, "unknown". I did this in case of situations where classification is impossible. Additionally, the instruction may also state that when the model is not sure which category to choose, it should indicate this last one. Then we will be able to assign the given task manually and reduce the risk of incorrect classification. Otherwise, the risk of confabulation is very high.
Conclusion:
Provide default and fallback values and tell the model when to use them
Precisely specify the source of information
Separators
Advanced prompts usually consist of several sections, such as a set of rules or additional context. These sections must be clearly separated from each other to reduce the risk of confusing their content.
For a long time, separators such as ### or """ or ``` were used in prompt content. However, they don't work well with dynamic context, which may contain, for example, markdown syntax whose content may conflict with the separator. Even if an LLM can handle such a situation, such an extensive prompt becomes less readable for a human.
The approach that works very well in practice is using XML-like tags. I first learned about it from materials published by Anthropic, and since then I've started applying it in practice with very good results.
Therefore, in the case of more complex prompts or those using dynamic data, it's a good idea to use the following notation:
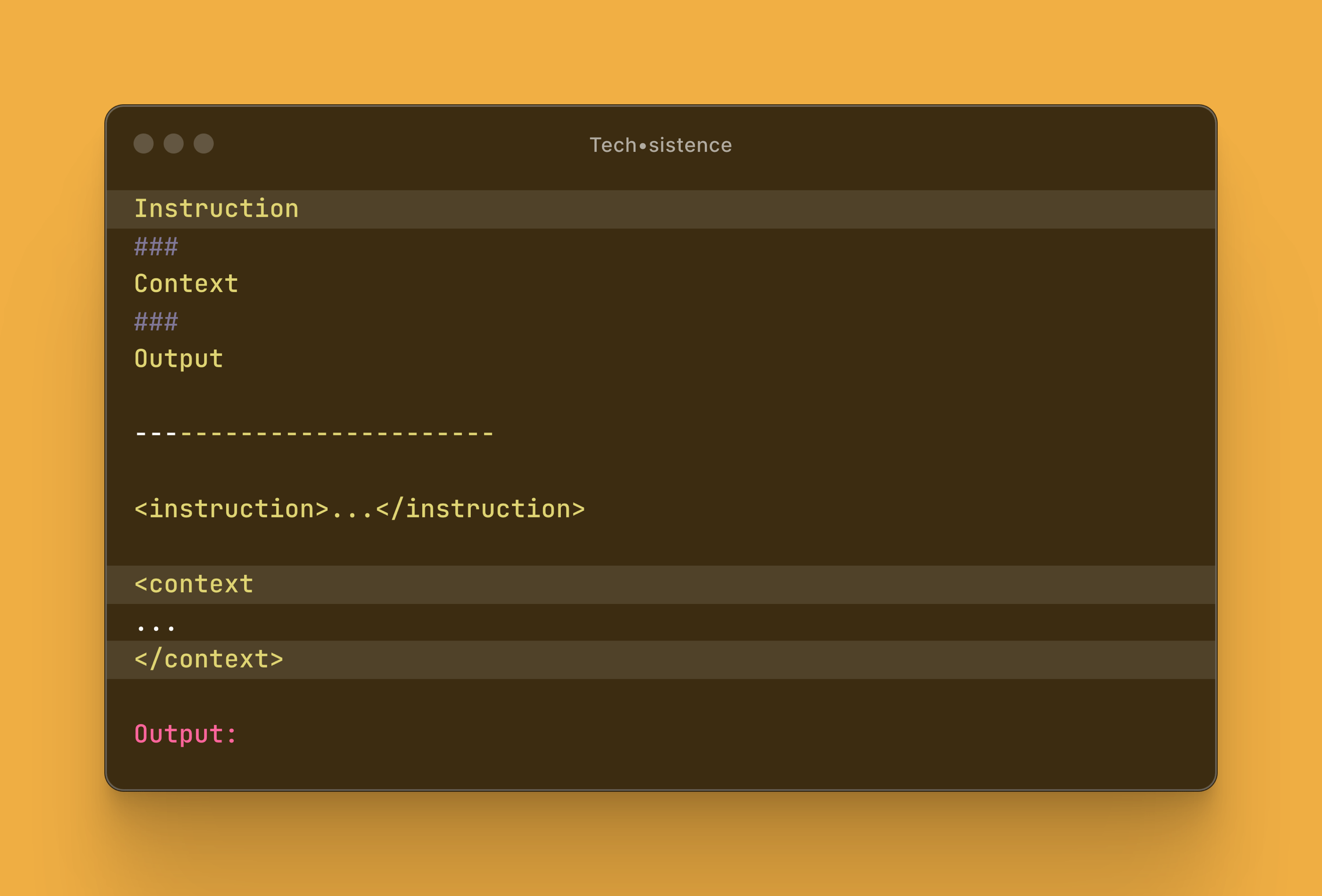
Conclusion:
Prompt sections should be clearly separated from each other in an unambiguous way
A clear division of instructions into smaller sections is important not only from the perspective of the LLM, but also for humans
Attention is limited
Language models use an attention mechanism, which, in simple terms, determines how important individual tokens are and what relationships exist between them. Unfortunately, we do not have precise knowledge about how the meaning of individual tokens is determined.
We can make some assumptions, but we must remember they may not be fully correct. One of them might be that more tokens potentially mean greater difficulty in determining which ones are the most important. On the other hand, if additional tokens are helpful in determining the meaning of the rest, their presence may have a positive impact on the model's behavior.
It may sound like something obvious, but in practice, it's very easy to provide more noise than actual information to the context. Increasing the effort associated with content preparation or making additional queries aimed at cleaning or clarifying data will almost always be advisable.
Conclusion:
The data that a human works on is not necessarily the data that an LLM should work on
Separating the signal from the noise is our priority
Shoot me.
One thing that undeniably has the greatest impact on model behavior is ... a list of appropriately selected examples. Carefully written instructions that refer to a list presenting the described behavior significantly increase the model's effectiveness in a specific task.

Choosing examples is a broad topic that's hard to describe briefly. However, here are a few key rules I always follow:
In the instruction, clearly indicate that the given examples only represent a scheme of expected behavior and present patterns. Emphasize that the model should pay attention to them and adjust its behavior accordingly.
Examples should present what has been written in the instructions.
Examples should also demonstrate behavior in unexpected situations or edge cases.
Examples should present situations where the model typically behaves differently than what we'd expect (e.g., avoiding adding extra comments or explanations).
Examples should thematically relate to the target content, but should not overlap with it. For example, when presenting task classification, choose tasks that will not appear in the target datasets.
Take care to diversify the presented examples to avoid biasing the model in one direction.
Conclusion:
Examples are crucial.
Don't write
Writing a prompt that correctly implements our assumptions is not easy. It is necessary to maintain high precision, appropriate vocabulary selection, and provide structure. Although it is not an impossible task for a human, it is certainly very time-consuming. Therefore, creating a meta-prompt with which we will develop subsequent prompts is a very good idea.
Here's an example of such a prompt that guides me through a certain thought process, and ultimately writes an instruction that I then connect in the Alice app (You can try this prompt out here).
The meta-prompt content contains rules and essential context in the form of useful phrases and prompt templates, as well as instructions for their application. As a result, during the conversation with LLM, we jointly design new instructions, as well as sets of examples for them.
With the help of a meta-prompt, it's also possible to introduce modifications to existing prompts. Here it's necessary to warn the model beforehand that we're about to provide a prompt which it should not follow, but rather work on its content.
Conclusion:
Don't write prompts alone. Work with the LLM to create them
Write a meta-prompt to help create other prompts
Use meta-prompts to generate sample data sets
What's next?
If you have to remember only one thing from this post, let it be the fact that currently LLM content generation occurs through predicting the next token based on the content so far, and always keep this in mind when working with models.
Meanwhile, we'll be returning to the topic of Prompt Engineering many times. If you liked this post, please share it on your Social Media channels.
Have fun,
Adam
This is an excellent and unique guide, thanks man! ✌🏼
Great article. I haven't encountered this approach elsewhere. I'll get my hands dirty and test it on my prompts now ;)
Good to see how rapidly your knowledge about LLM's evolved during last couple of months. Keep up the good work!