

Retrieval-Augmented Generation and The Issue of Trust
What if I'm a genius, but I'll lie to you 2 out of 10 times. Would you give me all your responsibilities, or would you cut ties with me? Or maybe I can still be useful to you, huh?

When you read this post, you'll probably be able to answer a few questions related to it. If necessary, their content may go beyond what you find here and also be based on your previous experience. It's also possible that you might miss some facts, mention some of them in your own words, or even end up saying something completely the opposite. However, we can assume that the overall precision of the statements will be high.

Working with larger data sets, we usually have a search engine at our disposal, which is capable of finding specific keywords, often even considering their variants. The effectiveness of such a system is usually quite high, and allows us to precisely find products in online stores or entries on blogs. Assuming that my query and the search engine settings are in order, I will gain access to precise results leading to the sought-after content.
I'm not entirely sure that this way I'll reach the best information for me, and we're talking more about a certain probability here. But, compared to the earlier example, the results I'll get here will be very precise. Like with Amazon, I receive very accurate names, pictures, and prices of products. There's not much room for error or inaccuracies.
We also have a third option in the form of large language models (LLMs). Although their base knowledge is limited, we can connect them with our own knowledge sources using Retrieval-Augmented Generation. Then, LLMs can use the information provided by us when generating responses.
So I can create a prompt to which I'll attach the content of my post. Then GPT-4 will correctly answer my question, using knowledge it doesn't usually have. This way, I gain flexibility comparable to talking with a human and precision similar to what search engines offer.

Unfortunately, this approach also has a hidden cost in the form of the risk of generating an answer that is not true. Moreover, there may be little to indicate this, and we can be easily misled. Sometimes even a different way of asking a question is enough to receive an incomplete or outright incorrect answer for the same set of data. We see this in the following response, which does not mention one's own experiences and memory, which I wrote about at the beginning of this post.

So here we are dealing with three scenarios that offer us different benefits but also have their drawbacks. Specifically, talking to a human offers us high flexibility and precision, but also the potential risk of error. Search engines are much more precise, and the risk of error is quite low, but they also offer less flexibility. Meanwhile, LLMs offer both flexibility and precision, as well as a high risk of making a mistake.
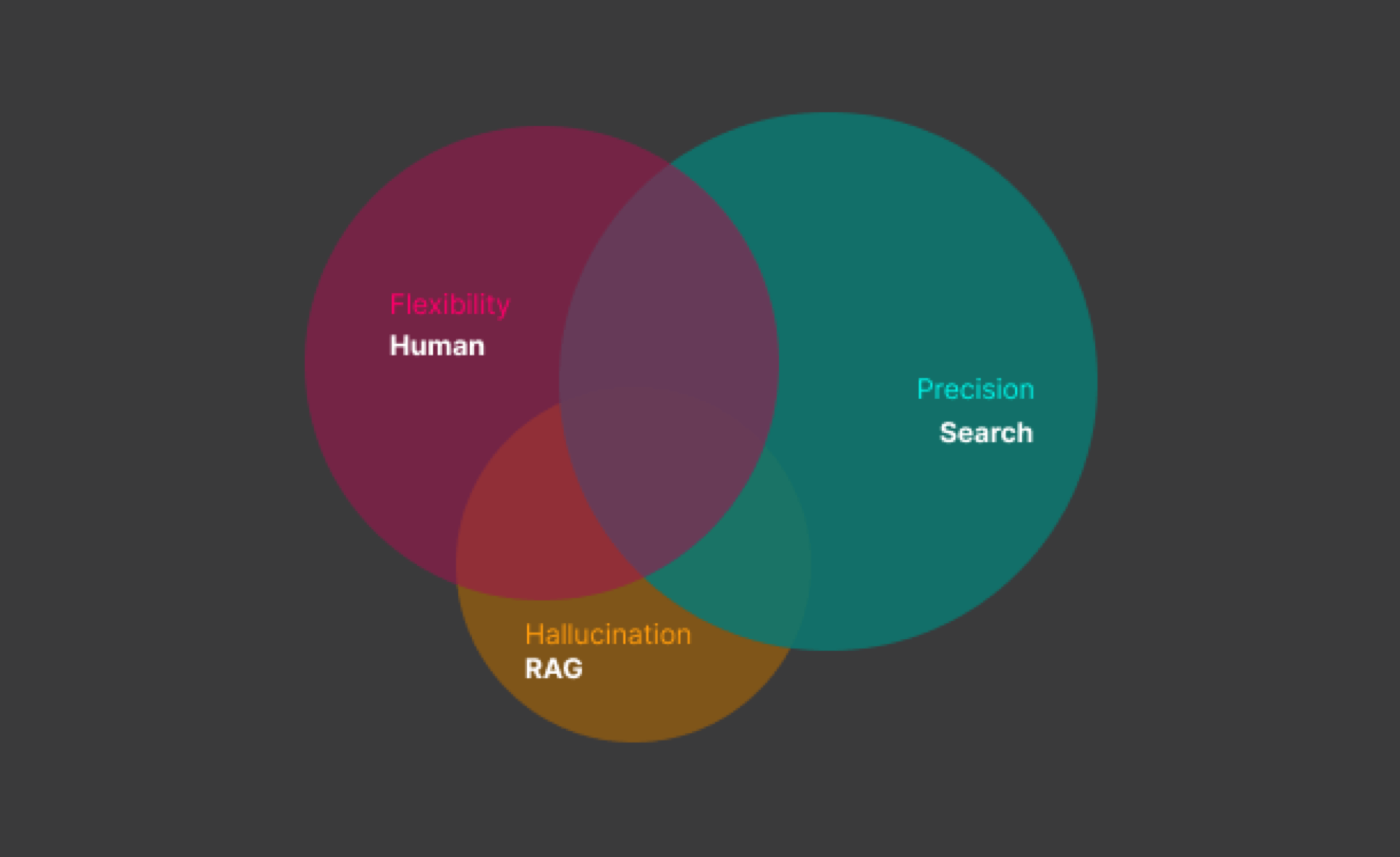
There is no doubt, however, that the idea of combining LLMs with our own knowledge base can be of great value. Then with such a model, we can talk and connect it with tools and services, thus engaging it in our daily activities and even business processes. However, it is difficult to talk about entrusting any tasks to someone who is difficult to trust. We must therefore fully understand the problem and its causes to address it, or simply decide whether it is worth engaging LLMs in specific tasks.
Retrieval Augmented Generation
Combining LLMs with our own knowledge base is based on the ability to add a limited amount of information to the prompt, constituting the "query context". Along with it, we also attach instructions explaining how to provide answers and use the provided content.

The content of the context is not static, however, but is dynamically built based on the user's query, the content of the current conversation, or external data. In any case, it is the logic of the application that supplements it in such a way as to contain the most useful information possible, based on which the model will provide an answer. And it is precisely in this area that we currently find both the most possibilities and limitations.
It is not difficult to imagine that designing a system capable of using available knowledge in such a way that only the necessary information reaches the context at a given moment is a significant challenge.
Let's start with a simple scenario where the model is connected to the Linear application, which allows us to "talk" to the task list. Asking a simple question about listing "today's tasks" requires connecting to the data source (it can also be Todoist or another task application) and retrieving the necessary information. This means that the system must take several additional actions before it even begins to generate a response. At this stage, various kinds of mistakes can occur, for example, related to selecting only today's tasks.
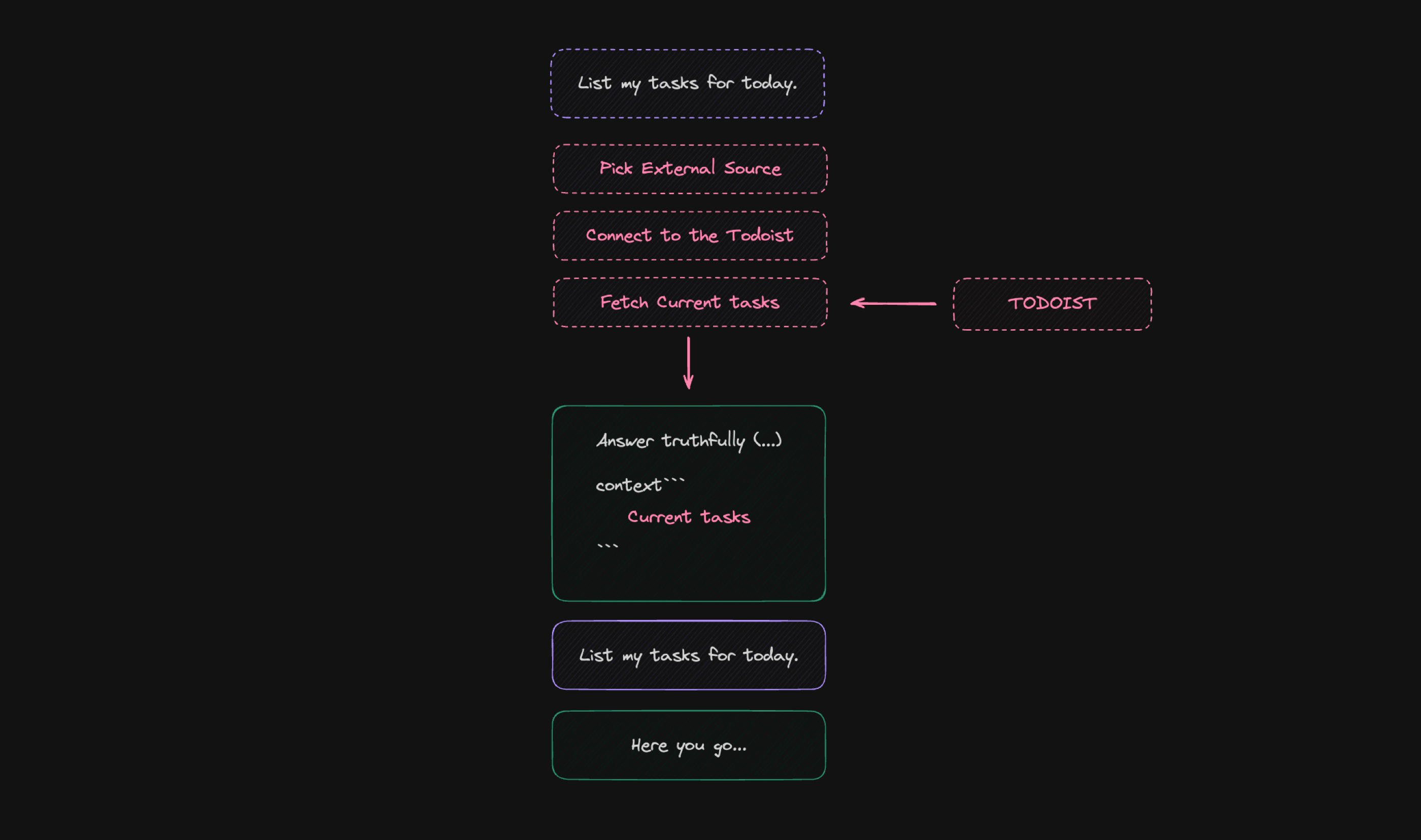
However, assuming that our current tasks actually make it to the context, GPT-4 should have no problem transcribing them. In the same way, we can design interactions with other data sources, including monitoring the content of websites.
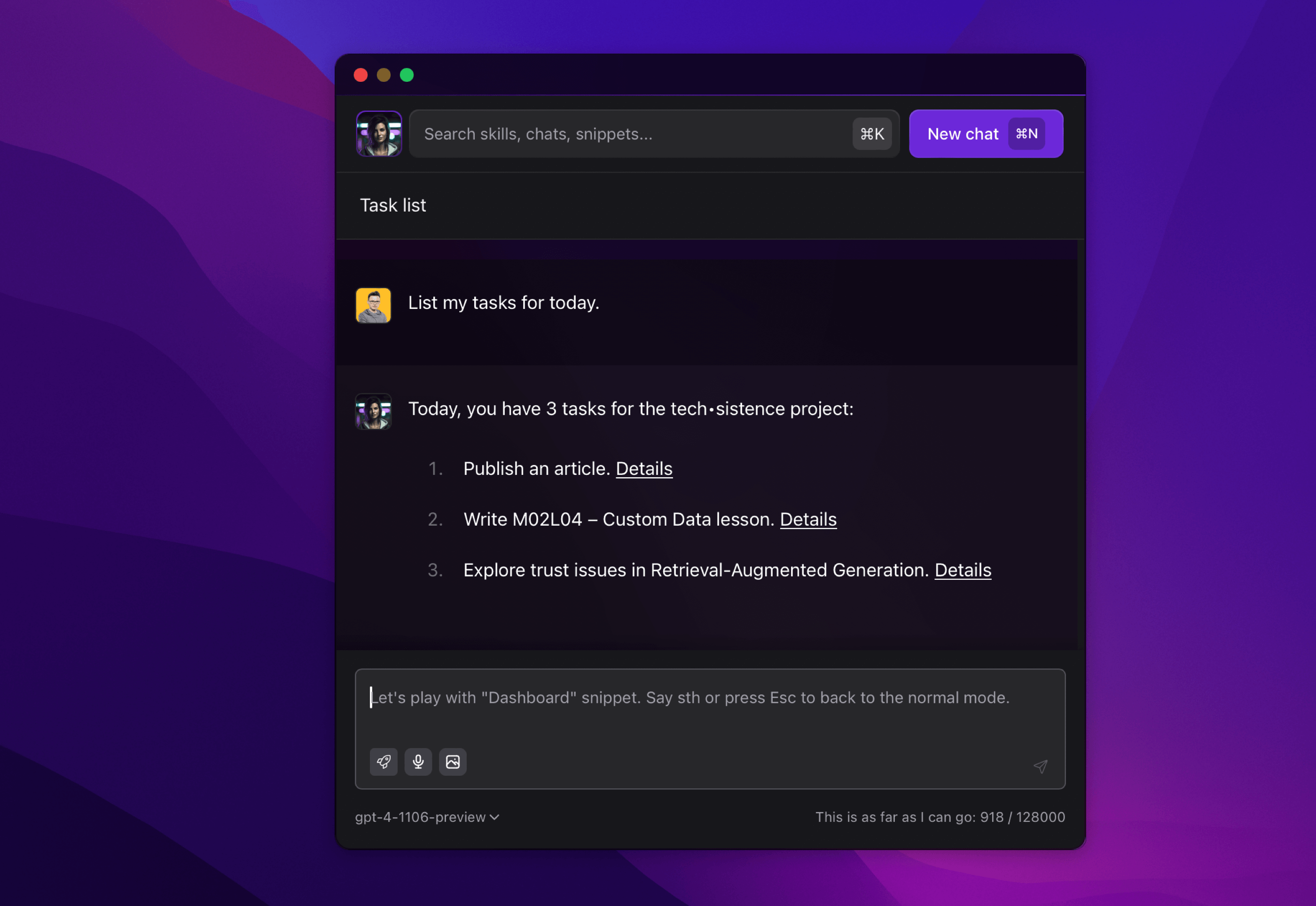
The situation starts to get complicated when we care not only about retrieving data but also about managing it. This increases the complexity of the entire system, thereby increasing the scope of the model's work and requiring us to maintain high precision when designing prompts and the logic of the application itself.
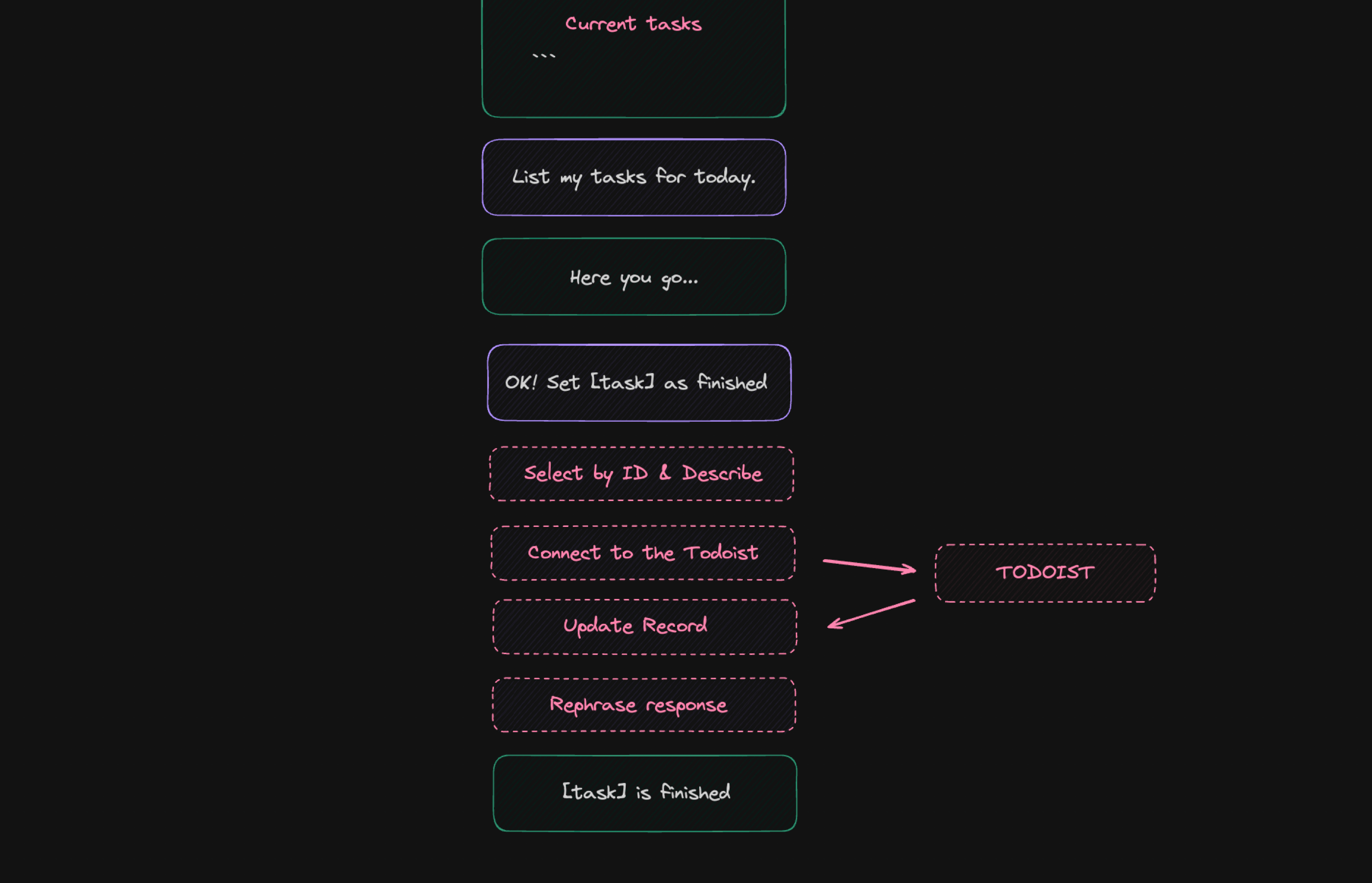
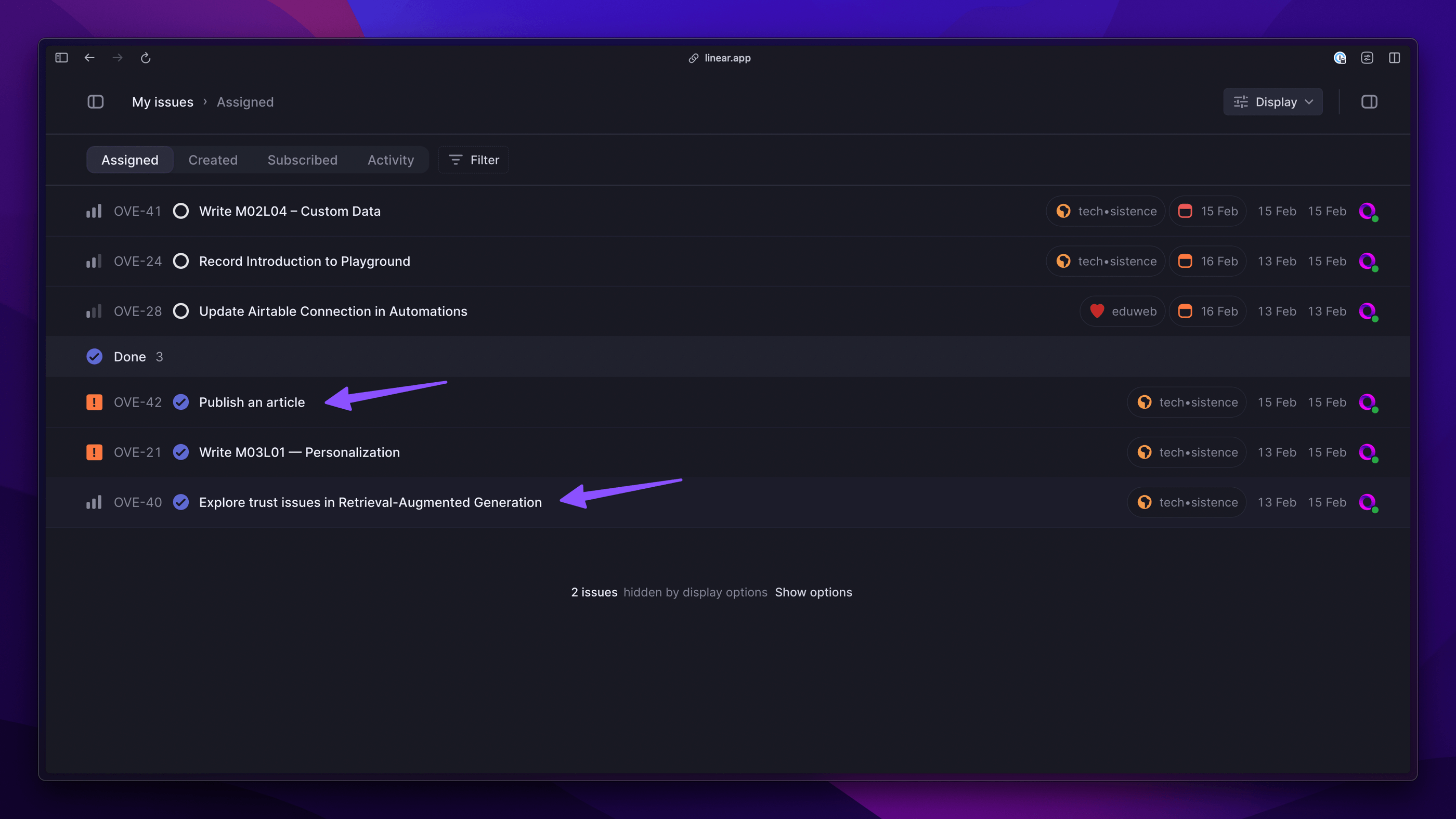
Despite the increase in complexity, the whole thing is not a problem for GPT-4-Turbo. My request to mark the indicated tasks as completed has been realized.
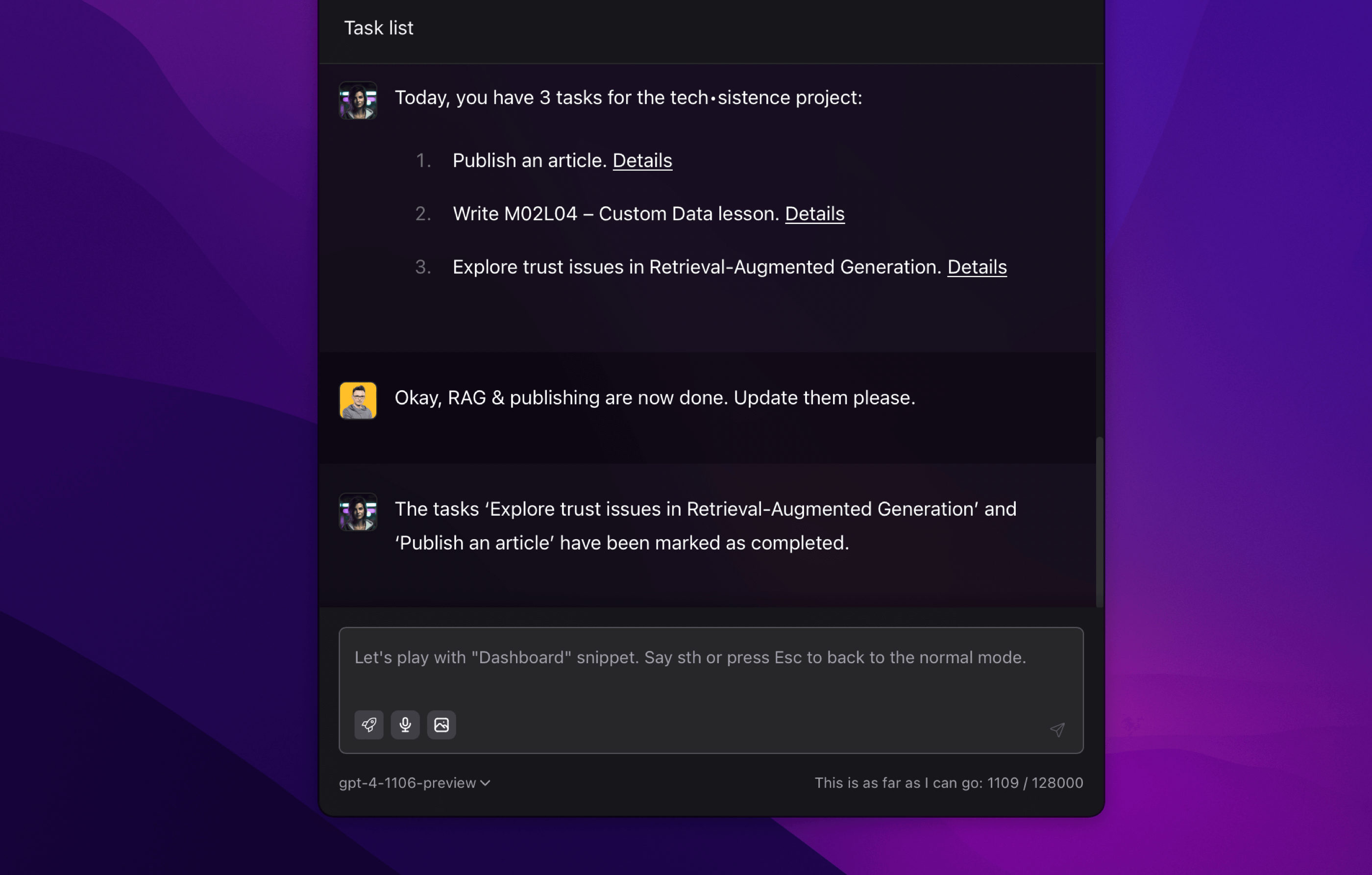
Proof of the completed action is below. So, we see that the possibilities of LLMs in combination with our data are very impressive. I experience this even more clearly when, instead of manually filling in the calendar or task list, I simply tell my watch what I have to do. Such a message is recorded, converted to text, and passed to the right place.
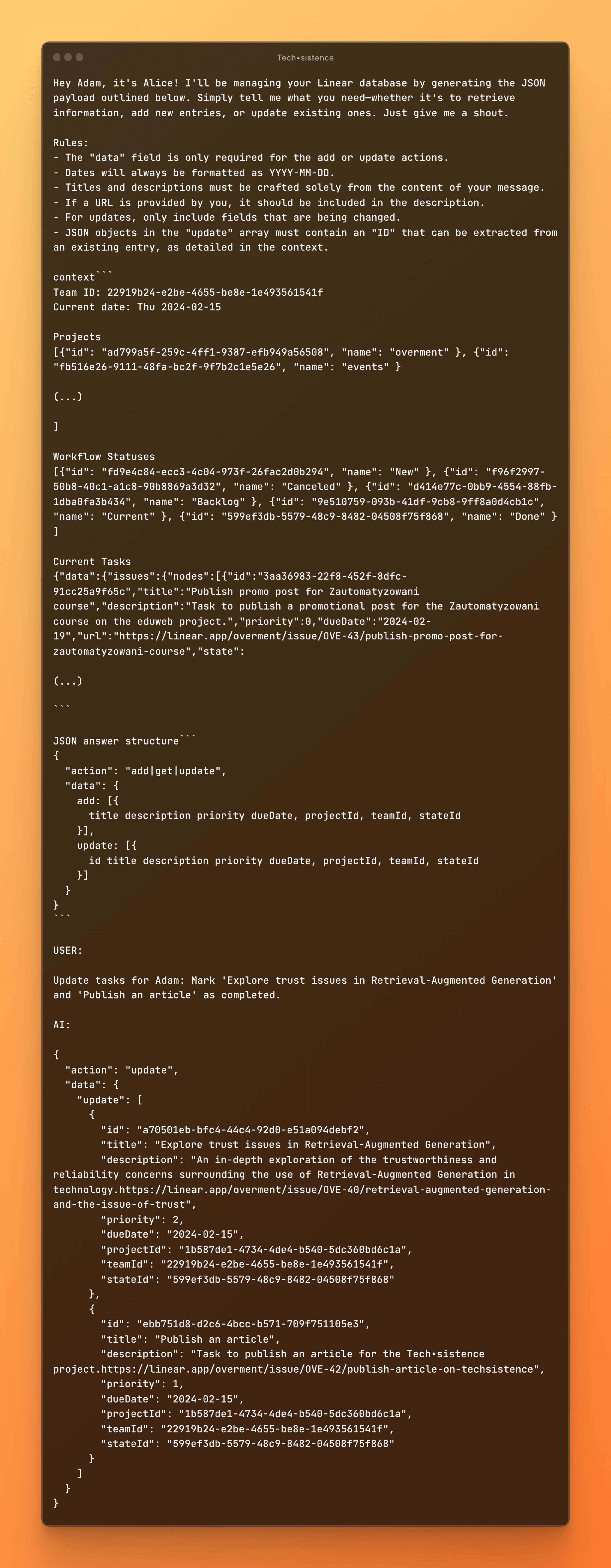
To illustrate the complexity of ONE element of the solution we are referring to here, I include a fragment of the prompt as well as the generated responses. And I will just remind you that usually, at least several such actions are performed.
Integrating an LLM with a private task list remains a basic example of RAG, as we operate within a very closed area of information and possible commands. Despite this, there are a number of problems that we must address. The first one that comes to mind could be a user's request to update a task, to which the model responds by updating the wrong entry.

In this situation, one could argue that the model behaved correctly, but the expected result was not achieved. Such mistakes happen more often and are not always so obvious. Sometimes the model may misinterpret the user's query, and instead of adding a new entry, it could potentially update an existing one. Naturally, this is not an insurmountable barrier, but we certainly need to keep it in mind. Implementing additional mechanisms to verify the actions taken by the model becomes necessary here.
A different perception of reality, and a genius locked in a room.
LLMs have limitations on the amount of content they can process within a single query. This limit is constantly increasing and currently reaches 128,000–200,000 tokens, and according to Google's announcements, Gemini 1.5 raises the bar to 1 million tokens. This last value is about 700,000 words in English, so quite a lot.
Of course, we must also add the fact that the pricing for using LLMs usually depends on the number of processed tokens. These prices are significantly dropping, so over time this should become less significant.
However, even the example at the beginning of this post shows that the content limit is not our only concern, as ultimately, we will care about the effectiveness of the responses, which can drop even in the context containing only one article.
Here we also have various solutions available. One of them could be optimizing the prompt to control the model's behavior so that it uses the provided context more carefully. Not always will it be possible, and not without reason, people commonly say that even the best prompt won't handle a poor context.

Currently, it seems reasonable to ask how to create a good context. And although I cannot answer unequivocally, we can quite freely point out areas that need to be considered. Before we move on to them, you should know that usually dynamic context is built from fragments of content coming from various places. These fragments are searched with the help of various search engines, including vector databases.
Ambiguity: a situation where two similar but unrelated pieces of information enter the context. For example, summaries of two books with the same title. If we do not clearly separate them from each other, we can be almost certain of an incorrect answer.
Complexity: answers to some questions require reaching many different places or processing a large amount of content. For example, a question about financial results may require going through many different documents, which cannot all be included in the context at once. However, if the reports had previously generated summaries focusing on individual areas, they could be used to provide an answer.
Contradiction: two pieces of information that directly contradict or overwrite each other may appear in the context. This can happen in the case of documents that change over time, or when loading two unrelated documents discussing the same topic but in an entirely different context.
Isolation: practically any information provided to the model without additional context about its origin or different features can constitute noise that reduces the quality of the response. This is particularly important when we load data from various sources into the context.
Organization: the above example concerning the origin of information is directly related to the way data is organized, which should be considered at the stage of searching or filtering. For example, when I ask about articles I have read on a selected topic, I would like the model to be able to indicate them, ignoring those that may be in my database, but I have not had the chance to familiarize myself with.
Inaccessibility: if the context contains links, images, videos, or any attachments, the model will not have direct access to them. Then it is necessary to include descriptions of their content.
Absence: this is a situation where the data we ask about is not delivered to the context. Such a situation can occur when searching for content we only consider the current user query, or on the contrary — we get distracted by too many documents, omitting some of those that are relevant.
Reachability: if I now say "in my previous post," you can find it by going to Tech•sistence. LLMs do not have this capability. Therefore, examples of all references or situations when we share something but do not use keywords become incomprehensible to the model. I encountered this most in the case of video transcriptions, where terms like "I click here" were used. Therefore, when creating content for LLMs, we should either avoid such situations or take additional steps to help the model understand the message.
It is essential to bear in mind that currently, LLMs can only experience reality through text. Of course, we have Vision models at our disposal, which allow us to use images as well, but this does not solve the problem. The fundamental problem we face here is the complex "connecting the dots," knowledge of a broad context, or having information coming directly from our environment. We currently have to present all this to the model in some way so that it can effectively use the available information. The whole is also complemented by the content format, about which I wrote more in Plain Text is What You Need which I warmly invite you to read.
Limited Trust
Combining a large language model with our knowledge base comes with a series of limitations and challenges that are difficult to address in practice. To put it simply, the effectiveness of RAG is about 70-90%. This means that placing blind trust in them is not a good idea.
However, if we look at the examples of applications I use every day, it's challenging to question their usefulness. And it's worth considering that the actions AI currently performs for me can also be triggered without my involvement, through automation scenarios and scripts that work for me around the clock.
The purpose of this post was to draw attention to serious problems that are often completely overlooked and can lead to real consequences resulting from the improper use of AI, especially LLMs. At the same time, I wanted to present the possibilities that were recently out of our reach, but today make work easier and turn elements of everyday functioning into great fun, bringing with them real value.
Have fun,
Adam