

Searching for LLMs’ Real Value Using Everything I Know
Exploring everything that lies between the copilot concept and autonomous AI agents, and what we can do with it

We can talk to computers, and they understand us quite well, which is impressive. But when we take a closer look, it’s easy to find things that make working together a bit tough. As a result, it's not clear how we can use the available capabilities. Another challenge is that we're discussing things that were beyond our reach until recently, making it sometimes difficult to "connect the dots."

In this post, I aim to reflect openly on the current role of large language models (LLMs) in my daily life and what aspects might still be eluding me. Through this, you'll gain insight into how I collaborate with AI and where my focus lies. You might discover something valuable for yourself in both areas.
Copilot vs Autonomous Agent
In mid-2023, Andrej Karpathy in State of GPT clearly suggested that currently, language models (LLMs) perform better as copilots than as autonomous agents. This is likely to change with the release of GPT-5. However, until that happens, LLMs typically reach their highest effectiveness through collaboration with a human. That's why, for the most part, my computer screen looks like the one below.

At every step, I have a chat window open with LLMs from OpenAI, Perplexity, and a model running locally on my computer. AI is also accessible on my watch, allowing me to speak with LLMs through ElevenLabs and Whisper.

In other words — constant availability is the foundation of my collaboration with AI. And although it is an essential element, it is not the only one. Personalization also comes into play, involving the integration of the model with my own knowledge bases and devices. Ultimately, we get a system that can be classified as something between a "Copilot and an Autonomous Agent". And it is precisely here that there is space to explore what is possible and what still limits us.
Before we go further, I would like to quote Logan from OpenAI, who talks about thinking of AI now in terms of the potential possibilities that GPT-5 (or subsequent versions or alternatives) may offer us. This way, it's easier to go beyond what has so far seemed realistic.

So, illustrating our situation, we will want the interaction with AI not to rely solely on the default available capabilities. Of course, we can still find value in this, but we're talking about something akin to a "demo".

Instead, we will want AI to gain access to our individual context. I mean both information and skills that are necessary for it to become part of our daily life. Specifically, this includes:
the ability to interpret commands within the current conversation
having basic information about us
access to environmental data (location, device status, current activity, weather)
the ability to manage its own memory
the ability to take asynchronous actions
the ability to respond to events and work according to a schedule, as well as proactivity
the ability to use our knowledge base and indicated sources
the ability to use APIs of tools, applications, services, and devices
text, voice, and visual communication
One might think that we are aiming for a result in which AI is able to perform virtually any activity for us.

Experience (and a number of technology limitations, as well as our requirements) suggest to me that in practice we will strive to achieve a type of collaboration in which both we and AI have access to the same areas and complement each other.

Even just looking at the above diagrams, one can notice that we are talking about a complex system. And indeed, in a sense, it is, but it is possible to define certain universal principles and patterns that form the foundation of the entire system's development. It is important to remember both the current limitations and to maintain flexibility resulting from the development of both artificial intelligence and other services and tools.
Taking Actions and Recognizing Intentions
Interaction with an LLM always starts with sending a message, which can come from the user or be sent by the system. Its content must first be verified for potential violations of the terms of service and the scope within which our assistant operates.
Then, further steps must be taken, which may be predetermined by the system. An example could be sending a message containing a description of a task to be added to the list. Then, the model's task is simply to transform the received content so that it can be placed in the task application. After taking action, the model's task is to generate a response informing about the action taken.

So, we are talking about a situation where the LLM in the first stage converts the message into a JSON object describing the task. Then, thanks to automation or programming, this object is sent to the task application's API, which returns a response, the content of which is used to provide an answer.

Such interaction may initially seem attractive, it performs very average in practice because we usually want to perform more than one action. This means that we need to adjust both the behavior of the model and the operation of the other system components to be able to process the entire set of data simultaneously. Then, the message may contain not only information about many tasks to be added but also mention those that should be updated. Ultimately, it also involves immediately querying the assistant about tasks from selected projects, statuses, and date ranges. In other words — we are interested in a free conversation with the model.

Below is a modified version of a conversation, which in this case does not move within the scope of individual entries, but entire lists. Therefore, it can be seen that from a technical point of view, the change is minor. However, looking at it from a usability perspective, we are talking about a chasm. At this stage, one message is transformed by the LLM into an entire series of actions!
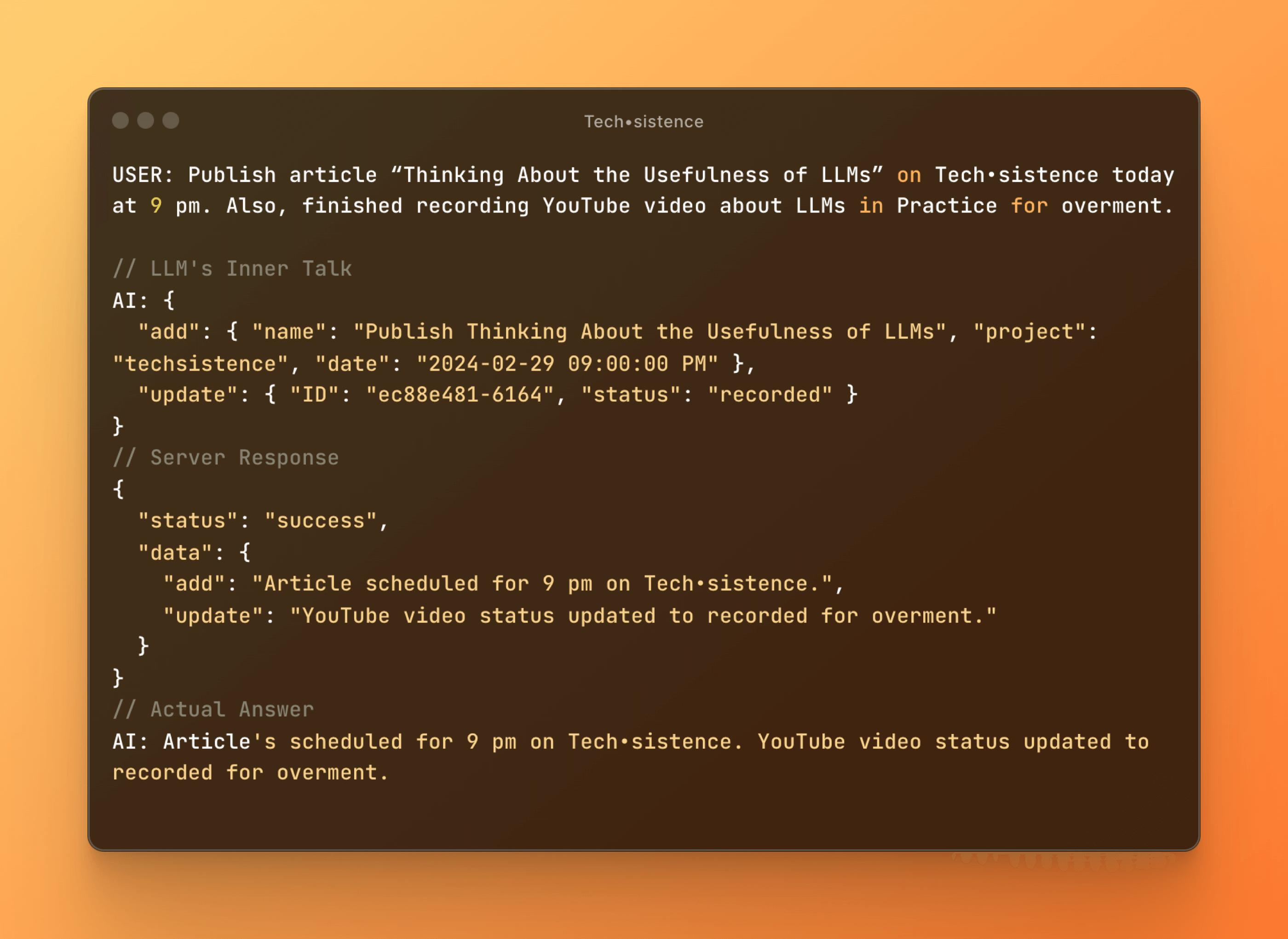
We can now go a step further because on the same principle as action recognition, the selection of a toolset, as well as general planning of actions necessary to complete the assigned task, can also take place.

In this way, we have reached an extremely powerful concept, which can be defined as a single point of entry. Thanks to this, our system is able to react to data coming from various sources and independently decide what to do with them.

In this way, we gain previously unattainable flexibility, but this comes at the cost of predictability and control. Besides, the system in such a form is not complete and will not be able to effectively cope in practice. The reason is that planning actions will require access to various information, including data from external systems.
Context and Action Planning
For simple actions, the information contained in the prompt is completely sufficient. For example, if we want the model to assign us tasks to the appropriate categories, we can describe them and even present a few examples. Such a thing should be entirely sufficient for managing a private list. The situation starts to get complicated when there is more data, or it is dynamic. Then it becomes necessary to load it beforehand so that classification is possible.
At this point, the user's question is first analyzed in terms of information that can be read from long-term memory or external data sources. The information obtained in this way constitutes the context of the query, which we know from RAG systems.
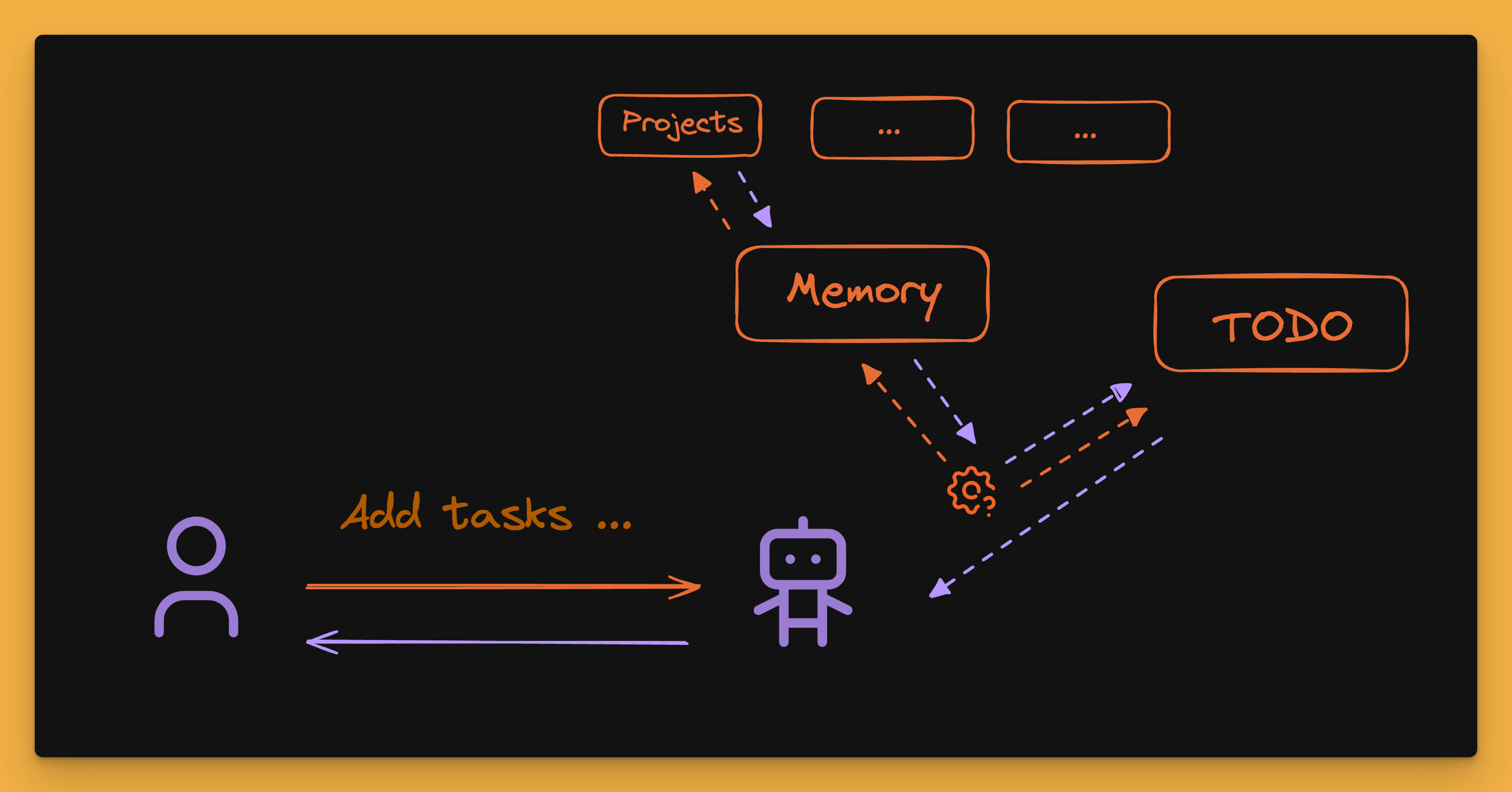
And only after obtaining all the necessary information does the system prepare an actual action plan and undertake the previously discussed steps. However, the user's question alone may be insufficient to correctly find all the information. Therefore, a quite useful technique is self-querying, which involves asking deeper or category-matched questions.

Context gathering will usually depend either on the query itself or on its preliminary classification. The goal is to collect the most useful information possible, which will help in planning further actions.
An essential category of data that will usually need to appear in the context are metadata and identifiers. The former will be responsible for providing context (e.g., the source of origin), and the latter for identifying the entry. Below we have an example where the difference between a calendar event, a task, and individual projects is clearly visible.

Loading the above context enables the correct execution of a command containing a request to mark selected tasks as completed. This is possible because the model will be able to associate the user's query with the retrieved list and send the entry identifier to the API, which is to be modified.
I think at this stage, it is already clear how important it is to properly prepare data and instructions for the model. Their effectiveness translates directly into the operation of the entire system.
Memory Organization, Hybrid Search and Graphs
Despite the increasing context limits, which now even reach one million tokens, the organization of knowledge sources, data formats, and their retrieval methods remains an important topic.
Below, we have an example of a context consisting of the contents of two files. Both contain information about two different people. If their content enters the prompt without any marking, even for a human, it will be difficult to assess whom they concern.

However, the presence of metadata defining the origin of the individual segments is enough for the model to distinguish them from each other and effectively use this data. It is also important that in exactly the same way, the LLM can also indicate the place where a specific piece of information should be saved.
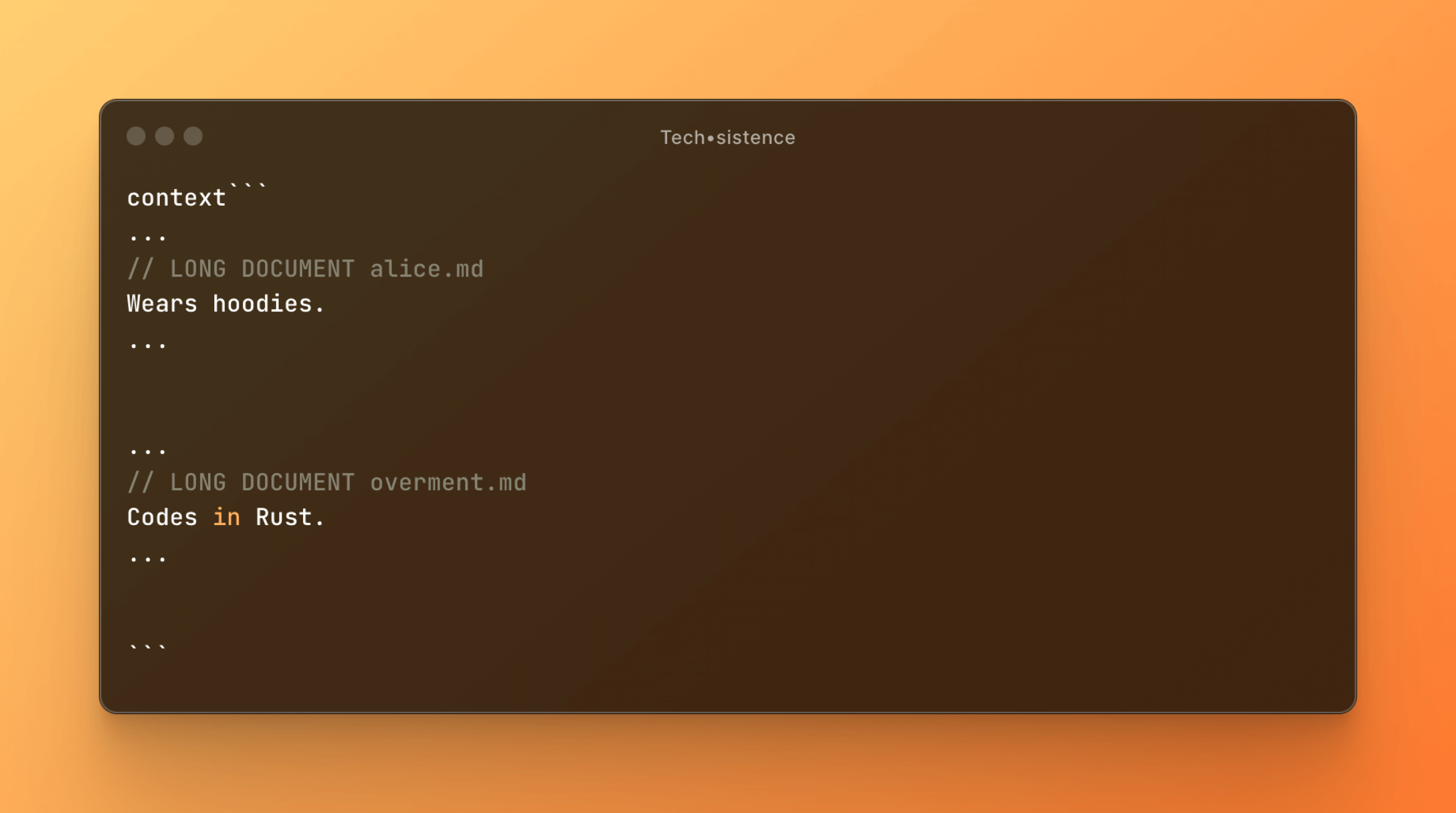
Therefore, assuming that our system will have different areas of its memory, it will also be able to manage them. Additionally, thanks to the ability to transform content, information can be remembered in various forms, depending on the category. We see this below, where information about the residence of two people has been appropriately placed in several memory areas. In addition, the model was able to recognize that the interlocutor is Adam in this case.

If we now combine the previously mentioned concept of loading data at the initial stage, our system will be able not only to save new information but also to update those it already has. For this reason, information about a new place of residence not only reached the indicated place but was also connected with previous knowledge.

However, this is not sufficient because it is enough to mention another person named Greg, and the system will incorrectly link the information. Therefore, additional steps must be taken to avoid such a situation. We can achieve this, for example, by warning the model about cases when it has to ask us for clarification (e.g., which Greg we have in mind). Similarly, the model may have criteria that will help it assess what to remember and what not.
Organizing data must include not only categories but also the previously mentioned metadata, which can be used in the context of the prompt and in the search process. However, it turns out again that this is insufficient. Imagine that during a new conversation, Adam claims that Greg is his best friend. Then this information is recorded in the "People" category, where information about "Adam" is located. Our structure not only expands but also begins to have various complex relationships.

If in such a situation, the message will contain a request to add to the calendar an entry about the birthday of our best friend at his home, then finding the complete set of information begins to be a significant challenge.
Firstly, there is a semantic connection between the words "best buddy" and "best friend". This means that to associate these two pieces of information, we will need a vector base. However, before that, we must ensure that the search takes place in the proper category. After finding information about who is Adam's best friend, it is also necessary to find his place of residence, which was mentioned in the original message.

The result of the above search is finding information about who the mentioned person is and where they live. Based on this, it is possible to add an entry to the calendar about the upcoming birthdays. The connections between individual entries may at some point move us from tree-like structures to graphs, which further increases complexity. However, the good news is that memory management can be entrusted to LLM. And although the whole remains complicated, it does not always have to be so, because usually, we will be interested in smaller structures.
Taking Action
Having a system capable of recognizing incoming instructions, using its own memory and external knowledge sources, and able to plan its actions, we will also need to take care of taking actual actions.
It will probably not be a surprise if we encounter a few additional surprises here, which I have collected in the following points:
Communication takes place via API. Therefore, it is necessary to use tools that provide it.
In the case of API limitations, it is worth considering scenarios in which the system supports the execution of tasks by assigning them to the user.
Performing tasks will usually take from a few seconds to even several dozen minutes. Therefore, it is necessary to include a queuing system, increase the waiting time limit, perform actions in parallel, and often also stream responses to reduce reaction time and positively impact user experience.
Tasks may fail for various reasons. Then, feedback should return to the system, which should be clear enough to be fixed automatically or by user action.
The system should include mechanisms for automatic and manual supervision and verification, as well as input/output control.
LLM should not perform irreversible actions (e.g., deleting data without a saved version history).
Each of the tasks performed should be described by the model, for the purpose of providing a final response.
The system should be designed to be easily updated to the latest model versions, including switching between providers.
The entire system should be monitored (e.g., with the help of LangSmith).
After completing a task, the system can also carry out a series of actions related to self-reflection and updating its state and long-term memory. Each of these actions, depending on the situation, will positively influence future operation.
In this way, we come to a scenario where we have a set of concepts that can be applied at different levels of complexity. Collecting them all together, we are talking about:
Recognizing user intent
A single point of entry
Extending the original query
Supplementing information for the purpose of taking action
Planning actions
Performing a series of actions on external tools
Organizing and using long-term memory
Different categories of activity (active and asynchronous)
Returning responses based on multiple data sources, including reports from actions taken
Translating this into practice, we can design both simple tools and quite complex systems based on this. Here are a few examples:
Content transformation tools (e.g., translation and correction)
Content organization tools
Content enrichment tools
Research tools
Documentation management tools
Process supervision tools
Reporting tools
Monitoring tools
Content verification and moderation tools
Systems combining various data sources
"Second Brain" type systems and corporate knowledge bases
Systems that help in acquiring new skills
Systems that act as assistants, equipped with memory and a set of tools
And finally, with appropriately designed tools or systems, their combination also comes into play, which opens up space for performing complex tasks autonomously. And although it is currently difficult to speak of high effectiveness of such solutions, probably in combination with GPT-5, the results achieved will meet our expectations and often surprise us.
Have fun,
Adam