

Exploring Artificial Senses in Real Life
How do the rules of the game change in the face of AI capable of interacting with the environment through senses combined with the ability to reason and speak?

OpenAI provides models specialized in writing, speaking, seeing, listening, and graphic creation. This set is clearly created in the image of human senses, but in this case, their use is enriched with the knowledge possessed by the model, which includes a significant part of the Internet.
So, essentially, using their skills separately can often accomplish tasks faster than we could in the same timeframe. An entirely new chapter opens when all available senses begin to connect with each other. However, the real game begins when they gain access to knowledge about us and our environment.

Understanding and writing
The basic skill of large language models, such as GPT-4, is generating content by predicting its next fragment, or token. Defining the rules for a system capable of performing such a task is too complicated. That's why we created a solution able to independently set, detect, and use them, through a training process that takes place on huge datasets. Although the training process itself is well known to us, the details of the operation of the model created in this way remain beyond the reach of our current understanding, and to explain its behavior we mainly use experiences, intuition, and various assumptions.

Prediction is compression. ~ Ilya Sutskever*, \"An Observation on Generalization\"
One of these assumptions concerns the ability to understand, which until now has been beyond the reach of computers. This changes with large language models (LLMs), which during training recognize patterns, rules, and determine the meaning and relationships present in the training data content. The information gathered in this way is stored in a highly compressed form as model parameters, which are used when selecting the next token. So here we see that prediction is compression, and compression requires possession and understanding of existing rules. Of course, how closely the model's understanding resembles what we have as humans is an open topic and at this stage more philosophical.
However, for working with LLMs, it is enough for us to know that we are dealing with a solution capable not only of generating but above all of \"understanding\" content.
Of course, this does not exclude the presence of mistakes and misinterpretation, which bring to mind the phenomenon referred to as \"model hallucination.\" A different light is shed on this by a tweet from Andrej Karpathy noting that LLMs are dream machines, and hallucination is in a sense the only thing they can do. Our task is to direct this dream in such a way as to achieve results as close as possible to those we expect.

Speaking of "understanding" in the performance of LLMs, we should also pay attention to the very way of "thinking" associated with generating subsequent tokens. Here again, Andrej in one of his posts points out the "thinking time" which in the case of the model is very short and takes place during the generation of the next token. Therefore, by asking for a longer statement from the model, we give it additional time to think, which positively affects the quality of the generated response. For example, we can ask for "step-by-step thinking" or "step-by-step verification."
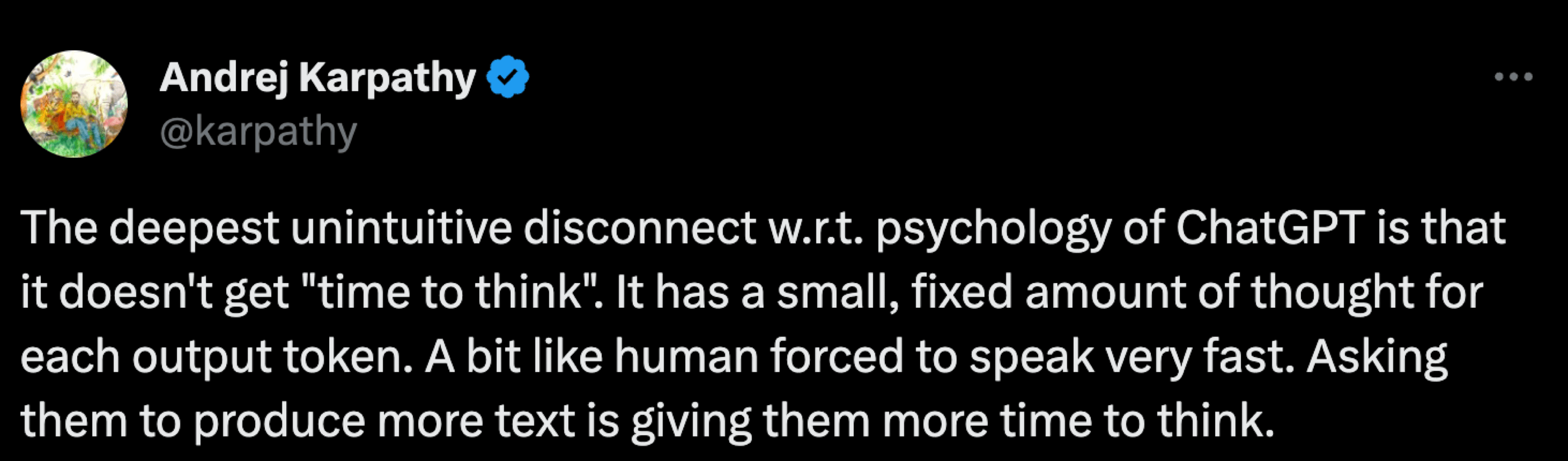
Generating longer content is not the only element that can positively influence the model's "thinking" process. The context of the ongoing conversation also comes into play, in which there may be examples or content leading the model through a specific thought pattern. Thus, for LLMs, the "thinking time" is directly related to the length and quality of the processed content.
Translating this into practical interaction with models:
The behavior of the model is influenced not only by the instruction (prompt) but also by the content of the ongoing conversation, which the model considers when generating subsequent tokens of its statement
Although the length of the processed content constitutes \"thinking time\" for the model, this does not mean that very long content will bring the expected results. The model has a limited ability to maintain attention and in the case of extensive content may omit important details, which will negatively affect the result
The content processed by the model only steers its behavior, and does not unequivocally define it. For this reason, for the same content, the model may generate different results. It is therefore possible to generate multiple responses in parallel and choose the one that seems most probable. This technique is known as Self Consistency and proves to be very effective, especially in situations where complex reasoning comes into play.
The time for "thinking" and the reasoning itself can take place both within a single conversation and a series of different queries, the results of which precede the generation of the final answer. Conducting such an extensive process will usually require the engagement of guardrails in the form of additional prompts or programmatic support, as well as the use of external tools that the model can use
The reasoning process can also be influenced by going beyond the model's base knowledge and providing external context from specified data sources or tools. However, here too, the limited ability of the model to maintain attention comes into play, as well as the fact that large language models can be easily distracted by irrelevant (or poorly delivered) context
Summarizing the thread of understanding and generating content, I always keep in mind the main task of LLMs, which is to predict the next token for a given set of text. Although all the details of this process are not known to us, in most cases, maintaining this awareness helps me shape my queries and conduct the entire interaction both directly, during the conversation with the model, and automatically, which takes place in my application’s logic.
Listening and speaking
Whisper and TTS are OpenAI models that enable speech-to-text and text-to-speech processing, with support for nearly 60 languages. The most common use of these models includes transcription and translation of audio/video materials.
Nothing prevents us from taking advantage of the fact that we are dealing with a textual format, which gives us the opportunity to use the model's ability to understand and generate content.
Working with the Whisper model, the basic configuration includes defining a prompt that is considered when generating transcriptions. The prompt affects the way individual words are written or the overall style. Suggestions for prompts can be found in the OpenAI Cookbook.
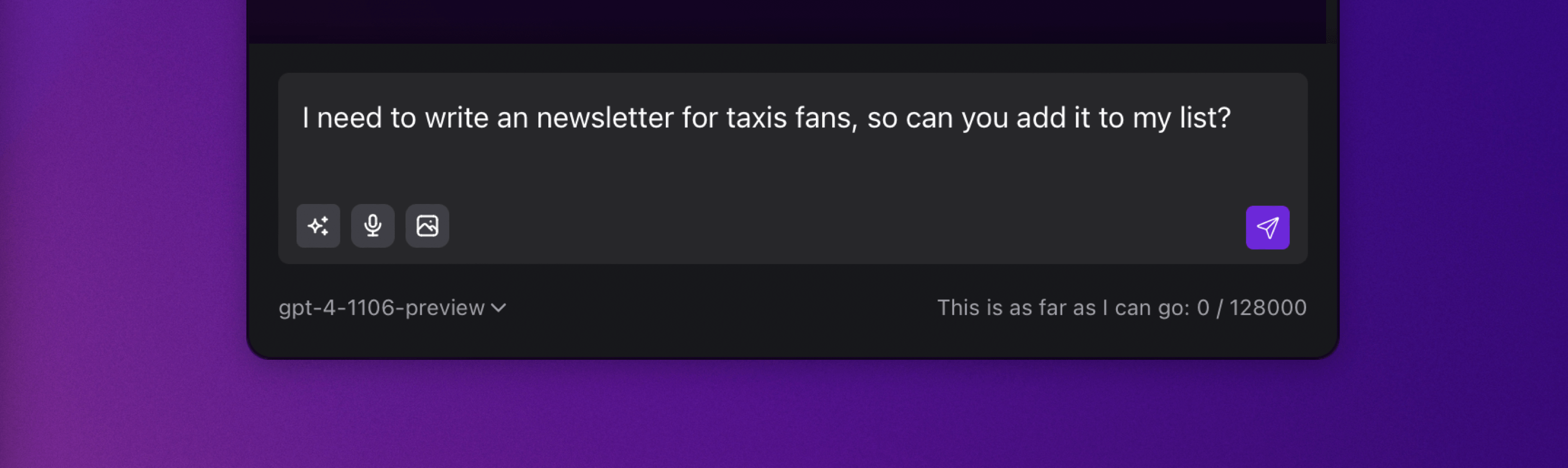
By default, Whisper is unable to correctly transcribe the name "techsistence" in my voice message.
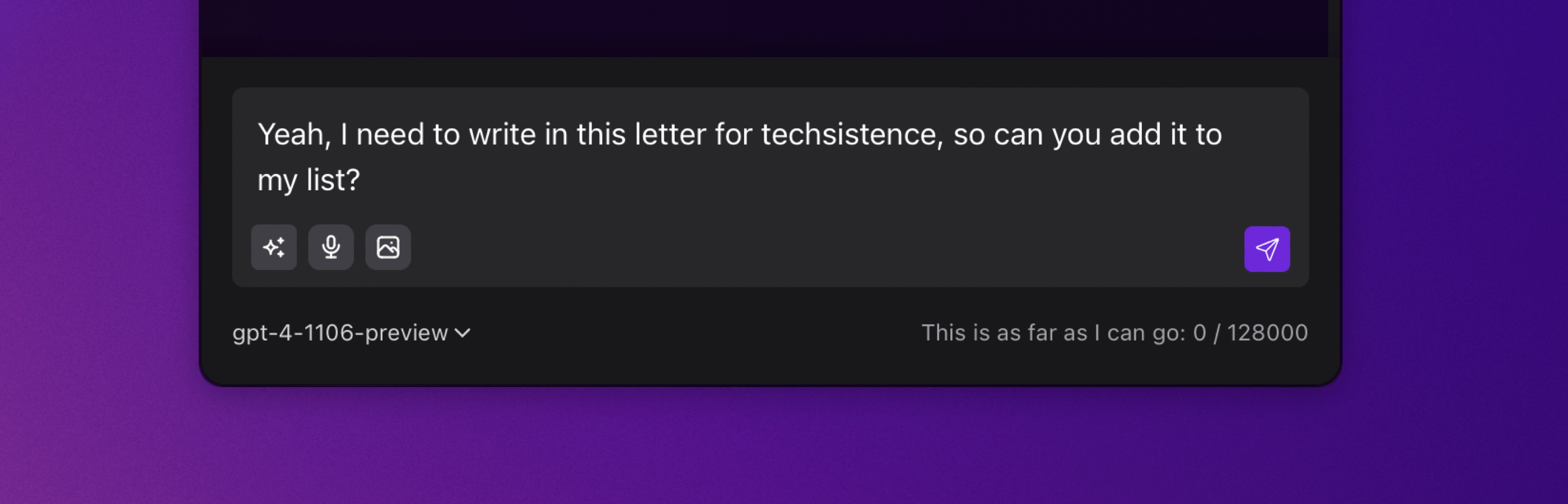
However, if potential names that may appear in the transcription are included in the prompt, the quality of the response increases and this time the name is transcribed correctly.
A slightly more advanced option is to process the generated transcription through an LLM, where, in addition to the transcription, an instruction is also included based on which the text will be processed according to our expectations. There is also nothing to prevent the instruction from being enriched with additional external context, which will also influence the final response.

A practical application of such a mechanism could be voice notes, in which the original content is formatted, classified, and even enriched, increasing its usefulness. When making such modifications, it is good to also keep the original content so that it can be referred back to if necessary. Below is an example where a recorded message containing loose thoughts about the post you are reading has been associated with information about my other publications. The note now includes a title and a short summary, making it easier to organize in Notion.
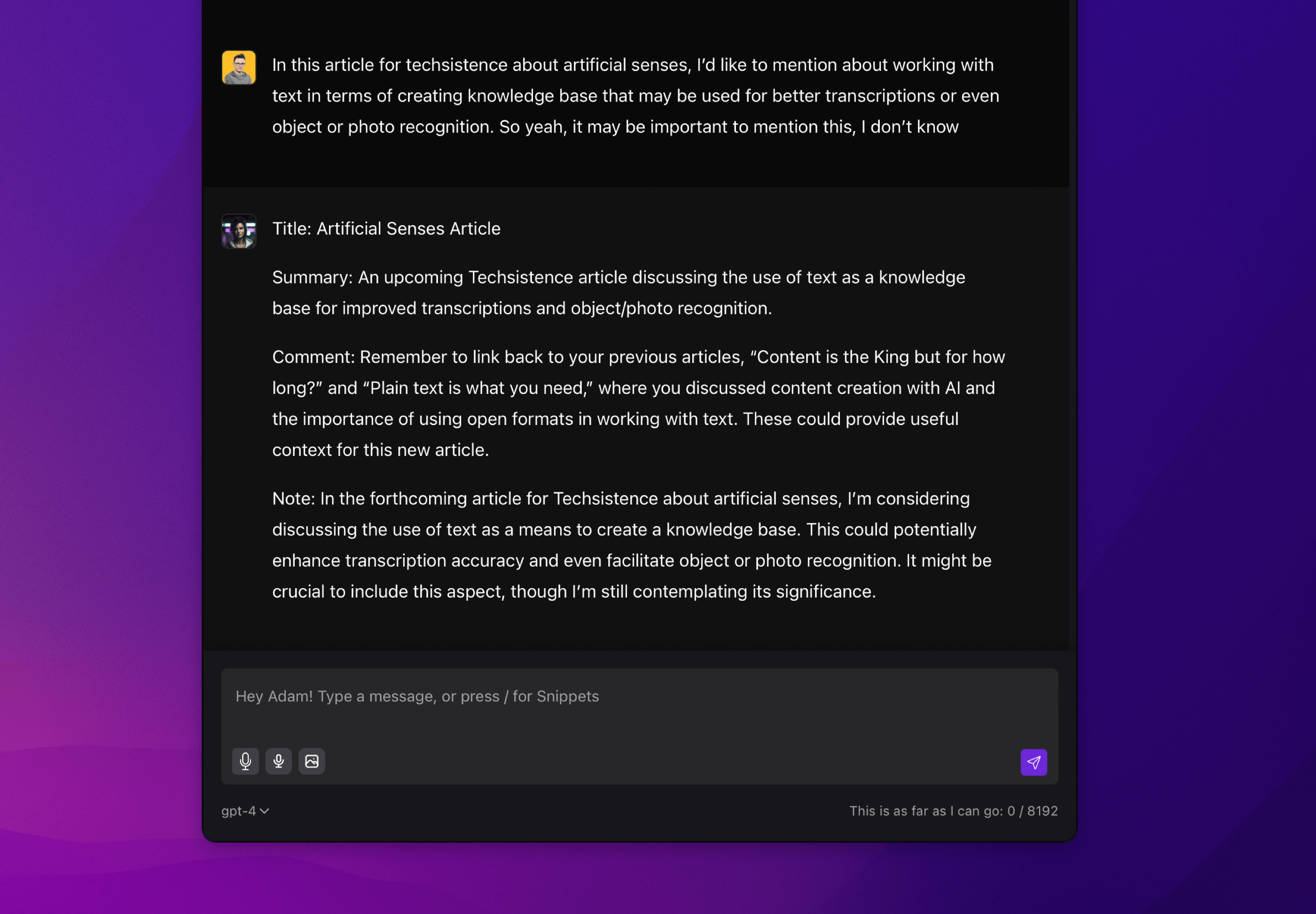
The ability to combine new content with existing content can also be used in voice interfaces, where commands can be converted to text, transformed, enriched, and associated with a list of available actions. Then, the feedback can be not only displayed on the user's screen but also played back in audio form. I wrote more on this topic in User Interfaces may change because "AI knows what we mean".
From a practical perspective:
Speech recognition works at a very high level, but occasionally Whisper generates transcriptions containing errors or directly not matching the processed audio. This should be kept in mind.
Whisper can operate locally, e.g., thanks to whisper-turbo, which reduces costs and ensures privacy.
The content of a Whisper prompt can be dynamically generated by the application's logic. Its content can significantly improve the quality of the generated transcription.
Using audio streaming allows for a low response time and is a technique worth considering when implementing voice interfaces.
The generated transcription can be processed by an LLM with external data, which can make it more valuable and help in cataloging.
A voice interface can use all available options and even connect with external tools for information exchange.
I use whisper/tts for voice interaction with Alice through my iPhone, Apple Watch, or a Slack channel where I can simply record a message.
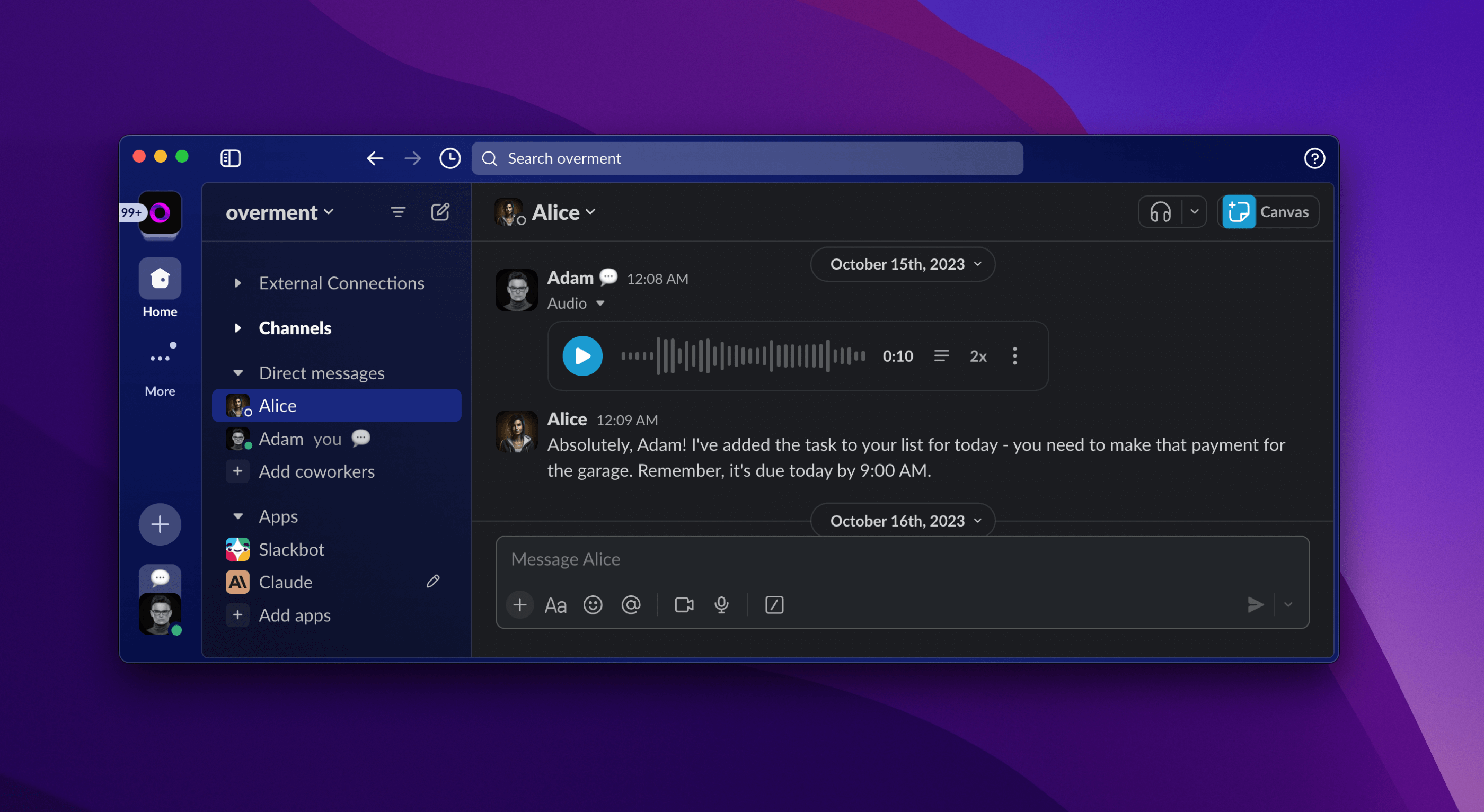
Voice messages are characterized by containing only audio recordings. Therefore, if one of them contains the content of a note that we want to save in Notion, and another is information about a shopping list, it is necessary to distinguish the desired action. Then an additional interface may come into play, with which we choose how to process the recorded message, or we may reach for the model's capabilities again to recognize the intent contained in the content. Examples of what I am writing about currently are also included in the previously mentioned post about user interfaces.
Vision and Drawing
Describing and generating images is also within the reach of models provided by OpenAI. As before, it's not directly about these skills, but their embedding in the broader context of capabilities offered by LLMs.
GPT-4 Vision allows us to send an image that can become an element of the conversation. This enriches the interaction by facilitating the provision of context in situations where creating a description may be difficult or impossible in a given situation (e.g., during automatic file processing, without human involvement). Image recognition may also be necessary in connection with the task at hand, such as design-related tasks.
Describing an image allows for the recognition of its features, which can be associated with information contained in long-term memory. Below, we have an example of how Alice recognized her avatar when the context of the query included a photo and a description of her appearance.
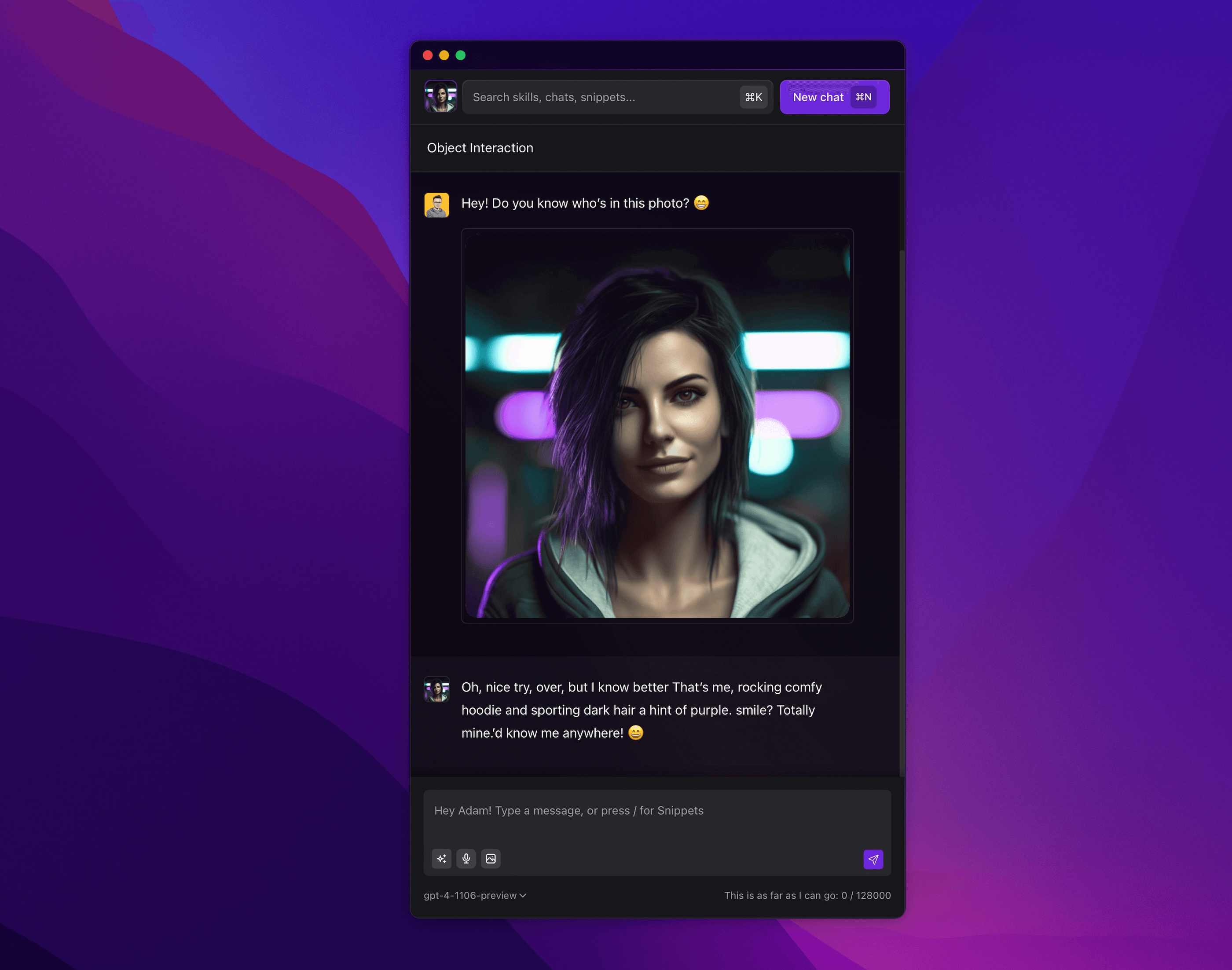
Although in this particular case the description was added by me directly, it would also be possible to use Similarity Search with a general description of the image with the image itself. An example of recognizing similar images is visible in the animation below from the tool available on the website: projector.tensorflow.org

Describing the features of an image can also be helpful in generating new creations, making modifications, or creating variants. Below you can see how Midjourney described the photo I sent in various ways. Here I can use these results directly or make modifications to them, which can also be done with the help of an LLM.
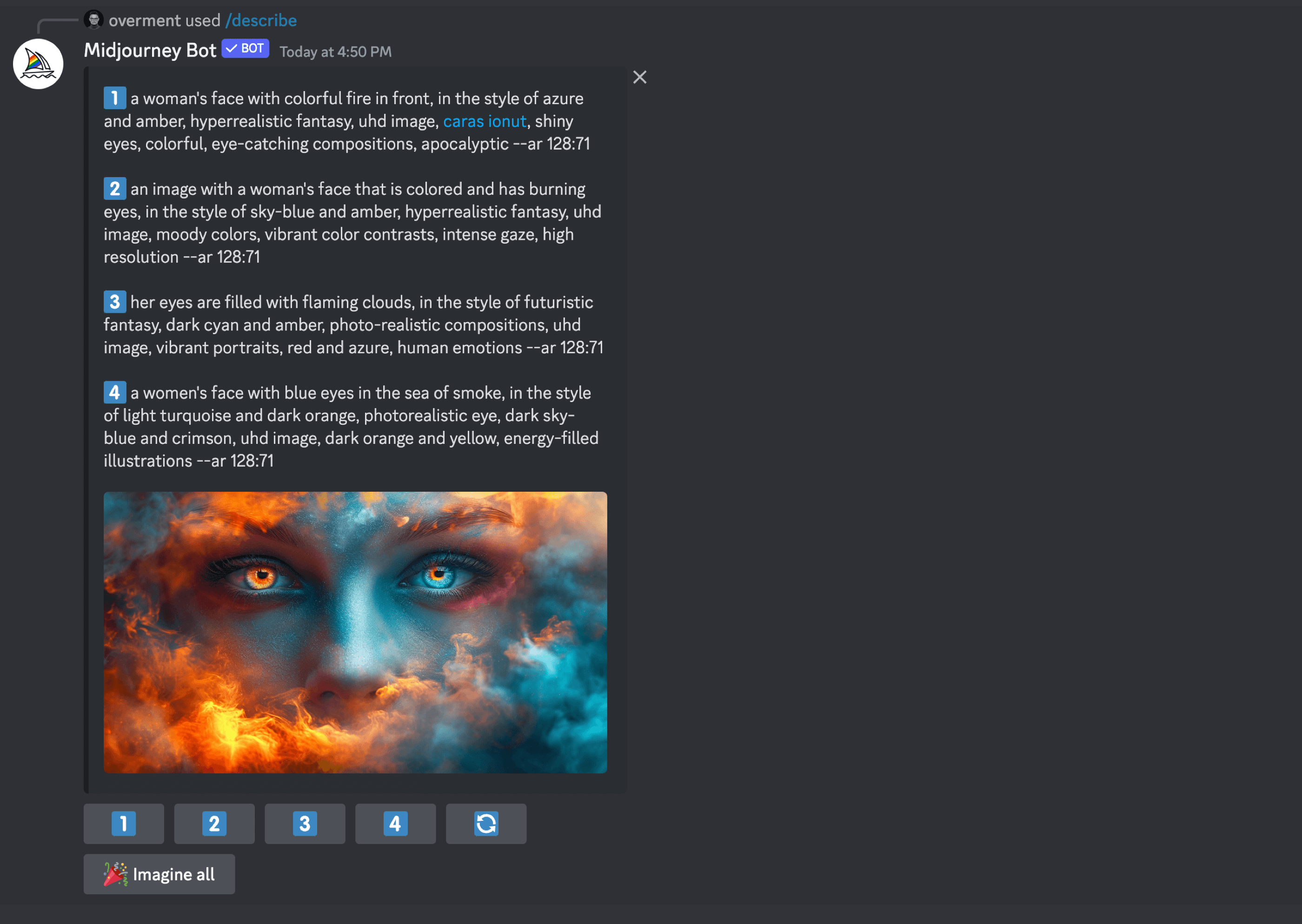
We will not dwell on the techniques of generating images with DALL·E 3 this time, but it is enough to keep in mind the possibility of using different senses and skills of the model when designing prompts based on which graphics are created.
In the case of GPT-4 Vision and DALL·E 3 models, mistakes and various inaccuracies can also occur. Therefore, when using them, at least partial human involvement in the supervision and verification process of the generated results should be considered. It is also best to avoid using them in sensitive or directly critical areas.
The ability of models to work with images, from a practical perspective:
Application in tasks involving interaction with visual elements, such as design or implementing interfaces about which we can have a conversation without the need to describe all the details ourselves
Visual search that takes into account not only the similarity of the images themselves (similarity search), but also their features derived from the description created by LLM
Associating graphically presented content with textual knowledge bases, documentation, or guides
Taking actions related to object recognition or associating visual features of an image. Examples include automatic document organization or easy photo conversion to another format, also considering advanced transformations and a series of actions (worth seeing "self operating computer")
Connecting the senses with the environment
The combination of capabilities at our disposal is not obvious, as practically each of them is something new to us, and many questions still do not have clear answers. AI itself, in the form we have had the opportunity to observe over the past year, is also at an early stage of development. The same is true for work techniques and general knowledge about models.
My experience to date has identified the following set of competencies useful in creating solutions integrating LLMs:
High-level understanding of the nature of models and everything we know about their operation, both as a result of direct observations and making assumptions with logical justification
Experience resulting from daily work with LLM, conducting conversations, designing instructions, and controlling their behavior
Awareness of the capabilities and limitations of the models themselves and the services offering access to them via API. This includes issues of performance, costs, optimization techniques, and security
Knowledge about techniques for interacting with models, including programmatic (or no-code) integrations where mechanisms supporting the implementation of complex, multi-stage logic are present (e.g., guardrails)
The ability to design databases and organize information from multiple sources, considering their synchronization
Combining LLM with tools via API (generating JSON objects and Function Calling)
Using search engines, including combining different techniques, including similarity search offered by vector databases (e.g., Qdrant)
Programming skills related to working with APIs, including streaming various data formats, queuing requests, and advanced error handling
Agile use of LLM in solving problems and working with new technologies and tools
While developing projects using current AI, I noticed how much experience related to each of the areas mentioned helped me shape the entire solution. Of all the points above, the most crucial turned out to be the last one, which showed me that working hand in hand with AI, I was able to repeatedly exceed my current competencies. I mean here much faster solving of problems related to the still little-known SvelteKit, Rust, or designing solutions in processes related to the aforementioned streaming of various data formats, which were previously unknown to me.
In my daily interaction with LLM, I use my own version of Alice, which has access to long-term memory, making the responses personalized. Questions about programming by default consider the use of the latest version of ECMAScript, and the issued commands perform actions in the applications I use or, thanks to AppleScript, interact directly with my computer. Alice also has information about my experience (e.g., the fact that I am just learning Rust), which she includes in her statements without the need to remind her each time.
Currently, the integration includes a textual knowledge base, which is not yet fully prepared for working with GPT-4 Vision and DALL·E 3 models. However, I have no doubts that a fundamental element of combining different \"senses\" offered by multimodal large language models will be the knowledge base and a set of tools, thanks to which AI will be able to realistically affect our environment, and we will be able to ask about actions, not just answers.