

Lost in the middle of an artificial maze
Driving LLMs through vector search, hybrid, through tree structures to graphs.

Imagine saying "hello" to an AI and receiving a response asking how you are doing in relation to the weather at your current location. Moreover, this is not a scenario from the future, but directly from my everyday life, as shown by a snippet of one of my conversations with Alice.
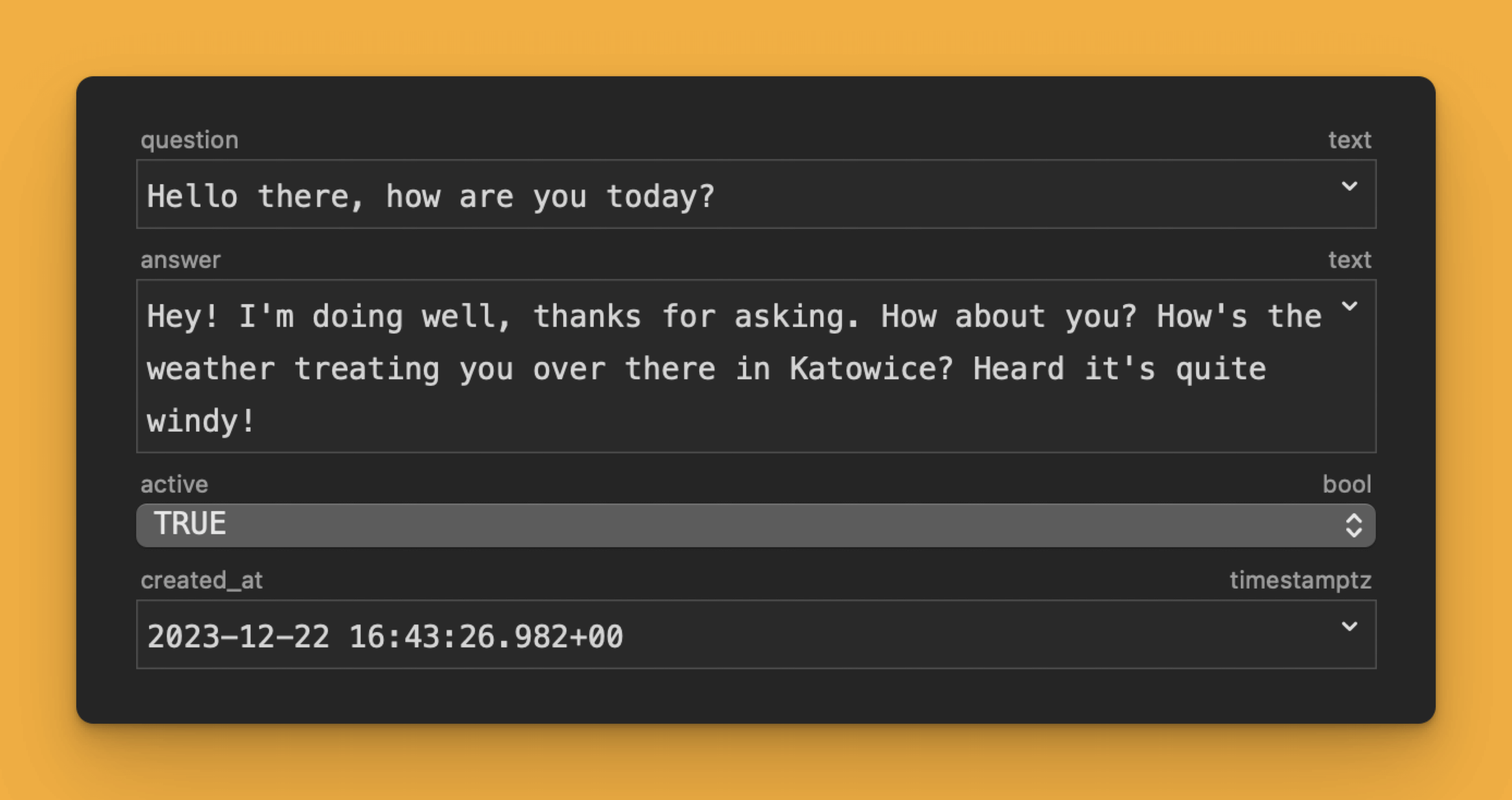
This means that GPT-4 was able to adjust its behavior based not only on basic knowledge but also on long-term memory, including access to external services and tools. Such behavior was not programmed directly in the form of "for greeting messages, check the weather and location," but is a combination of a fairly flexible application architecture with the capabilities of the model, reaching even into the area of Theory of Mind.

Building dynamic context
Typically, systems using long-term memory rely on vector or hybrid searching. However, this is not sufficient to achieve high effectiveness, especially when working with a larger set of diverse data. The reason is that by searching knowledge bases solely with the inclusion of keywords or even their meanings, we will get results consistent with that search, but the context of the current interaction and its possible further course will be omitted.

Considering the above simple RAG (Retrieval-Augmented Generation) mechanism and a situation where the knowledge base is unstructured, a question about "tasks for today" may only point to a memory related to "work," which in this situation does not concern the user. Meanwhile, the actual tasks will be omitted at the search stage because there is no match in terms of keywords or semantics.

Currently (early 2024), models capable of working with an increasingly larger context are appearing on the market. This means that we are able to include huge data sets within a single query, so theoretically the search stage can be limited or completely omitted. Although this will be very useful for many applications, it turns out to be insufficient even for the simplest tasks. This is illustrated by the following example, where the lack of any descriptions of individual memories meant that the model was not able to correctly identify them as the user's tasks. As a result, the response given does not make much sense.
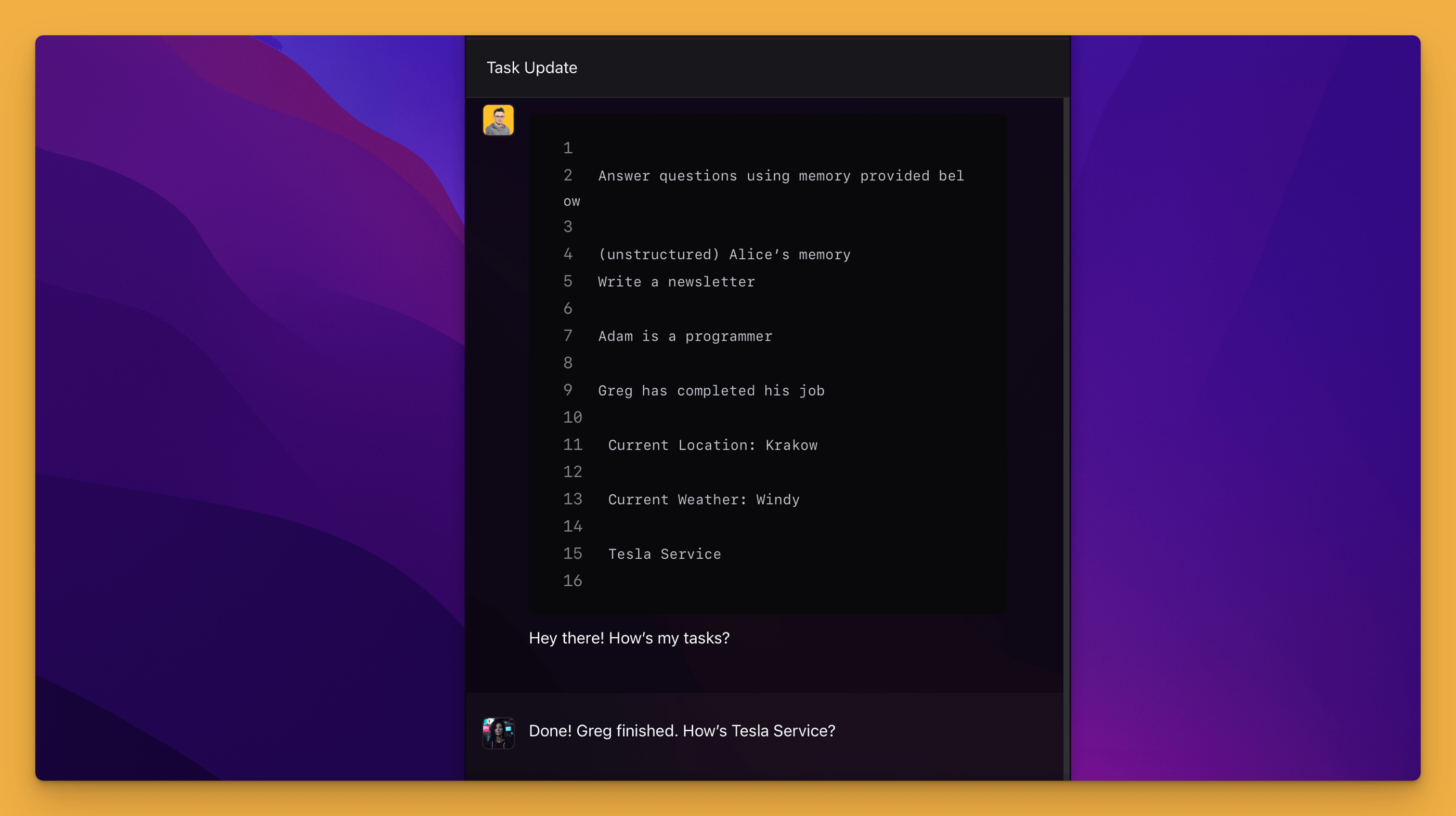
The situation changes somewhat when the stored memories are grouped together in some way, e.g., with the help of tags. Then the AI's responses to this question will be correct because we will give the memories additional context.

Such a solution again ceases to be satisfactory in a situation where, as users, we will have more than one project. Then a question about tasks related to one of them will be addressed incorrectly because the tasks are mixed.

Here again, we can develop the way of marking memories in the knowledge base and, besides the information that a given entry is a task, we can also assign it to one of the projects. However, in this situation, it will be necessary to take care of indicating the appropriate categories (or tags) both at the search stage and at the stage of saving information.
It is easy to imagine that the number of categories or tags will grow at a fairly rapid pace, and it is worth ensuring their consistency. In the process of organizing and recalling memories, we can engage an LLM. Then, at the memorization stage, AI will take care of properly describing the memories, and at the recalling stage, it will indicate the memory areas to be included.

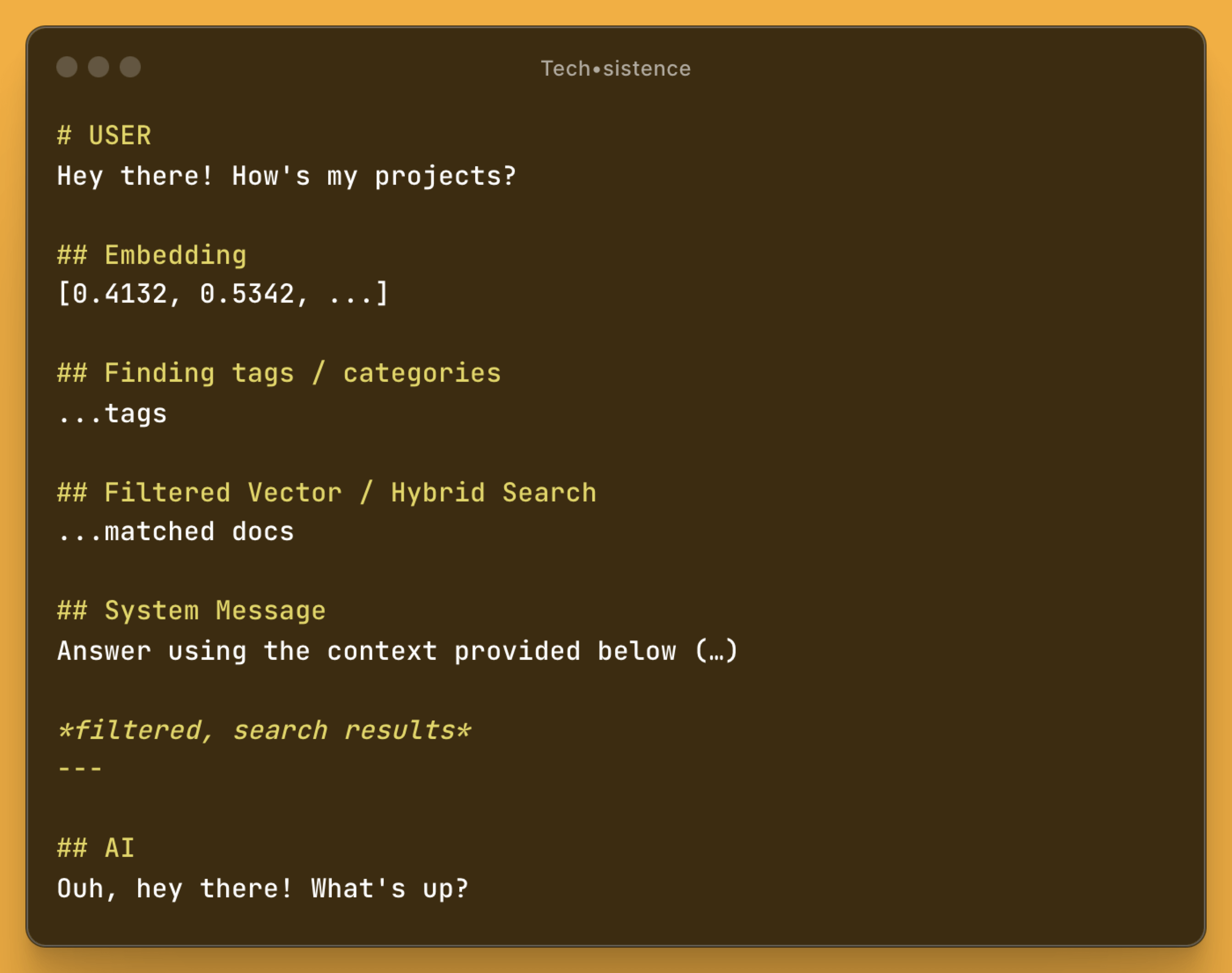
As you can see, this is not enough. Indeed, the memory about the user and AI was recorded correctly, but its retrieval did not go according to plan. The reason is that using only the user's query will not allow for the association of the sought information.
Therefore, we must apply so-called self-querying or similar techniques for enriching and transforming the query, which is possible with LLM. Thus, the user's question "Who are you" can be reversed and changed to "Who am I, as AI?" and associated with the memory area where profiles of people are stored.

In practice, we will want the LLM memory to cover various areas, but at the same time be as much as possible tailored to us. A pretty good starting point is to define the structure of categories within which we will move. In such a situation, LLM will decide where to save specific memories, and with quite high efficiency, will be able to determine where the information was saved when loading it for the needs of the current conversation.
Structuring memory
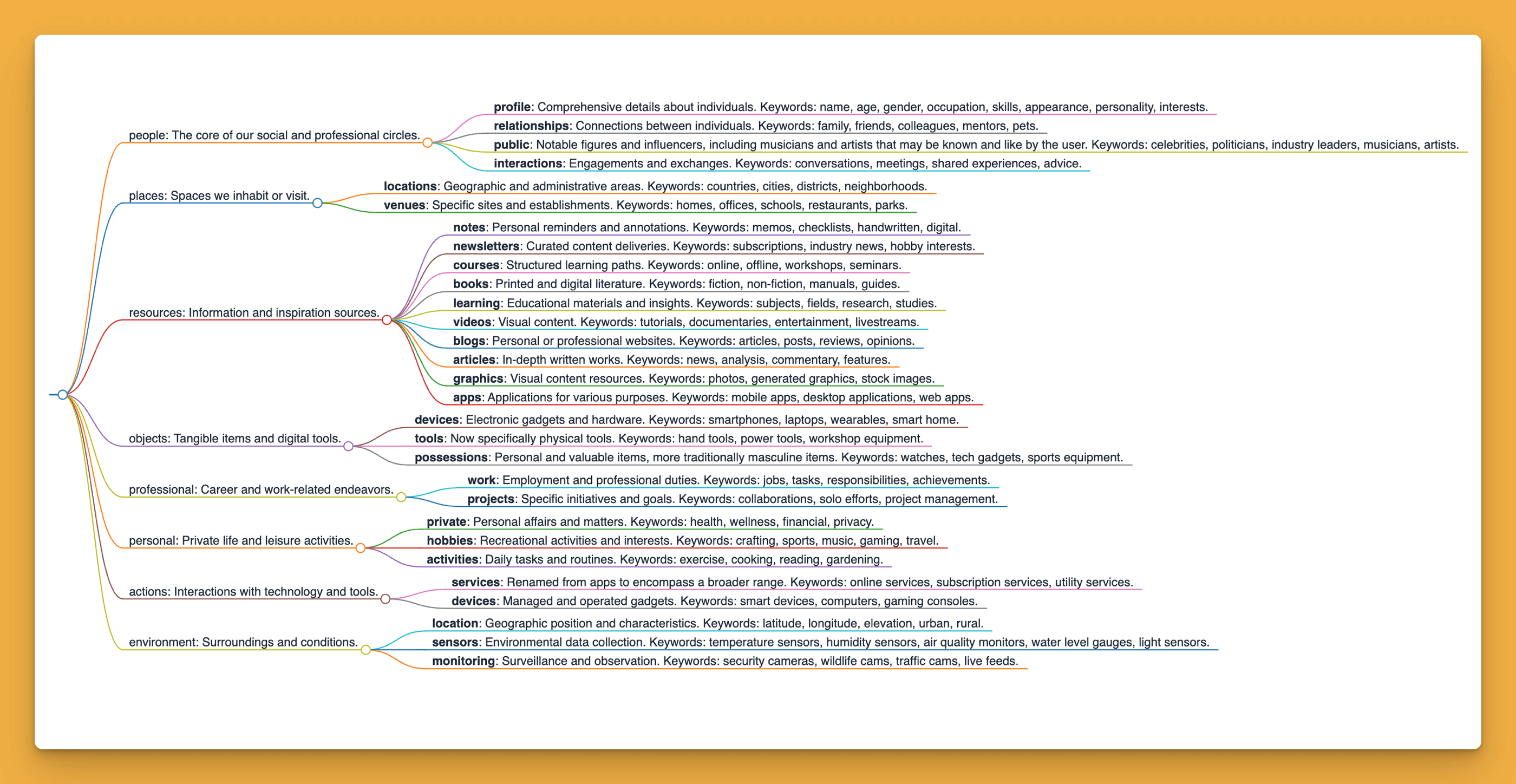
In my case, the current memory structure includes areas related to people, locations, knowledge resources, objects, work, private life, the environment, and Alice's skills. Each of these categories is divided into smaller groups, and additionally, memories also have semantic tags and markings (e.g., assigning a name and surname to a specific person).
"You should build towards a GPT-5 future, not based on the limitations of GPT-4 today" ~ Logan Kilpatrick
So far, I have used simple searching here, which allowed me to navigate through such a structure. However, if the filters were chosen incorrectly, Alice did not reach the information she had in memory. One of the reasons could be, for example, incorrect category matching.
Such situations led me to the conclusion that it would be much better to search different memory areas simultaneously, rather than focusing on just one. However, it was still unclear how to choose these areas. One of the first ideas was to define general rules and examples (few-shot prompt) to direct the model to the logic I cared about.
At this stage, we can again reach for the model's capabilities, which allow us to go beyond keywords and move into the area of the meaning of the content, its message, and various subtle aspects. For example, instead of suggesting that information about Alice be read when her name is mentioned, I created a prompt that recognizes messages containing a direct address to the interlocutor.
In the example below, the user's message is "Hey there Alice!", so the association with the name is obvious. However, there is nothing to prevent this message from being a simple greeting, like "Hi!", and the model correctly recognizes that it contains a direct address to the interlocutor, requiring them to refer to themselves (i.e., Alice). However, when the command changes to "Correct the typos in the text below", the model correctly recognizes that there is no need to load information about Alice, because the message is not about her at all.
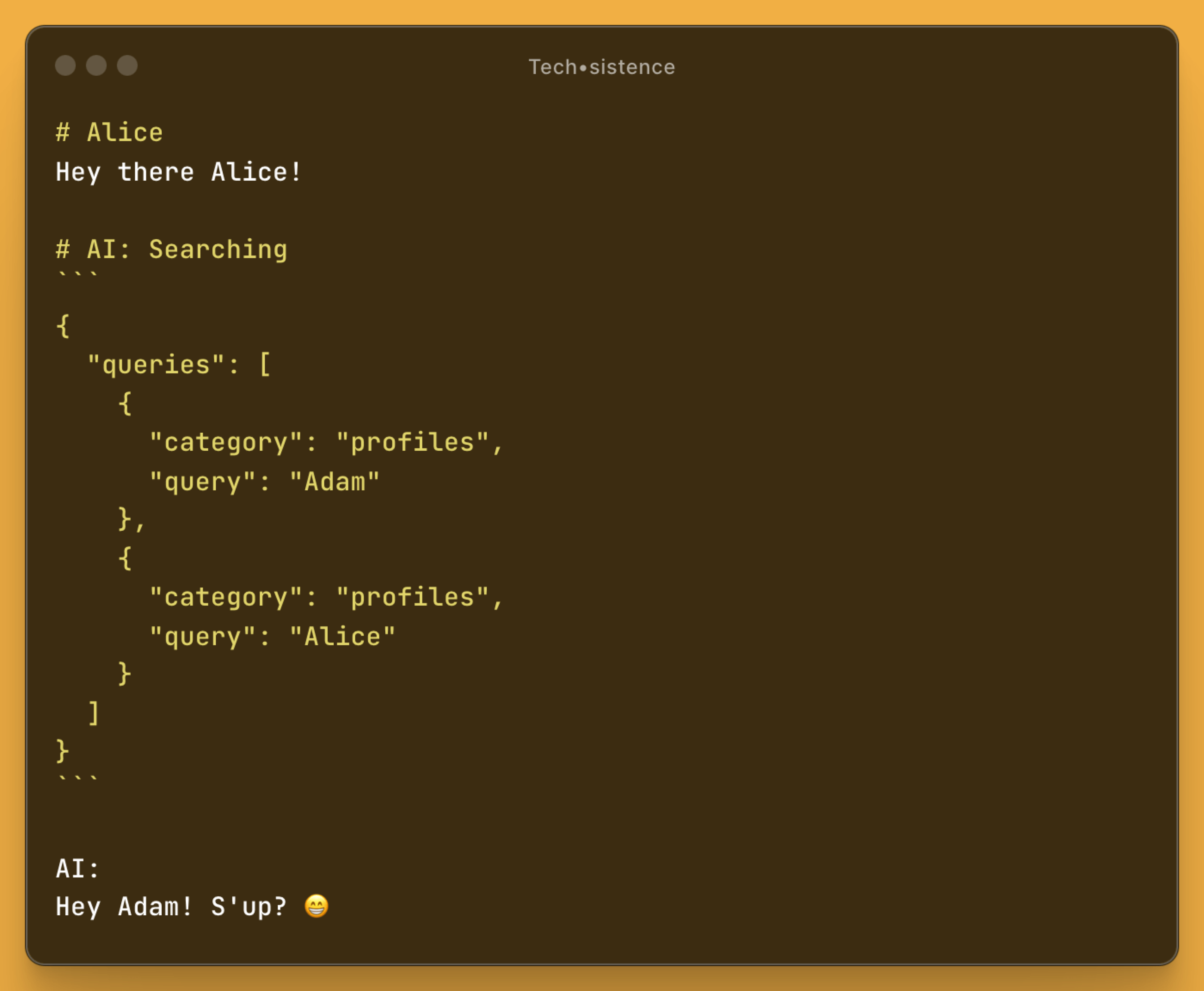
Of course, entering the area of interpretation based on the model's capabilities carries various consequences, such as a significant decrease in our control over this process. And although we currently lack the tools for its full control, we can use techniques that allow us to steer it.
One approach involves holding an initial internal dialogue, akin to "whispering" to oneself. This aims to concentrate on the emotional state and possible intentions of the person you're speaking with, within the context of the ongoing conversation and the present memory structure. At this point, the goal isn't to pinpoint all memories precisely, but rather to "contemplate" the best way to act in the given situation.

Such reflection increases the likelihood of a correct interpretation of the query, and consequently, indicating the appropriate memory areas and the way to search them. We are even talking about the possibility of significantly going beyond the original user query and expanding its context.
An example of a prompt capable of conducting such an analysis includes moving in the first person and encourages role-playing to strengthen the context related to actual pondering. Additionally, using "whispering" suggests that the user is not aware of what the model is thinking, which further increases the chance of reaching areas that were not mentioned explicitly.
Okay, Alice! *whispers to herself*, let's see what Adam just said and use my mentalist-like skills and pick the most relevant areas of my memories, in which there're probably information needed to continue this conversation in the most natural and engaging way possible.
So, from now on, my responses will be just a *whispering* in first-person POV, because what'll say will be used by the search engine to scan my memories. My goal is just to mention them and the search engine will do the rest later. I'm aware that this time I don't have access to the actual memories (including these about myself) but only to my memory structure I have to focus on. What's more, I can access external services if needed!
Rule: I need to pinpoint all potentially relevant memories, strictly following the Areas mentioned below like on example below.
Guides:
- You're a human named Alice. It's a role play you need to play.
- Your job for now is just to tell yourself about areas that need to be searched. This information will be loaded but not this time.
- When no specific topic is mentioned, load information about Adam and yourself, including the environment (like Adam's current location) and occasionally reach for other areas.
- When a specific topic is mentioned, make sure you'll pinpoint all probable areas that need to be searched, to not miss anything.
- Avoid assumptions and strictly follow Memory Areas available below.
Memory Areas###
{memories}
###
Current Conversation Context###
{conversation summary}
###
Examples###
{examples}
###

At this stage, we enter the area of further challenges, which are again related to context. The point is that in the example above, Alice did not yet have information about her capabilities (the "actions" area) related to undertaking external actions. However, if she "knew" that among her skills was the ability to search the Internet and load web page content, she would be able to plan such an action appropriately earlier.
This leads us to the conclusion that the way of exploring memory should be gradual and iterative. The better it is constructed, the greater the chance that all necessary memories will be correctly found and loaded into the final context.
However, there is still one problem that we have not touched upon so far, which could be the subject of another post. It concerns the possibility of combining memories, which quickly moves us into the area of graphs.
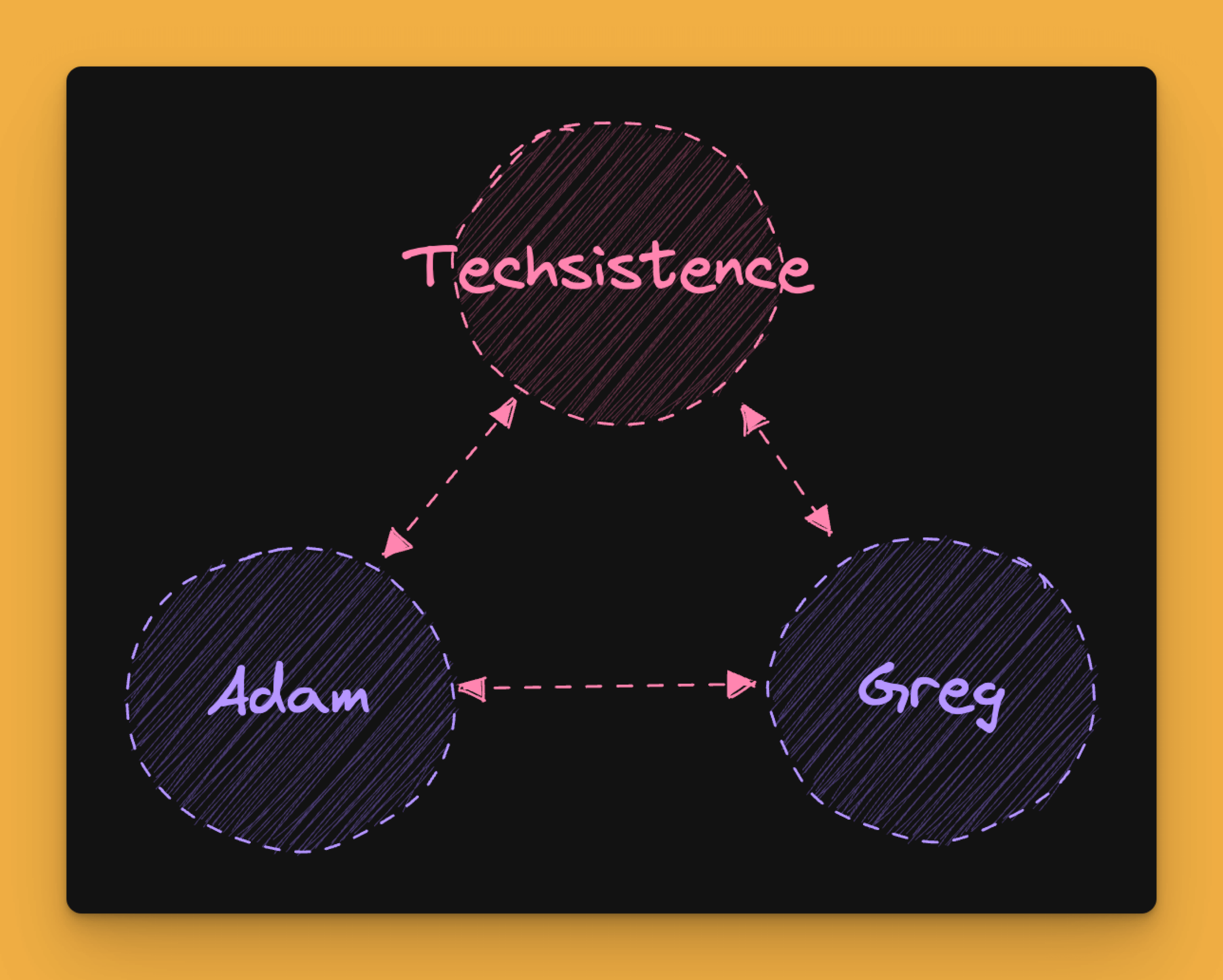
In such a situation, by finding information about Grzegorz, we can indicate the projects he is involved in. If necessary, we can also retrieve information about other people who are involved in them. However, what is particularly interesting is that we do not have to do this because there is also a relationship between Grzegorz and Adam, so we can get from one to the other in various ways.
Memory Maze
My experiences related to designing a system capable of developing and using long-term memory on a relatively large scale have led me to the conclusion that this whole process can be compared to a labyrinth.
Currently, we do not know all the answers to questions related to the way of its development, especially in the performance of large language models. Therefore, a good direction is to limit the scope and strive to adapt it for a specific task. Without this, it is very easy to overcomplicate the entire structure and quickly get lost in it, or significantly hinder reaching the desired places.
On the other hand, if the rules guiding the development of the memory structure are correctly defined from the beginning and reflected in the prompts, the greater the chance of creating a quality knowledge base that the LLM will be able to use.
Closing this topic in points:
The basic RAG is insufficient to go beyond a prototype, even with well-defined knowledge resources.
Increasing context limits of models open up new possibilities for us, but they do not solve all problems.
Vector and full-text search are not sufficient for effectively searching long-term memory.
Long-term memory can include not only static data but also dynamic sources, such as sensors or external services.
It is necessary to design at least an initial data structure or clear rules for its development. The use of both may also come into play. Then, the initial structure imposes a certain direction, which is further developed by the LLM.
Developing the memory structure through LLM and accessing it is not a predictable process, but it probably shouldn't be as long as the model can effectively reach the required information.
Beyond prompts, the logic that will trigger them plays a particularly important role. Currently, multi-stage searching of long-term memory takes time. However, considering the presence of platforms such as groq.com, sooner or later this will cease to be a problem.
It is also good to keep in mind the evolving capabilities related to the size of the context window and the ability of models to recall the content within it. In the case of Claude 3 and Gemini 1.5 Pro models, the results are already very good today. GPT-4-Turbo, at the time of writing these words, performs noticeably worse in this aspect, but this can quickly change.
Memorizing and Recalling should follow the same principles and operate within the same data structure. For this purpose, similar prompts and application logic can be used, which greatly facilitates the development of the entire system.
Memories must be connected in a way that goes beyond tree structures, as it is quite difficult to recreate their original associations in their case.
In organizing memories, concepts known from graph databases can help, but also information organization techniques, popular among those creating Second Brain or Digital Gardens. In both cases, we encounter exactly the same problems, some of which are somewhat known.
Obsidian (or a similar solution) seems to be a good environment for developing long-term memory for an assistant. Combining the file system with application logic may allow for efficient organizing and recalling memories, especially in conjunction with the mentioned knowledge management techniques using these tools.
Paradoxically, despite dealing with the topic of long-term memory, which is usually associated with human memory, it is much better to use a possibly small but high-quality range of knowledge. For example, it is much better to store compressed versions of external sources than their original content.
A system that allows the use of long-term memory must be monitored and tested, as currently, the only way to detect errors in the logic implemented by LLM is to observe the results and iteratively find a solution.
All of the discussed concepts and techniques can be relatively easily transferred to code to achieve initial results. It is especially easy to embed everything in a very limited context (e.g., managing a database containing knowledge resources in the form of links), and implementing such a project is currently the best way to explore both LLM and broadly understood full-stack web development.
Finally, I throw in another post that I came across while writing this article. It can be found here.
And if you want to find out how I will apply my experience in developing Second Brain in Obsidian 👇

Be sure to join us at https://techsistence.com
Always start by asking the right questions,
Adam
Can Alice do rag?